2024年4月11日~2024年5月24日
このブログを公開することに伴うセキュリティへの影響
もし誰にも公開することがないプログラミング開発の過程を残すならこうやってブログに残すのは問題ないと思う。
しかし、将来的にサービスを運営しようとしており、しかも個人情報を多少なりとも扱うサービスであれば、こうやってブログに残すべきでないと今更ながら気づいた。
理想は、「考え、フロントエンド、一般的な困りごと」の部分は残し、バックエンドの具体的な実装は消すという感じだよね。
しかし、過去から今までの投稿を全て合わせると数十万文字になってしまう。
というか今回の25日目でさえ下書き状態だと十数万ある。
この文字数を全て見直してどれがセキュリティ的に影響ある・ないを判断するのはかなり面倒、というか基本的にどんな些細なものでも情報はセキュリティに影響あるんだけどね。
とにかく、12日目以降を非公開にするのが無難かなという判断で一旦非公開に。
今回の25日目はセキュリティ的に問題なさそうな部分だけ切り抜く。
IPアドレスの取得方法は$request->ip();で問題ないか
レート制限などでも使われている「$request->ip()」なんだけど、もしかしたらこれだと直前のサーバーからのIPしか受け取れないかもしれない。
ソースは以下
調べた結果をめっちゃ簡潔にまとめると、$request->ip();で取得した場合はREMOTE_ADDRという自サーバーが直接通信しあったIPのアドレスを取得できる。
つまり、VPNやロードバランサーなどの仲介サーバーを使って通信した場合はそのIPアドレスを取得する。
逆に、$request->ips();というのはX-Forwarded-Forという今まで通ってきたサーバーのIPアドレス履歴みたいなものの配列を受け取れる。日本語ドキュメントでは「「元の」クライアントIPアドレスは配列の最後になります。」とあるので、配列の最後を見れば大元のアクセスIPがわかるんだけど、この値は改ざんできる。
原理を考えるとわかるんだけど、HTTPの仕組み上通信するにはお互いのIPアドレスを知る必要がある。だから、直前のIPアドレスは実在するものじゃないとそもそも通信できないし、そこと通信した事実は改ざんできないので$request->ip();で取得したIPはよっぽどのことが無い限り信頼できる。
しかし、1つでもサーバーを介してしまうとX-Forwarded-ForにあるIPの履歴は直前のもの以外は改ざんしていても正誤の判断が自サーバーからは判断できない。もちろん、直前のIPにあるサーバーの履歴を見ることを芋づる式にすれば本来のIPアドレスはわかるが、そもそも第三者のサーバーだし例えばVPNのサーバーがそんな個人情報を教えてくれる訳は無い。
結論としては、確かに$request->ip();だと仲介サーバーなどのIPをBANしてしまう可能性があるが、だからといってX-Forwarded-Forは信頼できないので$request->ip();で妥協する必要がありそう。
もし、ロードバランサーなど信頼できるサーバー、自分で作ったサーバーを介する場合は信頼するプロキシの設定をすれば良さそう。さっき言った芋づる式で直前のIPは信頼できることを利用するのかな?
Cookieの承認について調べる
よくWebサイトにアクセスすると「Cookieを承認しますか?」みたいなのが出てくるよね。
このサイトでもCookieを使ってないわけないので、そこら辺を調べる。
「最近よく見かけるCookie同意バナーは必要?ホームページへの設置義務があるの?」というページを見た感じ、EUをサービス対象にするならGDPRというルール的にCookieの同意を得る必要があるっぽい。
また、GDPRルールが無い日本の場合必須ではない。
なるほど、だからQiitaもNoteも求められないけどSoundCloudは同意を求められるのか。
とりあえず利用規約に利用意図を書いとくぐらいはした方がよさそう。
限定公開は電気通信事業法に抵触しないか
良いウェブサービスを支える「利用規約」の作り方の第2版をみてたんだけど、ちょこっとだけ電気通信事業法について触れていた。
どうやら、クローズなチャットなどを提供する場合は電気通信事業届を出し、電気通信事業者にならなきゃ法律違反っぽい。
ここらへんは総務省の「電気通信事業参入マニュアル[追補版]」及び「電気通信事業参入マニュアル(追補版)ガイドブック」の改定とかを見ていただくのが確実でよいと思う。
特に、電気通信事業 参入マニュアルが図解されていてわかりやすい。
今のところ私のサイトにはチャットもコメントもなにもないんだけど、記事の限定公開がこれに当てはまる可能性がありそうでちょっと怖いので調べる。
以下はすべて総務省の電気通信事業 参入マニュアルを参照したもの。
電気通信事業に該当するかのフローがあるっぽいので、私のサイトに当てはめてやってみる。
まず、電気通信事業を営む者かの判断。
-
他人のために役務を提供していますか?
YES -
電気通信設備を用いてサービスを提供していますか?
サーバー使うのでYES -
その電気通信設備を使ったサービスの提供を反復継続してますか?
YES -
利益を得ようとしていますか?
いずれ広告付けるつもりなのでYES
全てYESなら電気通信事業を営む者に該当
次に電気通信事業法が適用されるか
- 顧客に電気通信役務を提供することがなければ成り立たないか
電子的な記事を書くサイトなのでYES
YESなら電気通信事業法が適用される。
次は、『登録・届出』が必要か
-
電気通信回線設備を設置していますか?
回線の利用はしてるけど、流石に設置はしてないよね? オンプレ環境だと該当すんのかな。
NO -
他人の通信を媒介していますか?
ここが大事
恐らく、一般的な個人Webサービス提供者はこの「他人の通信を媒介」するか否かで届出が必要かが変わってくる。
この「他人の通信を媒介」の定義なんだけど、以下の2つがともに該当する物を指す
-
加工・編集を行わない
-
送信時の通信の宛先として受信者を指定している
つまり、一般的なチャットはメッセージを加工せずに特定の者に対してのみそのまま送信するので媒介に該当する。
今回の私のサービスの場合、宛先を指定した送信を行わないので媒介には該当しない。
また、加工・編集はファイルの基準なんだけど、ファイルの圧縮程度なら該当しないらしい。ここら辺は問い合わせるのが一番だと思われる。
また、月間アクティブ利用者数が平均1000万を超えると媒介してなくても届出が必要になることがあるみたい。流石に関係ないね。
とにかく、私のいまのサイトであれば要らない。
しかし、記事に対するコメント機能を付けたら解釈によっては電気通信事業の届出が必要そう。
記事に対するコメントを「宛先のある送信」とするか否かがちょっとわからなかった。
テストの確認(Duskは必要そうならでおk)
1テストにつき、1リクエストまで
1テストあたり、1リクエストにしないとバグることが結構前に判明した。そこからはできる限り1テストに1リクエストを守ってるんだけど、過去のテストは修正できていないので、とっっても面倒なんだけど頑張る。
->(post|get|put|patch|delete)\(という正規表現でリクエストが1テストの2個以上あるところを探す。
うーん。Laravelの拡張パッケージみたいのに初期からあるテストの中に2個リクエストあったりするなぁ。
前、10個を超えたあたりでバグったりしたので数個程度ならいいのかなぁ。
でも、Laravel10の公式ドキュメントでも相変わらず
In general, each of your tests should only make one request to your application. Unexpected behavior may occur if multiple requests are executed within a single test method.
ってあるんだよね。
難しいところ。
とりあえず、リクエストが3つ以上あるものが何個かあったのでそれだけ直し、後は様子を見る。
Duskでよりリアルなテストを作る
今までのテストはサーバーで完結していた模擬的なものだった。
しかしこれだとJavaScriptの動きとかHTMLやCSSなどのフロント側のテストがしっかりできない。
そこで、Laravel Duskというツールを使う。
日本語ドキュメント。
このDuskの仕組みはしっかりわかってないんだけど、恐らくブラウザを立ち上げて自動で動かしてテストしてくれるBotみたいな感じ。
だから、実際に私たちがサイトを閲覧したときと同じようなテストができる。
とりあえず最低限、Alpine.jsで作ったJavaScriptのテストだけでも作成しようかなと思うんだけど、負担だったらやめる。
Duskが使えるようになるまで
まず
composer require laravel/dusk —dev
でduskをダウンロード。
本番環境にインストールすると、無認証でアクセスできるようになってしまうらしいので注意。
次に
php artisan dusk:install
でlaravelにインストール。
次に
php artisan dusk:chrome-driver
で自分のOSに合った最新のChromeドライバをインストールし
chmod -R 0755 vendor/laravel/dusk/bin
で権限を設定。
次にCentOSにGoogleChromeをインストール
vi /etc/yum.repos.d/google.chrome.repo
でリポジトリにオリジナルのリポジトリを追加する。
内容は以下
[google-chrome]
name=google-chrome
baseurl=http://dl.google.com/linux/chrome/rpm/stable/$basearch
enabled=1
gpgcheck=1
gpgkey=https://dl-ssl.google.com/linux/linux_signing_key.pubdnfの設定ファイルってこんな感じになってたんだね。
内容を詳しく理解したい場合は「8.4. Yum と Yum リポジトリーの設定」を見るのが良さげ。
dnf update
で反映
dnf install google-chrome-stable
で安定版をダウンロード。
次に、.envのAPP_URLに実際にDuskを実行するブラウザからアクセスできるURLを入れる。
これで恐らく準備完了。
早速テストを作ってみよう。
php artisan dusk:make view/layouts/navigationTest
などでテストを作成。
一回、ナビバーのログインボタンと新規登録ボタンがゲスト時に表示されるかのテストを行う。
まず、ログインボタン等の検証したい部品に
dusk="login-button"
のようなduskセレクタを付け、以下のようなテストを作る。
public function testゲスト時、ログインと新規登録ボタンが出てくる(): void
{
$this->assertGuest();
$this->browse(function (Browser $browser) {
$browser->visit(route("article.index"));
$browser->assertVisible("@login-button")
->assertVisible("@register-button");
});
}作成したら
php artisan dusk

なんかダメだった。
tests/Browser/screenshotsを見ると

確かに。
apacheのIP制限やローカルホスト的にこのままだと自サーバーへアクセスは無理か。
Apacheの設定やLinuxでのローカルホスト設定をしてきた。

おk。
Duskを使う際のDBについて
私の場合、普通のテストはテスト用のDBを作り、テストごとに「use RefreshDatabase;」してまっさらな状態でテストしている。
これは、他のデータの影響でテスト結果に揺れを出さないようにする為。
しかしDuskの場合、RefreshDatabaseを使わないでくださいとある。
代わりに、DatabaseMigrationsかDatabaseTruncationの利用が推奨されている。
どうやらテスト数が増えるとDatabaseTruncationの方が早いらしいのでDatabaseTruncationでの構築をしていく。
まず、
composer require —dev doctrine/dbal
でdoctrine/dbalを入れる。私は—devなしで既に入っていたのでパス。
そしたらRefreshDatabaseと同じように「use DatabaseTruncation;」を入れればいいんだけど、このまま入れて使うとDBがすっからかんになる。
これは、テスト用DBを指定してないから。
私は無事すっからかんになった。
その為、Dusk利用時にもDBを指定する。
「【Laravel】Laravel Dusk時に使用される .env ファイル」というサイトによると、Duskは「.env.dusk.{environment}」というenvファイルを参照し、無ければコピーして作成しているらしい。
つまり、.env.dusk.localを先に作っておけばDBは指定できる。
.envをコピーして作るので勿論、.env.dusk.localはgitignore対象。
「 Target class [env] does not exist.」エラー
試しにfactoryを使ってみると Target class [env] does not exist.というエラーに遭遇。
色々調べるとこちらのissueに辿り着いた。どうやらTelescopeとduskの兼ね合いでエラーになってるみたい。
TelescopeのServiceProviderの
if ($this->app->environment('local')) {
return true;
}の部分で.envを取得しようとしてできなくてエラーになってる。
テストではTelescopeを使わないのでテスト用の.envに
TELESCOPE_ENABLED=falseを適用すればおk。
テストでTelescopeを使いたいなら先述したサービスプロバイダの部分を弄る必要あり。
【追記】Duskではなく普通のテストでこのエラーに遭遇。エラー理由は同じくtelescope。「composer dump-autoload」で治った。理由がわからん。
DuskにもCSSを適用する
$browser->screenshot(‘撮った写真の保存名’);
でスクリーンショットを撮れるんだけど、撮ってみると以下の通り
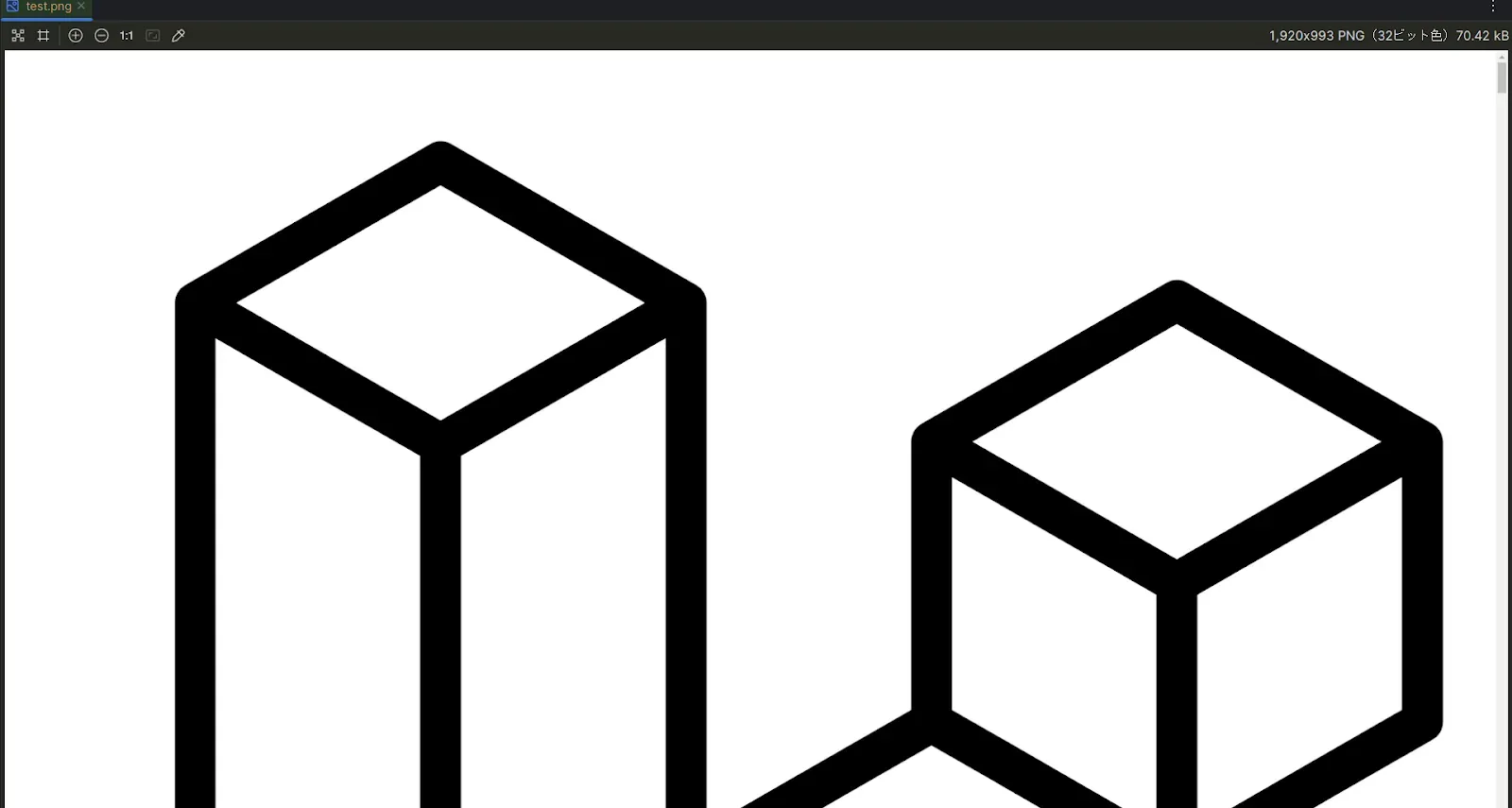
CSSが適用されていない。
なんでかっていうと、npm run devで建てたサーバーは共有フォルダの都合上ホスト側にあるから。
その為、どうにかVMからホストサーバーにアクセスしたいんだけど、「Viteで起動したローカル開発サーバーにIPアドレスで外部からアクセスする方法」にもある通り、初期では基本ローカルホストしかアクセスできないようになっている。
一応設定すれば外部からアクセスできるようにできるんだけど、外部からアクセスできるようにすると同じネットワークに接続している人なら誰でもアクセスできちゃうので、セキュリティ的によろしくない。
でも、VMならホストオンリーネットワークがあるのでこれ経由でアクセスすればいけるのでは。
vite.config.jsのhost:をホストオンリーネットワークのIPにして、ホスト側でnpm run devする。
すると、以下のようにCSSが適用されている。なぜか画面が横に長い。
一応、ホストオンリーネットワークとか面倒だよって人はnpm run buildして静的ファイルにすればCSSは適用される。
プライバシーポリシー、利用規約を作る
今、私のサイトにはプライバシーポリシーも利用規約もないので作成する。
この利用規約とプライバシーポリシーの主な目的は、サイトを守るため。
ルールを予め決めておいて、それにお互い準拠することで秩序に繋げたいという感じ。
このルールはサイト運営側もユーザーも守る必要が出てくる大事なものになる。
作成には「良いウェブサービスを支える「利用規約」の作り方」の第2版(現在は第3版がある)や似たサイトの規約などを参考に作成する。
その為、利用規約とプライバシーポリシーに対する考え方などは本や別のサイトを参考にしてもらうのが良いと思う。
ここでは、やったことや考えたことを残す。
やることを箇条書きにする
-
利用規約を作成する
-
プライバシーポリシーを作成する
-
利用規約とプライバシーポリシーの履歴を管理できるようにする
-
利用規約とプライバシーポリシーをアカウント作成時に読んでもらう仕組みにし、同意を得る
- 規約リンク×規約同意クリックか規約全文表示×規約同意クリックが無難
-
利用規約とプライバシーポリシーをフッターに置く
利用規約とプライバシーポリシーの作成は前述した通り、既存サービスや本を参考に作成する。
これらの履歴管理なんだけど、普通にLaravelプロジェクト内に利用規約とプライバシーポリシーを共に作っちゃって管理するのでいいんじゃないかな。
利用規約を考える
全然進まない。
Noteの利用規約が綺麗で、わかりやすく、素晴らしい。
複数アカウントは是か
Qiitaでは複数アカウントを禁止しているみたい。
理由はわからないけど、
-
いいねのかさ増し
-
荒らし・スパム
などを考えると妥当なのかなぁと思う。
私としては、アカウントは複数あって問題ないと思っている。
しかし、上に挙げたような行為をされるのは困るなぁといったところ。
仕事で音楽する人もいるだろうし、仕事とプライベートでアカウントを分けたい気持ちはとてもわかるんだよね。
うーん。
でも利用規約を後から変えられることを考えると、とりあえず複数アカウント禁止にした方が柔軟性はあるよね。
わかった。私のサイトではシンプルさと管理容易さを重視して、複数アカウントを禁止にする。
もし、問題なさそうであれば後から利用規約を変更する。
サイトの領域をDTMにするか
ここ、結構大事なところだと思っている。
つまり、私のサイトの守備領域を「DTM」という狭い範囲にするのか、「クリエイター」や「音楽」などの広い範囲にするのか。
正直、答えは決まってるんだけど、意思表示も兼ねてまとめる。
経営学の授業で学んだ話をひとつ。
昔、ある鉄道会社が事業領域を「鉄道事業」と定めていた。
最初は良かったが、時代が進むと共に飛行機や車など、輸送の多様化が進んだ。
それでもこの鉄道会社は事業領域を「鉄道事業」と定めていた。
その結果、鉄道ではない輸送手段に無関心だった鉄道会社は他の輸送手段に負けてしまうみたいな話。
それくらい事業領域を定義すること、変化に対応するのは大事だよねという話だと思っている。
その上で、今回の場合の「輸送事業」は「クリエイター」とか「音楽」なのかなぁと思う。
でも、私の12日目の日記タイトル「QiitaのDTM版を作りたい」を見ればわかる通り私はDTMの為に作ってるという前提がある。
また、クリエイターが範囲だとNoteと被るし、DTM特化の強みが出てこない。
更に言えば、クリエイターとか音楽だと範囲が広すぎて一人じゃカバーしきれない。
だから、私はDTM/作曲をサイトの守備範囲にする。
分かりやすく言えば、「音楽を作る事に関する知識を共有するサイト」といったところだろうか。
禁止事項をどう決めるか
正直、「一般的に考えてダメなものはダメ。それ以外はおk」という緩い規約を付けたいところなんだけど、人によってダメの基準が違うという当たり前の現実があるので、禁止事項を定める。
また、ユーザーと登録してくれたユーザーの区別が面倒。登録ユーザーをメインに話せばいい気がするんだけど、それだとゲストユーザーは何してもいいのか? っていう話になりそう。
で、あればユーザー全員に禁止事項を指定する方がいいかなぁ。
規約の分かりにくさがUPするんだけど、しょうがない気もする。
後から変えられるのでとりあえずユーザー全体の禁止事項・利用規約ということにする。
また、長いと私もユーザーも大変なので、出来るだけコンパクトにしたい。
禁止事項をジャンル分けする
色んな規約見てジャンル分けしてみる
-
法的にやっちゃだめ系
-
知的財産権の侵害
-
権利系の侵害
-
詐欺
-
-
社会的にやっちゃだめ系
-
差別
-
なりすまし
-
迷惑行為
-
サブリミナル効果
-
宗教勧誘
-
マルチ商法
-
-
サービスの性質上やっちゃだめ系
-
複数アカウントの作成
-
アカウントの共有
-
宣伝・広告
-
サービスの目的に則った投稿
-
出会いはダメ
-
勿論、複数に属する禁止事項もあるけど、大体こんな感じ。
つまり、法的禁止>社会的禁止>サービス的禁止の3つの禁止がありそう。
なぜわざわざ法的禁止事項も記すのかなんだけど、明示的にしておくことで法に遵守してますよアピールとか、利用規約に示しておくことでどんな国でもそれを盾に戦えるとかかな。
これを上手く利用規約に落とし込んでいるのがQiitaの第11条で、
-
Qiitaを利用する上での禁止・遵守事項
-
Qiitaを利用する上での法的禁止事項
-
Qiitaを利用する上での社会的禁止事項
を定めている。
こうやって項で分けてくれた方がわかりやすいし管理しやすそうなので、わたしもこうする。
宣伝広告や販売を主目的とする投稿は是か
これ、つまり「〇月〇日に△△をリリースします!」みたいな投稿を許すかどうか。
知識の共有であるか否かに当てはめるともちろん否で、投稿しちゃダメ。
Qiitaでもこの禁止事項を定めてるんだけど、個人開発のリリース記事とかあるんだよね。
では、なぜ個人開発のリリース記事が良いのかというと、個人開発のサービス宣伝が主目的ではないと判断されているからだと思う。
つまり、リリースまでの過程の知識を共有していればセーフという感じなのでは。
私のサイトでも同じようにリリースのみの宣伝とかはダメだけど、その過程で得られた知識とかの共有が主であると判断出来たらありでいいかな。
勿論、このプラグインはこういう使い方ができます! いいよね! みたいな投稿は全然あり。
つまり、作曲知識の共有が主目的と判断できればあり。
ユーザー投稿コンテンツの権利について考える
Youtubeの例
あんまり意識したことないかもだけど、著作物を何かのサービスにアップロードする以上かならず権利関係の問題が出てくる。
例えばYoutubeでは動画一覧画面でサムネの右下に動画の秒数が出てくると思う。
別になんてないことなんだけど、著作物のサムネイルに秒数の表示を無断で追加している、つまりあれは著作物であるサムネイルの改変と言える。
じゃあ、Youtubeは何故訴えられないかというと以下のような利用規約を定めているから
本サービスにコンテンツを提供することにより、お客様は YouTube に対して、本サービスならびに YouTube(とその承継人および関係会社)の事業に関連して当該コンテンツを使用(複製、配信、派生的著作物の作成、展示および上演を含みます)するための世界的、非独占的、サブライセンスおよび譲渡可能な無償ライセンスを付与するものとします。これには、本サービスの一部または全部を宣伝または再配布することを目的とした使用も含まれます。
つまり、Youtubeに投稿したコンテンツは世界的に、非独占的に、譲渡可能な無償ライセンスとしてYoutubeに渡されるということ。
これは、著作権の譲渡ではなく、著作物の利用許諾をYoutubeにしている感じ。
だから、Youtubeはアップロードされた動画をある程度自由に使える。
これはYoutubeに限ったことじゃなくかなりのユーザー投稿型のサイトでこのような規約になっている。
私のサイトはどうするべきだろうか。
私のサイトのユーザー投稿コンテンツの権利はどうするか
サイトが取れる姿勢は以下の通り
-
最低限の利用許諾を得るパターン
-
無制限に利用する許諾をとるパターン
-
著作権を譲渡してもらうパターン
3番は流石に権限が強すぎるので論外として、1番か2番か。
さっきのYoutubeは2番目のパターン。
2番の利点は、自由度が高く安心して運営できること。
だから、2番が多い。
1番目の最低限の利用許諾を得るパターンだと、何か新しい仕組みを実装したいとき、最低限の利用許諾だけだとダメだったりする可能性はあるよね。
また、許諾漏れとかがある可能性があるのも怖い。つまり、法にある程度詳しくないとつらい。
Noteの規約がすごい
ここで参考にしたいのがNote。
Noteは私の見逃しが無い限り、1番の最低限の利用許諾を得るパターンで運営している。
実際の利用許諾の一部が以下の通り
当社は、本サービス内でのインデキシングの最適化を目的として、クリエイターがアップロードしたデジタルコンテンツの一部(原則としてタイトルおよびトップページ)を、本サービスが設定する表示アルゴリズムに基づいて変更、切除その他の改変をすることがあります。なお、表示アルゴリズムは、当社の判断に基づき変更することがあります。
(https://note.com/terms#general_terms)2024年4月23日閲覧
とか、
当社は、デジタルコンテンツ、ユーザー情報、行動履歴等を統計的処理や機械学習などの手法で解析し、リコメンド等のプロモーションに利用することがあります。
(https://note.com/terms#general_terms)2024年4月23日閲覧
とか。
1番の最低限の利用許諾を得るパターンだと、こんな感じでどのような用途で著作物を利用するのかを網羅して書く必要がある(たぶん)。
それは当然なんだけど、法的に怖くてできないことを平然としている感じ。しかも全体的に。
Noteすごい。Noteの利用規約マジですごい。
他にも、
- 本利用規約への同意
本サービスの利用申込みと登録に当たっては、本利用規約に同意していただくことが必要です。
ゲストユーザーは、クリエイターのデジタルコンテンツを購入する場合、本利用規約に同意していただくことが必要です。
(https://note.com/terms#general_terms)2024年4月23日閲覧
これのゲストユーザーの項目とかすごい。
なんか規約はすべてみたいな感じがしてしまうので、ゲストユーザーも規約に同意させなきゃいけない感じがしちゃうんだけど、それをしようとすると非ログインユーザーはアクセスするたび利用規約を読ませるような仕様にしないと恐らく意味がないに等しい。
だから、ゲストユーザーの規約は作ってないんだと思う。
ゲストユーザーができる規約違反な事ってDoSとかだから、それって規約違反とかじゃなく法で裁かれるべきものなんだよね。だから作るまでも無いということなのではと思っている。
そもそも、利用規約を作る意味を考えたとき、Webサイトを守る為という考えがある。
これ、何から守るかっていうとユーザーとの争いからも守るんだよね。
予め禁止事項を定めることで、ユーザー方に納得していただけるし、運営も規約を指標に運営できる。
で、あれば識別もできなく、Webサイトの閲覧しかできないゲストユーザーの利用規約は要らないともいえる。
私もこの利用規約を見習いたいところなんだけど、ちょっと高度すぎて厳しめ。
私はユーザーコンテンツの権利の何を侵害するか
もし、最低限の許諾を得ようとすると、ユーザーコンテンツで何をするかを列挙しなきゃいけない。
例えばNoteのユーザーコンテンツの例だと
-
インデキシングの為のタイトル、トップページの改変権利
-
機械学習・統計的分析する権利
-
PR目的の無償公開権利
-
PR目的の外部公開権利
-
アフィリエイトID設定してなかったらNoteのIDを設定して良い権利
-
オートリンク、公正機能の適用権利
-
18禁判定できる権利
-
みんなのフォトギャラリーに投稿した画像を許諾の範囲で公開する権利
-
アップロードされたコンテンツを有料無料問わず確認する権利
を有している。
勿論これは私が勝手にまとめたもので漏れがあるかもだし、現時点での規約だからnoteを使う時はNoteの規約を自分で確認してね。
結構攻めるなぁと思ったのはアフィリエイトとかかなぁ。合理的だけどすごいねそれ。
意外だと思ったのが、メディアファイルの改変についての記述が無い事。
恐らく画像や音源などのメディアファイルを投稿するとき、圧縮とかリサイズとか拡張子の変更とか色々してると思うんだけどそれについての記述が無いんだよね。
法的に問われるかはわかんないんだけど、著作物の改変にあたるよね?
というかそこらへんの知識がないと安易に「最低限の利用許諾を得るパターン」って適用できないんだなこれ。
うーん。「無制限に利用する許諾をとるパターン」から「最低限の利用許諾を得るパターン」には利用規約の変更はできるけど、その逆は難しいと思うからとりあえず逃げで私も無制限に利用する許諾をとるパターンにしようかなと思う。
プライバシーポリシーを考える
利用規約はユーザーと運営側でルールを作り、お互いそれを守ることで秩序を作ろうという意図があったわけだけど、プライバシーポリシーは何のためにあるのだろうか。
普通に考えて個人情報保護法などが無くても私たちは積極的に個人情報を出そうとはしない。
そもそも出して得がないし、個人情報を知った第三者に何されるかわかんないし。
だから私含むサービス提供者は個人情報を取得する以上、ポリシーを作りそれに則って扱う必要がある。
また、CookieでもやったけどEUでサービス展開するならGDPRを守る必要あり。
個人情報の定義
個人情報保護委員会の「個人情報」「個人データ」「保有個人データ」とは、どのようなものですか。によると
「個人情報」とは、生存する個人に関する情報であって、当該情報に含まれる氏名、生年月日、その他の記述等により特定の個人を識別することができるもの(他の情報と容易に照合することができ、それにより特定の個人を識別することができることとなるものを含む。)、又は個人識別符号が含まれるものをいいます。
とのこと。
本サイトの場合、メールアドレスは個人情報に該当する可能性がある。
メールアドレスと他サービスのメールアドレス情報を照合することで、サイトを使っている個人を絞れる可能性があるし、メールアドレスのドメインや名前で個人を絞れる可能性があるから。
個人情報保護法
では、個人情報保護法はどんなものなのだろうか。
ここでは政府広報オンラインの「個人情報保護法」をわかりやすく解説 個人情報の取扱いルールとは?というサイトを参考にする。
私が勝手にまとめているので、間違っている可能性あり。
自己責任で読んでください。
個人情報保護法は以下の4つの基本ルールがある
-
個人情報の取得・利用
-
どのような目的で使うかを公表する義務
-
違法、不当な行為に利用しちゃだめ
-
要配慮個人情報の取得は同意が必要
-
利用目的の範囲で使う必要
-
利用目的の範囲外で使う時は同意が必要など
-
-
個人データの保管・管理
-
漏洩などが生じないようにする必要
-
漏洩等が発生した場合、個人情報保護委員会に報告し、本人に通知する必要など
-
-
個人データの第三者に提供
-
データを第三者に提供するときは、本人の同意が必要
-
法令に基づく場合など、例外の場合は不要
-
外国に提供する場合は更に色々必要など
-
-
本人からの保有個人データ開示
-
本人からの請求があった場合、データの開示、修正、利用停止に対応する必要
-
苦情を受けたときは、適切に迅速に対応する必要
-
以下の内容についてサイト上などで公表する必要
-
個人情報取扱事業者の氏名又は名称、住所
-
全ての保有個人データの利用目的
-
保有個人データの利用目的の通知の求め又は開示などの請求手続
-
保有個人データの安全管理のために講じた措置
-
保有個人データの取扱いに関する苦情の申出先
-
-
第三者に個人データを提供した記録も開示対象
-
電子データなどによる提供を含め、本人が請求した方法で開示に対応する必要など
-
つまり、個人情報を扱う以上、私はこの4つのルールを守る必要がある。
個人情報取扱事業者の氏名又は名称、住所を公表する必要というのに少しびびるんだけど、これは個人情報取扱事業者に該当しなければ必要はない。
総務省の個人情報取扱事業者の責務によると、
「個人情報取扱事業者」とは、個人情報保護法第2条第5項において、「個人情報データベースなどを事業の用に供している者」と定義されています。また、「個人情報」とは、生存する個人に関する情報のことで、氏名、生年月日などのデータによって特定の個人を識別できる情報、または個人識別符号(※)を含む情報のことを指しています。
とのこと。
じゃあ、usersテーブルが個人情報データベースに該当するかが大事になりそう。
usersテーブルは個人情報データベースに該当するか
私のusersテーブルは大体以下のようになっている
| 一意の自動付与id |
| 一意の任意の名前(変更不可) |
| 一意でない任意の名前 |
| メールアドレス |
| パスワード |
だいたいね。
そして、個人情報データベースとは個人情報保護委員会の「個人情報データベース等」とは何か。によると
「個人情報データベース等」とは、個人情報を含む情報の集合物であって、
① 特定の個人情報をコンピュータを用いて検索できるように体系的に構成したもの、又は
② コンピュータを用いていない場合であっても、五十音順に索引を付して並べられた顧客カード等、個人情報を一定の規則に従って整理することにより特定の個人情報を容易に検索することができるよう体系的に構成したものであって、目次、索引、符号等により一般的に容易に検索可能な状態に置かれているもの
をいいます(個人情報保護法第 16 条第1項、通則ガイドライン 2-4)。
とのこと。
うーん。じゃあ、メールアドレスや任意の名前が個人情報に該当する場合、私は個人情報データベースを扱う個人情報取扱事業者に該当して、氏名又は名称、住所を公開する必要があるのか。
つら。私の個人情報保護はどうなってんだ。
メールアドレスと任意の名前は個人情報に該当するのか
もし、個人情報に該当するならかなーり面倒なんだけど……うん。
結論から言えば、該当する場合がある。
個人情報保護委員会のメールアドレスだけでも個人情報に該当しますか。にある通り、メールアドレスでもユーザー名及びドメイン名から個人が識別できる場合個人情報になる。であれば任意の名前も同じことが言えそう。
つまり、ユーザーの入力した値によって個人情報か否かが変わる。
すなわち、このサイトのusersテーブルは個人情報データベースに該当し、私は個人情報取扱事業者に該当し、氏名又は名称、住所を公開する必要がある。
本当に氏名又は名称、住所を公開するのか
これ、本当に公表義務あるのか? 義務じゃないのに公表してたらつらいので、調べる。
個人情報保護委員会の個人情報の保護に関する法律についてのガイドライン(通則編)が良さそう。令和5年12月に改正もされているので情報が新しく信頼できる。
法第32条(第1項)がその個人情報取扱事業者が氏名又は名称及び住所を公表するか否かの鍵になりそう。
個人情報保護委員会にある法第32条(第1項)を私が解釈すると、
-
個人情報取扱事業者は氏名又は名称及び住所を本人の知り得る状態に置かなければならない
-
本人の知り得る状態は、本人の求めに応じて遅滞なく回答する場合も含む
とのこと。
つまり、義務はあるが本人の求めに応じて遅滞なく回答すれば問題ないということ。
すなわち、Webサイト上での公表まではしなくて良さそう。
その代わり、個人情報取扱についての苦情や開示の請求に遅滞なく応じる環境を整える必要がありそう。
お問い合わせ窓口を用意する
政令第10条で「当該個人情報取扱事業者が行う保有個人データの取扱いに関する苦情の申出先」を本人が知り得る状態にしないといけないとあるので、作る。
開示とか質問とかもあると思うので、それも一元管理で良いと思う。
果たしてこのサービスで何を開示するのかというのはあるが。
このサイト内でお問い合わせを受け付けても問題ないんだけど、サイトが落ちてたりしたら受付できないので、無難にメールに頼るのが良いのかな。
あと、開示請求されたときなんだけど、本人確認や法的にどこまで開示義務があるのかを予め考えておいた方が良い。
ポリシーが完成したら、設置する
とりあえず、プライバシーポリシーと利用規約ができたので、これを設置する。
また、ただ置いただけでは意味がないのでユーザー登録時にチェックボックスで同意を得るようにする。
フッターを作り、設置する
良くある感じで、下に利用規約とプライバシーポリシーのリンクを置いて、ついでにコピーライトも置く。
といっても、メニューバーと同じでフッターをレイアウトで作って読み込めばよさそう。
以下のようにした。

©でコピーライトマークの記述が可能。
アカウントを作成時に同意を取る
どう同意をとるかというのは考慮の余地があるんだけど、今回は規約リンクの横にチェックボックスを配置する形にした。
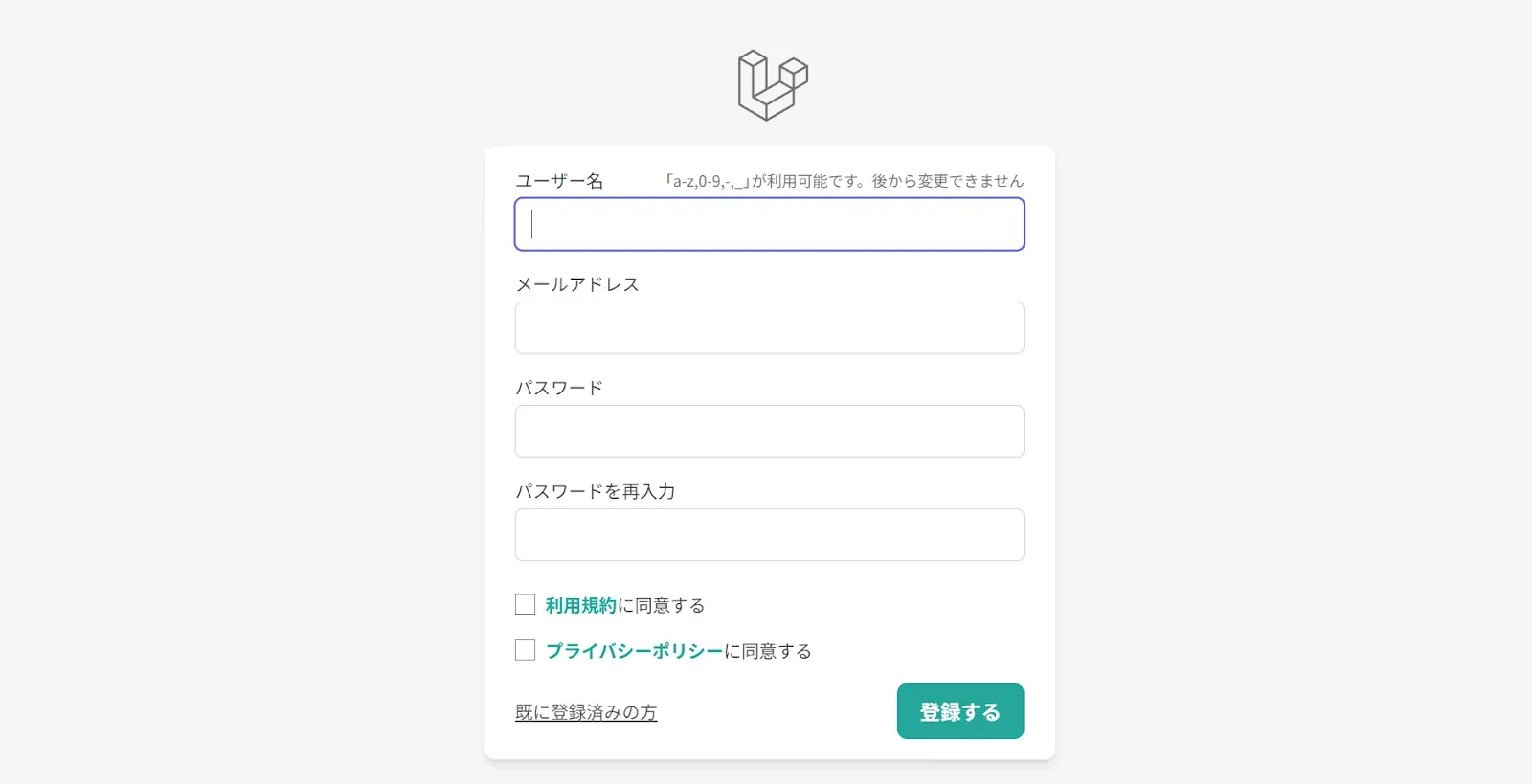
私のサイトは無料サービスなのでそこまで重たい同意じゃなくてもいいんじゃないかということと、他のサービスも参考にした感じでもこの形式が多かったのでこの形式で。
これはフロントエンド側のrequireバリデーションだけでなく、バックエンド側も一応やっておく。
以下のようにLaravelではacceptedというバリデーション項目があるからおすすめ。
'terms' => [
'required',
'accepted'
],
'privacy' => [
'required',
'accepted'
]認証メールをカスタマイズするまとめ
認識メールの文章をカスタマイズした。
その際のまとめ。
HTMLメールだと互換性の問題があるが、MailMessageを使えば平文とHTMLの両方生成されるので問題ない。
そのため、認証メールをカスタマイズしたいときは以下のようにすると良い
-
VerifyEmailを継承したNotificationを作成し、buildMailMessageメソッドをオーバーライドしてメールで使うコンポーネントとその中身を変える
-
「php artisan vendor:publish —tag=laravel-notifications」でメールで使うviewを公開し、気になるところを修正する
-
Userモデルで作成したNotificationを使うよう指定する
-
もし、breezejpを使っていたり予期せぬところでVerifyEmail::toMailUsing();が呼ばれていたらVerifyEmail::toMailUsing(null);で無効化する
実際にやっていく。
php artisan make:notification CustomVerifyEmail
でnotificationの作成。
中身を以下のようにする
<?php
namespace App\Notifications;
use Illuminate\Auth\Notifications\VerifyEmail;
use Illuminate\Bus\Queueable;
use Illuminate\Contracts\Queue\ShouldQueue;
use Illuminate\Notifications\Messages\MailMessage;
// VerifyEmailを継承し、buildMailMessageをオーバーライドしている
// 非同期処理(ShouldQueue)を使いたいから
class CustomVerifyEmail extends VerifyEmail implements ShouldQueue
{
use Queueable;
public function buildMailMessage($url)
{
$appName = config('app.name');
return (new MailMessage)
->subject("[{$appName}]ユーザー登録の認証受付")
->line("{$appName}のユーザー登録に申し込みいただきありがとうございます。")
->line("メールアドレス認証を続けるには、以下のボタンから認証を完了させてください。")
->action("メールアドレスの確認", $url)
->line("このサービスへアカウント登録をしていない場合は、本メールへの対応は不要です。");
}
}次に
php artisan vendor:publish —tag=laravel-notifications
でviewを公開。
私は以下の部分の@lang(‘Regards’)<br>を削除した
{{-- Salutation --}}
@if (! empty($salutation))
{{ $salutation }}
@else
@lang('Regards')<br>
{{ config('app.name') }}
@endifそしてUserモデルで
public function sendEmailVerificationNotification()
{
$this->notify(new CustomVerifyEmail());
}のように使うNotificationを指定すればおk。
もし、VerifyEmail::toMailUsing();を意図しないところで使っていて、かつ修正が難しいところだったら。
VerifyEmail::toMailUsing();の中身を無効化しても問題ない事を確認したうえで、authServiceProvider.phpのboot()で
VerifyEmail::toMailUsing(null);
をしてあげる。
これで、verifyEmailのif (static::$toMailCallback)の分岐に引っかからなくなる。
実際に認証メールを送ってみる。
以下のように非同期処理が行われ、
![]()
メールが届いた(テストしすぎて6個届いてるけど)

いいんじゃないだろうか。
送信されたメールのソースをみたらしっかりtextとhtmlの両方送られていた。
メール認証の中身を変更する際の注意点
なんか結構注意点があったので記述
-
ワーカーを再起動しないと変更は反映されない
-
viewのキャッシュをクリア「php artisan view:clear」しないと反映されない
-
「resources/views/vendor/notifications/email.blade.php」をPhpStormのオート整形でコード整形すると表示がバグる
-
VerifyEmail::toMailUsing()の話があったけど、パスワードの再設定メールでも同じ問題が起きそうなので注意
いや、コード整形したらバグるのやばすぎでしょう。
私の場合自動保存するときに勝手に整形しちゃうので、PhpStormでファイルを開いたら詰むという意味わからん状況に。
サービス名を考える
これ、色々書いたんだけどマジで決まらなすぎるので次回のインフラに繋ぐ。
CKEditor5のライセンスについて
CKEditor5のライセンスが私の中で曖昧だったので、サービス開始前にしっかりする。
※以下のライセンスに関する記述は内容を保証するものではありません。ライセンスが変わっていたり、間違っている可能性があります。
CKEditor5はSoftware License Agreementにある通り「GNU General Public License Version 2 or later」のライセンスになっている。
GNU General Public License Version 2は略してGPLv2と呼ばれたりする。
GNUはグニューと呼ぶらしい。
or laterは何を意味するかなんだけど、リンク先を見る感じGPLv3かな。
つまり、私たちはCKEditorをGPLv2またはGPLv3ライセンスの元利用ができる。
もし、このGPLv2またはGPLv3ライセンスに従いたくない場合、商用ライセンス契約をすることで交渉が可能らしい。
つまり、もし無料で使いたいならGPLv2、GPLv3に従おうということ。
GNU とは何なのか
改めて書くけど、これは独自の見解で内容を保証するものではないので、自己責任で。
そもそもGNUってなんだろってとこから。
参考文献
GNUはRichard Stallmanが「全てのコンピューターユーザーはオペレーティングシステムが必要。だから自由なオペレーティングシステムが必要である」という課題に答える為に始めたものらしい。
この課題を解決するためにUnixと互換性のあるGNU(GNU is Not UNIX)を作ろうとしたという感じ。
実際にGNU Hurdという自由なカーネルを作ろうとしてたんだけど、途中で自由ソフトウェアであるLinuxが出てきたので今Hurdの開発は止まってるみたい。
また、今のLinuxディストリビューションの全ソースコードの内、28%はこのGUNライセンスらしい。
だから、LinuxではなくGNU/Linuxと呼ぼうと公式サイトでは書いてある。
とりあえず、そんなGNUのライセンスを広く誰でも使えるように文章化したのがGPLということかな。
GPL(General Public License)とは何なのか
じゃあ、そんなGPLはどんなものなのだろうか。
まず、GPLの基盤として以下の4つの自由がある
-
いかなる目的にも、ソフトウェアを使う自由、
-
必要にあわせてソフトウェアを変更する自由、
-
友人や隣人とソフトウェアを共有する自由、そして、
-
変更を共有する自由、です。
恐らくこれは機械翻訳されたものだし、アメリカンっぽい表現があってわかりにくいんだけど、日本語Wikipediaのものをそのまま持ってくると
-
プログラムの実行
-
プログラムの動作を調べ、それを改変すること(ソースコードへのアクセスは、その前提になる)
-
複製物の再頒布
-
プログラムを改良し、改良を公衆にリリースする権利(ソースコードへのアクセスは、その前提になる)
これら4つを許諾するライセンスという感じ。
これだけ聞くと、じゃあ自由に商用利用でもなんでも使えるんだ! って感じがするし、それは間違いでないはず。
しかし、GPLの条件があり、GPLv3の第4項では以下のように書いてある
You may convey verbatim copies of the Program’s source code as you receive it, in any medium, provided that you conspicuously and appropriately publish on each copy an appropriate copyright notice; keep intact all notices stating that this License and any non-permissive terms added in accord with section 7 apply to the code; keep intact all notices of the absence of any warranty; and give all recipients a copy of this License along with the Program.
特に「all recipients a copy of this License along with the Program」が大事で、プログラムの受領者すべてにプログラムと共にGPLの複製を与えなければいけない。
何回も言うけど、これは私の解釈なので間違っている可能性があるけど、CKEditor5をGPLv3のライセンスで利用するなら、改変したCKEditor5をGPLv3のライセンスで公開する必要がありそう。
ちなみに、こんな感じで二次創作物にもGPLライセンスを付けていき芋づる式になるのをGPLの感染というらしい。
正直、これくらいならお安い御用なんだけど、ソースコード見られるのは恥ずかしいね。
いや、どちらにしろJSで読み込まれるので見放題ではあるんだけど。
タグの仕組みを改善する
正直、必須のことではないので、こんなのやらずに早くリリースしろって感じなんだけど……息抜きも兼ねてやらせてください!!!
あと、タグに特定の問題があって、後からの変更だと取り返し付かない可能性がある部分もあるので今のうち解決したいというのもある。
取り返し付かない(つきにくい)問題っていうのがタグの表記揺れ。
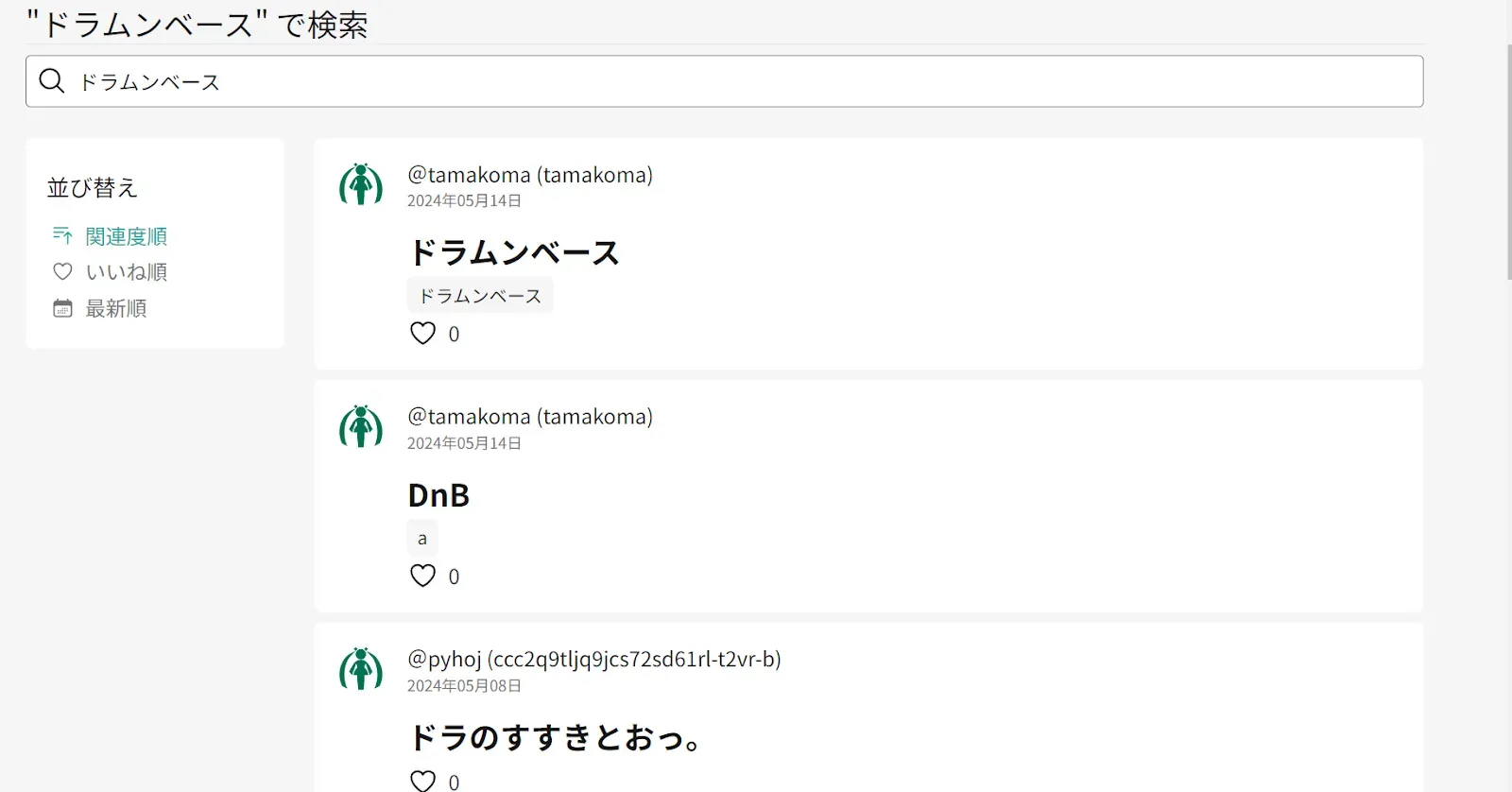
DnBという音楽ジャンルがあると思うんだけど、DnBって表記がめっちゃあるんだよね。
例えば、DnB、Drum and Bass、d’n’b、Drum’n’Bass、ドラムンベース、D&B、Drum & Bassとか。
しかも、DnBの場合は人によって表現がめっちゃ変わるからタグが分散する可能性大。
だから、この対策を予め練っておきたい。
対策方法によっては後からの変更だとダメなこともありそうなので今のうちにやる。
表記揺れの改善策
今考えているのはタグの自動提案機能と、記事検索時のタグエイリアス機能。
タグの自動提案機能は以下のようなやつ。
これはQiitaのタグ機能なんだけど
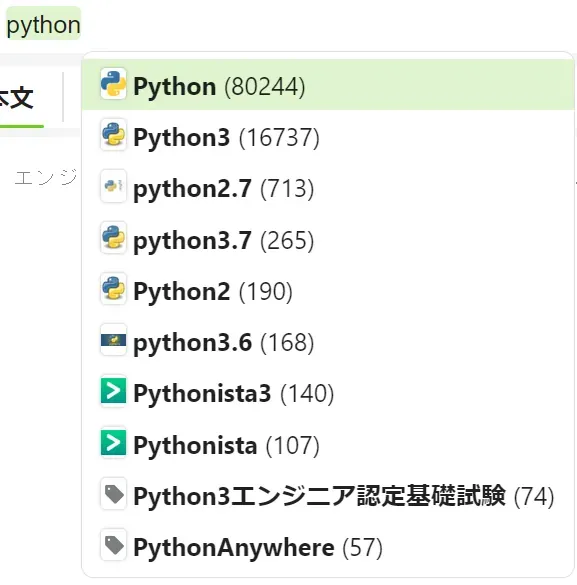
こんな感じでタグ入れると自動提案してくれる。
これをすれば少なくとも大文字小文字の区別くらいはできるし、利便性は確実に上がる。
ただ、DBの負荷がある程度かかりそうだけど、どうなんだろ。
やってみて負荷がやばかったら停止もできるので、一回やってみるか。
あと、タグエイリアス機能というのは、検索時にDnBと検索されたらタグのエイリアスに登録されているキーワードも同時に検索するみたいな感じ。
これは、手動で登録するしかないと思うので運営負担がすごいんだけど、解決策にはなりそう。
手順としては
-
タグ入力の改善
-
タグのリコメンド
-
タグのエイリアス
という順で行く。
大変そうならエイリアスは飛ばそう。
タグ入力を改善
まずタグの入力をわかりやすくしたい。
今は以下のような感じでカンマ区切りの入力。

理想は以下のZennのタグ入力のような感じ。
開発者モードで見ると、以下のような処理になってるっぽい
-
タグを入力
-
enterを押すとタグをボタンに変更
-
tags配列に保存
-
tagをボタンに変更する
-
inputを空にする
-
-
inputをタグを横に並べる
-
もしタグボタンの削除が押されたら配列から削除
だいぶ推測も混ざってるので違うところもあるかもしれないけど、多分こんな感じ。
この仕組みをAlpine.jsで実装したい。
とりあえず、以下のように実装した。
<div x-data="tagInput()"
class="md:mx-104 my-16">
<div class="box-content rounded bg-white border border-sumi-600 min-h-40 h-fit flex items-center">
<div class="flex flex-wrap">
{{-- tags配列をそれぞれ表示 --}}
<template x-for="(tag, index) in tags" :key="index">
<div class="flex items-center pr-8 pl-16 ml-8 rounded border border-sumi-300">
<span x-text="tag"></span>
<button type="button" @click="removeTag(index)" class="text-xl ml-8">×</button>
</div>
</template>
<input
class="text-base border-none focus:ring-0 px-8 py-4"
:placeholder="placeholderText"
maxlength="{{ config("validation.article.tags.maxLength") }}"
x-model="newTag"
@keydown.enter.prevent="addTag()"
@keydown.backspace="backspace($event, $refs.inputTag)"
x-ref="inputTag"
>
</div>
</div>
<div x-show="errorMessage" class="text-red-500">
<p x-text="errorMessage"></p>
</div>
</div>
<script>
function tagInput() {
return {
tags: [], // タグを保存する配列
newTag: '', // 新規タグの入力値
maxTags: {{ config('validation.article.tags.maxTags') }},
errorMessage: '',
placeholderText: 'タグを追加',
addTag() {
this.clearError();
const newTagTrimmed = this.newTag.trim();
if (newTagTrimmed === '') {
this.setError('タグを入力してください。');
} else if (this.tags.includes(newTagTrimmed)) {
this.setError('このタグは既に追加されています。');
} else if (this.tags.length >= this.maxTags) {
this.setError(`タグは最大${this.maxTags}個まで追加できます。`);
} else {
this.tags.push(newTagTrimmed);
this.newTag = '';
if (this.tags.length >= this.maxTags) {
this.placeholderText = "";
} else {
this.placeholderText = "タグを追加"
}
}
},
removeTag(index) {
this.tags.splice(index, 1); // 指定されたインデックスのタグを削除
if (this.tags.length < this.maxTags) {
this.placeholderText = 'タグを追加';
}
},
backspace(event, inputElement) {
// selectStartもselectEndも0 == カーソルがinputの最初にある
if (inputElement.selectionStart === 0 && inputElement.selectionEnd === 0) {
if (this.tags.length > 0) {
event.preventDefault(); // デフォルトのバックスペース動作を防止
this.removeTag(this.tags.length - 1); // 最後のタグを削除
}
}
},
setError(message) {
this.errorMessage = message;
},
clearError() {
this.errorMessage = '';
}
};
}
</script>動かすとこんな感じ。

かなり楽しいし、Alpine.js便利だなぁという感想。
まだこのtags配列をpostするようにとかはしてないんだけど、とりあえず見た目はいい感じ。
タグの入力候補の提案機能
ここにさらに入力候補の提案機能も入れる。
というか、それがメイン。
QiitaやNoteみたいな感じで、入力された内容から似たTagとその件数を表示したい。
LaravelでAPI系を弄ったことがないので、そこらへんも学びながら。
Laravelでタグの提案機能用APIを作る
欲しいのは、tagの名前を送ったらそれに似たタグと利用回数を返してくれるAPI。
というかタグをサジェストするだけなら、認証はいらないのかな。要らない気もするけど、非ログインユーザーにスパム的にされるのもまずいので、練習がてらやってみよう。
APIにも認証とかがあるらしいのでちゃんとそういうのを学びたいんだけど、日本語ドキュメントにAPI関連のドキュメントがないっぽい? というかAPIというジャンルはなくて、ルート、認証それぞれにちょっとだけAPIの項目があるから、つまみながら読むしかないっぽい。
APIの認証
どうやら、APIの認証は日本語ドキュメントにある通り、APIにブラウザという概念がないからクッキーは使わない。
代わりにAPIトークンと有効なAPIトークンテーブルを利用して認証を行うらしい。
そして、このAPIトークン認証に対応するため、LaravelではPassportとSanctum(サンクタム)というオプションパッケージを提供している。
PassportはOAuth2という認証方法を取るらしく、ややこしいっぽい。Sanctumはそれを解消するためにできたとある。
しかも、routesのapi.phpにある認証方法はSanctumなのでとりあえずSanctumを使う。
内部で処理が解決するAPIならSanctumいらない
Sanctumの認証を進めていくうちに、これは必要ないのではという説が出てきた。
APIトークンは先の説明にもあった通り、ブラウザの概念が無くセッション管理できないから仕方なく使う。でも、私の今作ろうとしているAPIはブラウザからリクエストができる。
じゃあ、わざわざAPIトークン認証を使う必要はないねという感じ。
もし、SPAしたい人とか、外部の許可した人にだけAPI使ってほしいとか、ドメインが違うところからAPI使いたい場合はこのAPIトークン認証が必要なんだね。
今回の場合は普通にセッションを使った認証で良さそう。
APIをセッション認証で管理する
そういえば今までにJSの非同期処理を使った場面が1個だけあった。
それが、CKEditorの音源・画像投稿。
APIとは言わないかもしれないけど、JSの非同期処理という点では一致していると思う。
あれって、webルートを通してるんだよね。だから、セッション認証がそのままできてる。
apiルートの方はミドルウェアやguard設定の関係でそのままだとセッション認証ができない。
api的操作をするからapiルートっていうのがあるとそっちが適切な方だと思っちゃうんだけど、セッション認証をするなら恐らくwebルートの方が適切。
だから、このタグサジェストapiはwebルートを通し、セッション認証する。
うん。だから結果やってることはいつも通り。
ルート作って、コントローラ作ってという感じ。
できた。
使った感じは以下の通り
どうやらAlpine.jsのx-textを使えばエスケープして表示が可能。
逆にエスケープしたくないときはx-htmlを使うみたい。
レスポンスが遅いのは、単純にAPIからの返答の時間もあるんだけど、「@input.debounce」が関わっている。
@input.debounceのdebounceを付けることで、デフォルトでは250msの空き時間を作ってくれる。だから、頻繁にAPIを叩くことがなくなるねという感じ。
一応以下のようにレスポンシブ対応もできている。あんま綺麗ではないけど、簡易的なものなのでしょうがなし。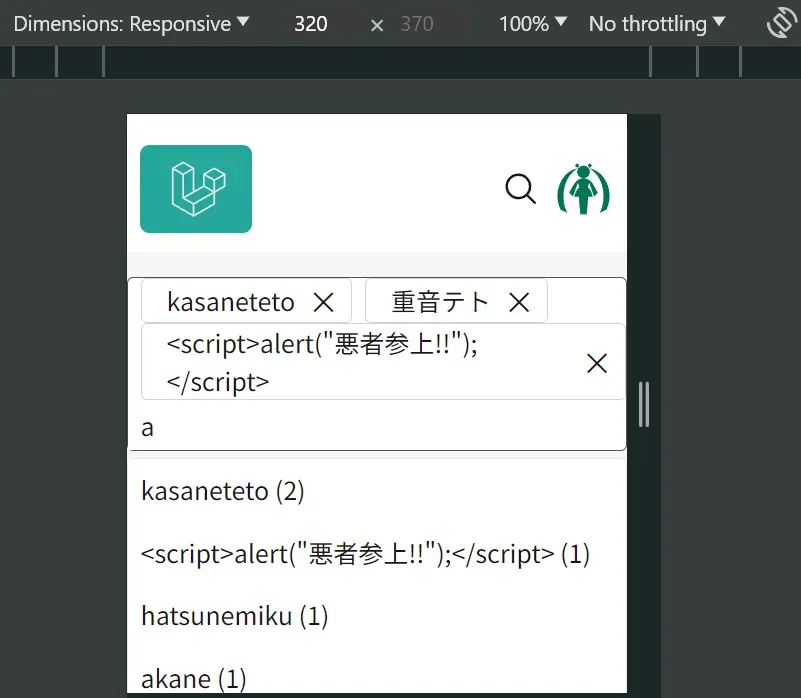
あとは、これをeditに持って行って、投稿時にtags配列のものを投稿するようにしたらおk。
tagのoldやら
前述したとおり、先のコードをeditに持っていって、投稿時にtags配列を投稿するようにしたら完了なんだけど、何個か躓きポイントがあった。
まず、今まではtagsをカンマ区切りの文字列として扱っていたのだけど、今回の変更により配列として扱えるようになった。というより、カンマもタグに入れられるようになったので配列として扱わないと厳しい。
じゃあどうやって配列をPHPに渡すかなんだけど、
<template x-for="(tag, index) in tags" :key="index">
<input type="hidden" name="tags[]" x-bind:value="tag">
</template>のように、name=”name[]”のinputを複数置くと、それはまとめて配列として扱われる。
とりあえず、これで配列としてpostできるようにはなった。
しかし、次はtagsが文字列型からJsonになったんだけど、、oldとか既に保存した内容どうやって持ってくる?
解決策は以下
@php
$draftTags = json_decode($draft->tags,true) ?? [];
$oldTags = old('tags', $draftTags);
@endphp
tags: @js($oldTags),draftのtagsは今まで文字列型だったんだけど、json型があったのでjson型に配列のまま投入し、取り出しjsonからPHP配列にデコード。
次にold関数でoldのtagsに値が無いかの確認。あればそちらが、なければdraftの値がoldTagsへ。
最終的にJSのtagsに@jsディレクティブを使ってPHP配列をJS配列へ変換。
これでいけた。
@jsはエスケープされているのか
@php
$draftTags = json_decode($draft->tags,true) ?? [];
$oldTags = old('tags', $draftTags);
@endphp
tags: @js($oldTags),のようにデータを取得するわけだけど、@jsでエスケープ処理されてないと典型的なXSSなので調べよう。
@jsはLaravelドキュメントにないんだけど、Laravel8のこのプルリクエストで追加されたBladeのディレクティブ。
内部的には以下のようになっている。
<?php
namespace Illuminate\View\Compilers\Concerns;
use Illuminate\Support\Js;
trait CompilesJs
{
/**
* Compile the "@js" directive into valid PHP.
*
* @param string $expression
* @return string
*/
protected function compileJs(string $expression)
{
return sprintf(
"<?php echo \%s::from(%s)->toHtml() ?>",
Js::class, $this->stripParentheses($expression)
);
}
}なるほど。bladeディレクティブはこんな感じで「」を返すことでphpを埋め込んで処理してるんだね。
やっていることは、sprintfでJs::classを%sに代入し、「toHtml() ?>」みたいなコードを生成している感じ。
ちなみに、$this->stripParentheses()は丸括弧を取り除く関数。何故使ってるかは正直わかんないんだけど、処理をしやすくするためっぽい?
すなわち、Js::from(入力)->toHtml()でエスケープされてれば問題なさそう。
Js::from()はエスケープされているのか
Js::from()は以下のようになっている。
<?php
namespace Illuminate\Support;
use BackedEnum;
use Illuminate\Contracts\Support\Arrayable;
use Illuminate\Contracts\Support\Htmlable;
use Illuminate\Contracts\Support\Jsonable;
use JsonSerializable;
class Js implements Htmlable
{
/**
* JavaScriptの文字列。
*
* @var string
*/
protected $js;
/**
* JSONにエンコードする際に使用するフラグ。
*
* @var int
*/
protected const REQUIRED_FLAGS = JSON_HEX_TAG | JSON_HEX_APOS | JSON_HEX_AMP | JSON_HEX_QUOT | JSON_THROW_ON_ERROR;
/**
* 新しいクラスのインスタンスを作成する。
*
* @param mixed $data
* @param int|null $flags
* @param int $depth
* @return void
*
* @throws \JsonException
*/
public function __construct($data, $flags = 0, $depth = 512)
{
$this->js = $this->convertDataToJavaScriptExpression($data, $flags, $depth);
}
/**
* 与えられたデータから新しいJavaScript文字列を作成する。
*
* @param mixed $data
* @param int $flags
* @param int $depth
* @return static
*
* @throws \JsonException
*/
public static function from($data, $flags = 0, $depth = 512)
{
return new static($data, $flags, $depth);
}
/**
* 与えられたデータをJavaScriptの式に変換する。
*
* @param mixed $data
* @param int $flags
* @param int $depth
* @return string
*
* @throws \JsonException
*/
protected function convertDataToJavaScriptExpression($data, $flags = 0, $depth = 512)
{
if ($data instanceof self) {
return $data->toHtml();
}
if ($data instanceof BackedEnum) {
$data = $data->value;
}
$json = static::encode($data, $flags, $depth);
if (is_string($data)) {
return "'".substr($json, 1, -1)."'";
}
return $this->convertJsonToJavaScriptExpression($json, $flags);
}
/**
* 与えられたデータをJSONとしてエンコードする。
*
* @param mixed $data
* @param int $flags
* @param int $depth
* @return string
*
* @throws \JsonException
*/
public static function encode($data, $flags = 0, $depth = 512)
{
if ($data instanceof Jsonable) {
return $data->toJson($flags | static::REQUIRED_FLAGS);
}
if ($data instanceof Arrayable && ! ($data instanceof JsonSerializable)) {
$data = $data->toArray();
}
return json_encode($data, $flags | static::REQUIRED_FLAGS, $depth);
}
/**
* 与えられたJSONをJavaScript式に変換する。
*
* @param string $json
* @param int $flags
* @return string
*
* @throws \JsonException
*/
protected function convertJsonToJavaScriptExpression($json, $flags = 0)
{
if ($json === '[]' || $json === '{}') {
return $json;
}
if (Str::startsWith($json, ['"', '{', '['])) {
return "JSON.parse('".substr(json_encode($json, $flags | static::REQUIRED_FLAGS), 1, -1)."')";
}
return $json;
}
/**
* HTMLで使用するためのデータの文字列表現を取得します。
*
* @return string
*/
public function toHtml()
{
return $this->js;
}
/**
* HTMLで使用するためのデータの文字列表現を取得します。
*
* @return string
*/
public function __toString()
{
return $this->toHtml();
}
}エスケープで大事なのは REQUIRED_FLAGS定数とencodeメソッド。
このREQUIRED_FLAGSでは「REQUIRED_FLAGS = JSON_HEX_TAG | JSON_HEX_APOS | JSON_HEX_AMP | JSON_HEX_QUOT | JSON_THROW_ON_ERROR」が定義されている。
これをPHPの公式ドキュメントで見ると、&,”,’,<,>などの基本的な文字のエスケープ定数なことがわかる。
そして、encodeメソッドでは「return json_encode($data, $flags | static::REQUIRED_FLAGS, $depth);」のようにその定数を使いjsonエンコードしている。
つまり、この部分でエスケープがされている。
assertDatabaseHasでjson型のアサートを行う
テスト作ってて詰まったので記録。
Draftのタグの保存をjson方式にしたんだけど、そのアサートが上手く行かない。
具体的なテストコードは
->assertDatabaseHas(
'drafts',
[
'title' => '新testタイトル',
'body' => '新test本文',
'tags' => json_encode(["tag1"])
]
)とか、
->assertDatabaseHas(
'drafts',
[
'title' => '新testタイトル',
'body' => '新test本文',
'tags' => '["tag1"]'
]
)とか。
そして、エラーはどちらも
Failed asserting that a row in the table [drafts] matches the attributes {
"title": "新testタイトル",
"body": "新test本文",
"tags": "[\"tag1\"]"
}.
Found similar results: [
{
"title": "新testタイトル",
"body": "新test本文",
"tags": "[\"tag1\"]"
}
].のようなエラーになる。
どっからどう見ても一緒なんだけど、内部的にはなんか違うらしい。
色々調べてたら「How to assert that the database contains a value stored as JSON」というQ&Aを発見。
その中の一つにある解決策で、DBでjson型に変換することでフォーマットの一致を計るものがあった。
function castToJson($json)
{
// Convert from array to json and add slashes, if necessary.
if (is_array($json)) {
$json = addslashes(json_encode($json));
}
// Or check if the value is malformed.
elseif (is_null($json) || is_null(json_decode($json))) {
throw new \Exception('A valid JSON string was not provided.');
}
return \DB::raw("CAST('{$json}' AS JSON)");
}やってることのメインは以下の2行。
$json = addslashes(json_encode($json));
return \DB::raw("CAST('{$json}' AS JSON)");まず、PHPでjson_encode()とaddslashes()を使いjson型に変換。
その後、生クエリを投げてcast(型変換)をDBを通してするという感じ。
実際にこれを使って
->assertDatabaseHas(
'drafts',
[
'title' => '新testタイトル',
'body' => '新test本文',
'tags' => $this->castToJson(["tag1"])
]
)のようにしたらパスした。
また、$draft->tagsのように取り出したものを
->assertDatabaseHas(
'drafts',
[
'title' => $draft->title,
'body' => $draft->body,
'tags' => $draft->tags
]
)のようにやっても失敗するので、
->assertDatabaseHas(
'drafts',
[
'title' => $draft->title,
'body' => $draft->body,
'tags' => $this->castToJson(json_decode($draft->tags))
]
)のように一回json_decode→castToJsonという2度手間が必要。
はじめてのAPI設計で気を付けること
タグのリコメンドをしてくれるAPIが完成したわけだけど、テストを作成していて気づいたのが「ユーザーに$tagの全ての情報が渡っている」ということ。
jsonのレスポンスを返すバックエンドのコードは
return response()->json($tags);のようになっている。
当然なんだけどこんな感じで何も指定しないと、$tagsにある全ての情報をフロントエンドに送ってしまう。
必要に応じて制限してあげる必要がある。
LaravelのようにMPAでは、HTMLを生成しそれを送信してるので基本気にならないんだけど、あっちでHTMLを生成するみたいな場合は注意が必要だね。
こういう時の為に$hiddenがある
Laravelのモデルで設定できる$hidden。
こういうAPIの返還とかで制限するために使うみたい。
$hiddenに入れた要素は配列への変換やjsonへの変換時に除外されるとのこと。
つまり、主にAPI通信でうっかり要素に含めちゃったミスを防げる。
てっきり、$hiddenって$user->passwordみたいなのを防ぐものだと思ってた。
改めて、$hiddenが防ぐのはjsonや配列への変換、シリアル化のミスを防いでくれる。
ちなみに、$hiddenはブラックリスト方式だけど、$visibleを使えばホワイトリスト形式でも使える。
とりあえず、漏れたらまずいものは全部$hiddenに入れとく。
キャッシュにデータベースからの結果を保存する
タグのサジェストもそうなんだけど、DBに頻繁にアクセスするシステムは、DBにかなりの負荷をかける。
タグのサジェストやBANされているか否かってリアルタイムの情報である必要はそこまでないので、そういうのはキャッシュにDBにアクセスした結果を残して置けるみたい。
キャッシュドライバ
キャッシュってメモリに保存しておくものだと思ってたんだけど、そうでもないっぽい。
キャッシュのドライバはconfigから設定ができて、初期設定だとfileというのになっている。
このfileはそのままファイルの意味で、ストレージ内にファイルを作って保存してキャッシュを残す形式のもの。
小規模であれば問題はないらしい。
もし、メモリに残して高速化を図りたいのであれば、MemcachedやRedisといった標準装備ではないドライバを使う必要がありそう。
とりあえずfileキャッシュで実装して、余裕あれば外部ドライバにも挑戦してみようか。
データベースの結果をremember()でキャッシュに残す
やりたいことは、不適切なタグ一覧やタグの一覧を一定期間キャッシュに残して使いまわすというもの。
これをすれば、DBにアクセスする回数が減るから負担が減るはず。その代わり、最新の情報ではなかったり、キャッシュ領域は食うので注意という感じ?
具体的に手段を示すと
-
キャッシュに期限内のDBの結果が既にあるかを確認
-
無かったらDBからデータ持ってきてキャッシュに新しく保存
-
あれば既にあるものを利用
という感じ。
LaravelだとキャッシュはCacheファサードでCRUD系は色々弄れる。
しかも便利なことに、私のやりたいことはCache::remember()で可能。
以下はドキュメントのやつなんだけど、こんな感じでremeber関数内でDBにアクセスすると「キャッシュがあればそこから。無ければDBから取ってきてキャッシュに保存」をしてくれる。
$value = Cache::remember('users', $seconds, function () {
return DB::table('users')->get();
});素晴らしすぎる。
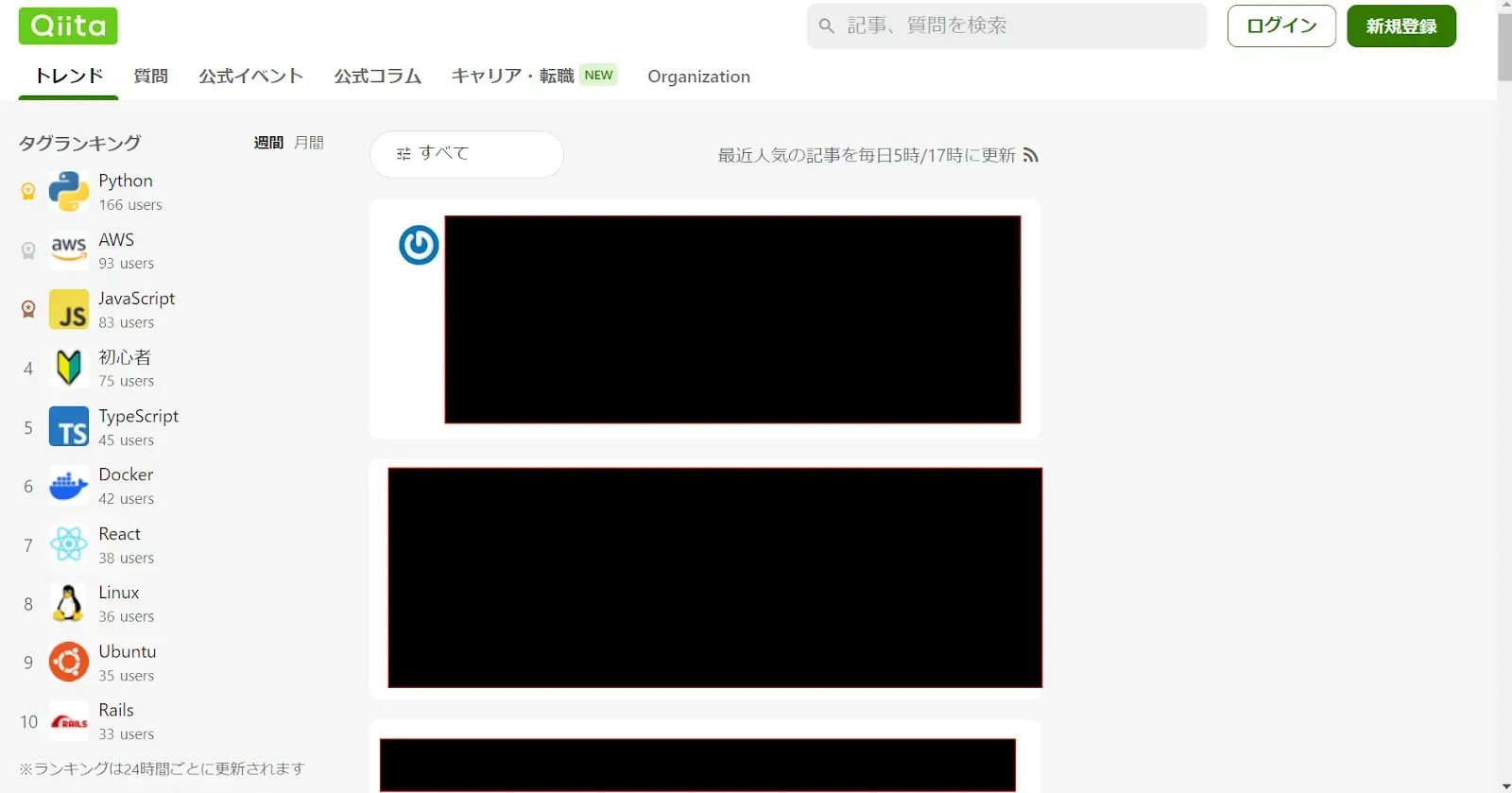
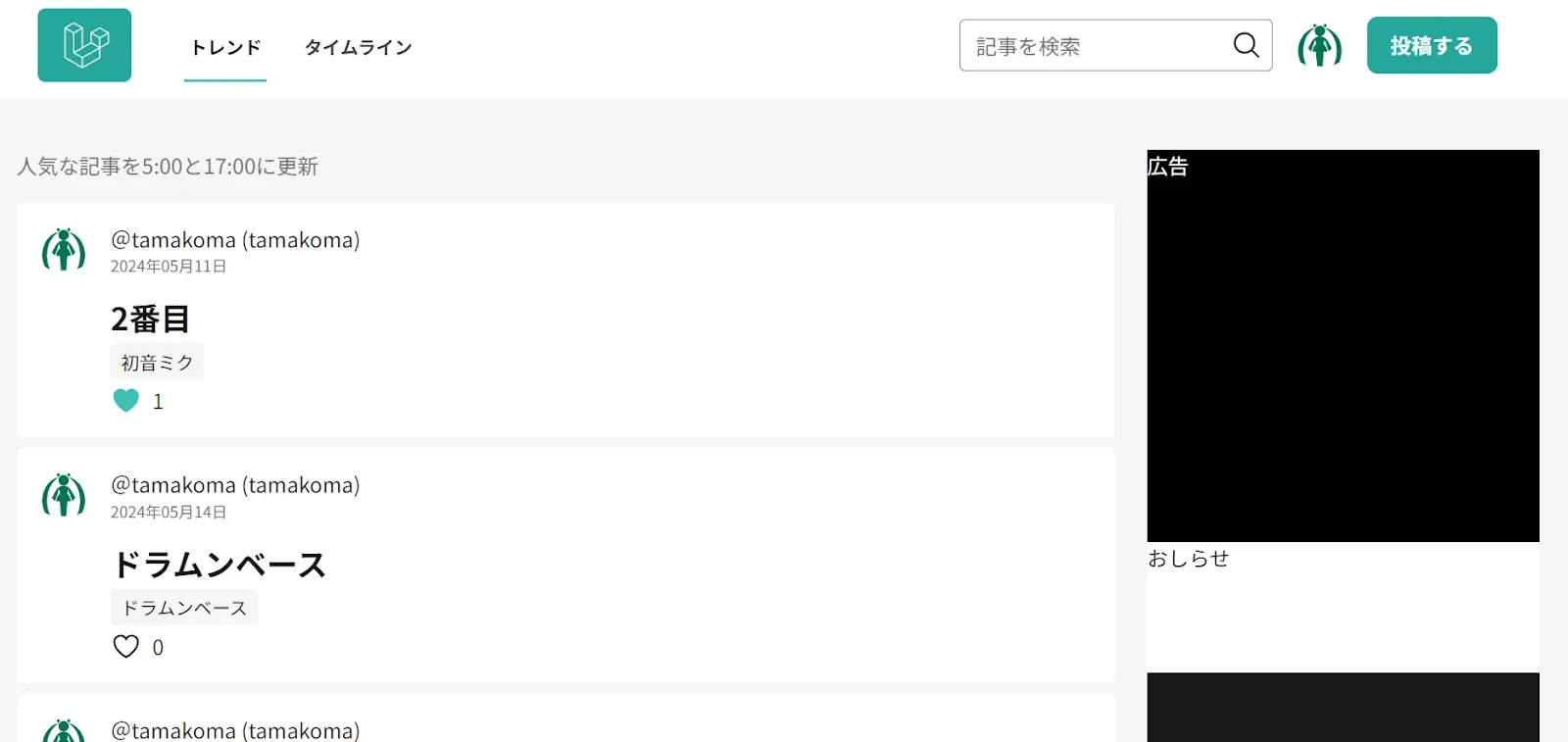
一覧画面を改善する
本当はもうインフラいきたいんだけど、このままだと記事一覧ページが古い順に表示されるだけの使いにくいページになってしまうので、最低限だけ作りたい。
作りたいのは、Qiitaだったら
こんな感じのメインページ。
Qiitaだと、非ログイン時はトレンドのみ、ログイン時はホーム、トレンド、タイムラインの3種類あるっぽい。
とりあえず真似る精神で同じ構成にしよう。
ここで問題なのが、ホームとトレンド。
タイムラインは投稿された順に表示すれば良いけど、ホームはユーザーに関連するものを、トレンドは独自のトレンドアルゴリズムを作る必要がある。
まじでどうしようね。
とりあえずタイムラインをつくる
タイムラインは投稿された順に記事を並べればおk。
基本的に構成はどれも一緒なので、レイアウトでも作って使いまわそう。
実際に広告を載せるかは別として以下のような感じでいいかな。
というか、元々記事一覧ページがタイムラインと同じシステムだったのでコピペすればおkだった。
トレンドをつくる
トレンドのアルゴリズムどうしよう。
「Qiita トレンド 仕組み」という安易な検索をしたらトレンドを考察しているQiitaの記事があった。
「Qiitaのトレンド表示機能についての考察」
この記事の主張だと「トレンド評価ポイント=いいね数÷閲覧数」ということらしい。
確かに悪くなさそうな感じがする。
もしこれを実装するのであればトータルビュー数を記録する必要がありそう。
どちらにしろ閲覧数は必要そうなので閲覧数を取得するシステムを作る。
閲覧数をカウントする
一番最初に思いつくのはarticlesに閲覧数カラムを作り、コントローラのviewメソッドで+1していく方法だと思う。
でも、これだとviewするたびにDBにアクセスするのがちょっといただけない。
うーん。どうするべきか。
色々調べた感じ、やっぱviewコントローラでDBにインクリメントしてく方法が多い。
確かにアクセス数が少なければ問題なさそう。
ただ、クラウド環境のDBって使った数だけ課金されて馬鹿にならない額になりそうなので、出来るだけDBを使わないアプローチにしたい。
とすれば、キャッシュにアクセス数を保存しておき、定期的にDBに保存するという方法はある程度有効そう。
これには今までのfileキャッシュを使ってもいいんだけど、Redisを使うのがおすすめっぽい。
Redisはそれ単体でかなり大きなアプリケーションっぽいので学習コストが気になるけど、頑張ってみよう。
Redisを軽く学ぶ
LaravelでのRedisの使い方を学ぶまえにRedisを学ぶ。
参考文献
-
Qiita「初心者による初心者のためのRedis解説」
-
slideshare「webエンジニアのためのはじめてのredis」
-
slideshare「Redisの特徴と活用方法について」
私が思ったRedisの特徴を並べていく
OSSでBSDライセンス
つまり、BSDライセンスに従えば商用利用もソースコード非公開で無償でおk。
BSD(Berkeley Software Distribution)ライセンスは主に、開発者が責任を負わないことと、再頒布時に著作権・ライセンス表示してくれという感じ。
コピーレフトではないので、再頒布時に異なるライセンスを付けてもおk。感染しない。
Redisはメモリを使うDB
そういうのをインメモリデータベースというらしい。
メモリを使うからめっさ速い。
その代わり、処理中にサーバー落ちたらメモリデータとかは消えるからそんな重要じゃないものとか、簡易的に使いたいときに便利なDBなのかな。
データの永続化が可能
RedisにあるデータをメモリからRDBに移したり、ファイルに移したりすることでデータの永続化が可能。
Redisサーバーを建てて処理する
Redisはサーバーを建ててそこと通信して処理する形。
これ、なんでわざわざサーバーを建てる必要があるのだろうかと思ったけど、MySQLとかもサーバー建てるのか。
サーバーを建てる理由はわかんないけど、viteとかはリアルタイムでレスポンスする為にサーバーを建てる必要があった気がするから、常に稼働していてリアルタイムレスポンスが必要なソフトウェアは仕組み的にサーバーになるのかな。
シングルスレッド処理
Redisはシングルスレッド処理で、CPU1コアだけを使うみたい。
だから、処理能力を高めたかったらRedisサーバーを複数建てるのだとか。
Redisサーバーを複数建てることを水平拡張という。
メモリパンパンになったら
メモリで動くDBとのことだけど、メモリがパンパンになったらどうなるのだろうか。
メモリがパンパンになったらmaxmemory-policyというルールに従い自動的に削除する。
もし、それでもパンパンになったら書き込みできなくなってエラーになるみたい。
妥当な処理。
KVS(Key-Value Store)というデータ管理方法
KVSと聞くと難しいけど、一意のキーと任意の値を対応させるPythonでいうディクショナリ型。
RDBだとカラムを複数作って〜みたいな感じだけど、Redisは基本一対一で処理する。
型は5つ -文字列型-
文字列型はそのままの意味なんだけど、keyと文字列が対応する保存形式。
512MBまで保存できる。
また、バイナリセーフというのが特徴みたい。
バイナリセーフ自体あんまわかんないんだけど、バイナリをそのまま正しく扱えるから画像や音源ファイルをそのまま扱えたり、Nullバイト攻撃を避けられたりするメリットがある。
型は5つ -配列-
keyに対して複数の文字列型valueを末尾に追加(append)していく形式。
先頭と末尾へのアクセスはO(1)で、中間はO(N)。
2^32-1までいける。
型は5つ -セット-
競プロでお世話になるPythonのset()と同じ。
文字列型を順序なし、重複なしでキーに保存でき、全データへの追加・削除・取り出しがO(1)。
だから、存在するかしないかの判定に強い。
2^32-1まで保存できる。
型は5つ -順序付きセット-
セットに順序を付けたもの。
一意の文字列型valueに加えて整数型のscoreが必要で、scoreで順序付けて保存してくれる。
スコアの取り出しはO(1)で、追加はO(logN)みたい。
ランキングを作ってくれと言わんばかりの型。
型は5つ -ハッシュ型-
KeyとValueに加えて子Keyで管理する方法。
例えば、tamakomaというKeyにemail、usernameなどの子キーを作り、email、usernameという子キーに任意のvalueを入れて使うみたいな。
この子キーはfieldという。
LaravelでRedisを使えるようにする
Predis VS PhpRedis
どうやらPHPでRedisを使うにはPredisとPhpRedisという2つのライブラリがある。
-
-
Composerからインストールできる
-
一時期活動休止してたが、最近は活発
-
PhpRedisと比較してパフォーマンスが悪い
-
GitHubのStarは7.5K
-
PHPで書かれてる
-
-
-
Composerからインストールできなく、peclというのを使いインストールする
-
活発に動いてる
-
Predisと比較してパフォーマンスが良い
-
GitHubのStarは9.9K
-
Cで書かれてる
-
という感じ。
パフォーマンスというのは具体的に処理速度や保存されるデータサイズの量。
2019年のデータだけど「PhpRedis vs Predis: Comparison on real production data」こんなのもある。
まあCとPHP比べたらそりゃCのが速いか。
また、Laravelのドキュメントでは「LaravelでRedisを使い始める前に、PECLによりPhpRedisPHP拡張機能をインストールして使用することを推奨します。」とのこと。
マジで悩むところ。
PredisのメリットはComposerで管理できて、PHPで書かれてるからワンちゃん自分で修正できるところ。
PhpRedisのメリットはパフォーマンス。
一回PhpRedisを入れてみて、めっちゃ面倒そうだったらPredisにしよう。
AlmaLinuxにRedisを入れる
とりあえずRedisを入れよう。
RHELだとRedisがデフォルトのパッケージに入っている。
![]()
ありがたや。
sudo dnf install redis
でインストール。
インストールしたら
sudo systemctl enable redis
でLinux起動時に自動起動。
sudo systemctl restart redis
で起動しなおして、
redis-cli ping
でPONGが返ってくればおk。
PhpRedisを入れる
ComposerではなくPECLというのを使ってインストールする。
そもそも私のLinuxではpecl versionとしてもpeclが使えなかったのでpeclのインストールからする。
また、php-develが必要だと言われたのでそれも入れる。
sudo dnf install php-pear php-devel
続いて
sudo pecl install redisでPhpRedisのインストール。
なんかいろいろ聞かれるけどデフォルトで続行。
どうにかインストールできたっぽい。

php.iniにextension=redis.soを追記しろとのことなんだけど、「追記せずとも動いた」という情報や、「本番環境だと追記しないと動かなかった」等の情報がある。
とりあえず今回は言われた通り追記してみた。
追記したら鯖を一応もろもろ再起動
sudo systemctl restart httpd
systemctl restart php-fpm.service
sudo systemctl restart redisつづいてLaravelの設定。
日本語ドキュメント
どうやら初期設定でPhpRedisを使う設定になっているぽいので.envの
CACHE\_DRIVER=redis
SESSION\_DRIVER=redisと
REDIS\_HOST=redis
REDIS\_PASSWORD=null
REDIS\_PORT=6379をいじれば使えるようになりそう。
redisのパスワードがデフォルトでnullの理由なんだけど、Redisのドキュメント曰く、3.2.0以降のredisはデフォルトでプロテクトモードというループバックインターフェース、つまり自身=localhostとしか通信しないモードになっているみたい。
設定終わったら
php artisan optimize:clear
でキャッシュを諸々削除しとく。
これで動けばおk。
LaravelでRedisの操作方法
これ、最初に日本語ドキュメントみたとき、操作どうすんだろと思ったんだけど、日本語ドキュメントをよくみると、
Redisファサードでさまざまなメソッドを呼び出すことで、Redisを操作できます。Redisファサードは動的メソッドをサポートしています。つまり、ファサードでRedisコマンドを呼び出すと、コマンドが直接Redisに渡されます。
つまり、「Redis::[Redisの好きなコマンド]()」とすることでRedisにコマンドが直接渡されるらしい。
だから、SetにAddするsaddを使いたい場合、「Redis::sadd(“key1”,“value”);」とすることで操作できるっぽい。すごいなこれ。
RedisのLaravelテスト
MySQLだとテスト用のDB作って、毎回「use RefreshDatabase;」してってするけど、Redisはどうするのだろうか。
こちらもMySQLの時と同じように対処すれば良さそう。
phpunit.xmlに
<env name="REDIS_DB" value="1"/>を追加する。
redisはデフォで0~15のDBがあり、何も指定しなければ0を使っているそうなので、テスト用に私は1を指定。
そして、TestCaseに
protected function setUp(): void
{
parent::setUp();
// テスト用のRedisデータベースをクリア
Redis::flushDB();
}を追加して毎テストごとにデータベースをまっさらにするように。
Redis::flushall()だと他のDBも削除しちゃうので注意。
とりあえずこれでテストを書いていけば良いのではと思う。
記事を1万件の閲覧数を同期するテストを書いてみた。
結果は0.77979588508606秒だったので、1万記事程度であればぜんぜん問題なさそう。
ちなみに、10万件にしたら11.138769865036秒だった。
トレンドのアルゴリズムを作る
とりあえず閲覧数を取得できるようになったので、ここからトレンドのアルゴリズムを作成する。
Qiitaをみると「最近人気の記事を毎日5時/17時に更新」とあるので、とことん参考にする。
つまり、1日2回ランキングを更新してるみたい。
リアルタイム更新じゃないんだねこれ。
リアルタイム更新にしないメリットはなんだろう。
毎回記事のトレンドを計算しなおさなくて良いのと、更新時にスパムがあれば目視で弾けるのでスパムに対応しやすいとかかな。
実際、流動的すぎると私の管理が難しくなるので、一回1日に1回更新されるトレンドを目指してみよう。
この場合以下の様な流れになると思う
-
1日1回、記事から閲覧数といいね数を参照
-
そこからランキングを作り、Redisに保存
-
トレンドページを閲覧するときはRedisに保存されたデータから表示
「自分がその記事にいいねしているか」の情報がしっかり取得できていない初歩的なミス
記事一覧を取得するときのミスの話。
記事取得時に->withExits(“likedUsers”)でいいねが存在するかを取得してたんだけど、withExits(“likedUsers”)だと他の人がいいねしてもtrueになっちゃうねこれ。
ずっと一人だったから全く気付かなかった。
リレーションを定義し、ユーザーがいいねしているかを取得する
サブクエリを使う方法でもユーザーがいいねしているかは取得できたんだけど、単純にwithExistsを使いたいというのと、loadExists()とかの便利系メソッドを使いたい。
これを実現するにはarticlesとlikesでhasMany()関係を結ぶことでリレーション処理ができそう。
今まで使っていたリレーション
整理するために、今まで利用していたlike関係のリレーションをみる
public function likedUsers(): \Illuminate\Database\Eloquent\Relations\BelongsToMany
{
return $this->belongsToMany(User::class, "likes");
}これはbelongToManyリレーションを取っており、多対多の関係になっている。
これは$article->with([“likedUsers”])とやれば記事をいいねしたユーザーの一覧が取得できた。
つまり、何と多対多の関係かというと、usersとarticlesの多対多の関係であり、likesはその中間テーブル的役割を果たしている。
だから、いいね数をカウントしたい場合は「->withCount(“likedUsers”)」が適していた。
でも、あるユーザーがいいねしているかを「->withExists(“likedUsers”);」で見るのは適していなかった。
つまり、そもそも役割が違うリレーションを使い特定のユーザーがいいねしているかを見ようとしていたのがよくなかった。
自分がいいねしているかのリレーション
そこで、articlesとlikesとの直接のリレーションを定義する。
記事に対し複数のいいねが付き、いいねは1つの記事に対してだけなので、hasMany関係。
return $this->hasMany(Like::class)ここで更に->whereを繋げて自分の場合のみにする。
return $this->hasMany(Like::class)->where("user_id", $userId);こうすれば自分がいいねしたかどうかをwithExists()で使えるようになるという魂胆。
全体のコードは以下
public function meLiked()
{
$userId = auth()->id();
if (!$userId) {
// ログインしていない場合、絶対にマッチしない条件を設定
return $this->hasMany(Like::class)->where("id", 0);
}
return $this->hasMany(Like::class)->where("user_id", $userId);とりあえずそんな感じでいいねしているかは完成。
トレンドのアルゴリズムも簡単に作って完成。
ホームも作ろうかと思ったんだけど、特定の人に対するおすすめを出そうとするとタグやユーザーのフォローとか、検索・閲覧ページの履歴が必要になりそうなので一旦最新順とトレンドで完成にする。
記事検索を弄る
現在記事を検索すると新着順に取得するようになっているので、これをQiitaみたいに「いいね」「新着」「関連」の3つに分けたい。
また、キーワードはタグとタイトルにのみ引っかかるようになってるんだけど、できればユーザー名や記事本文にも引っかかるようにしたいところ。
全文検索を実装したい
現在の実装では記事のタイトルとタグから部分一致の検索仕様になっているので、本文からも検索できるようにしたい。
本文で部分一致検索してもいいんだけど、Like %keyword%の部分一致は線形探索をするらしいのでbodyが長いと途方もなく時間がかかる。
そこで、LaravelのScoutというのを使えば効率的な全文検索ができるっぽいのでやる。
全文検索のまとめ
全文検索関係の情報がそこまでなく、かなり混乱したりしたのでここでまずまとめる。
ここで述べていることは、主に挙動の確認、公式ドキュメントの知識からまとめているもので、ソースコードを理解したわけではないので、正しいかは正直そこまで自信がない。
全文検索について
フルテキストサーチとか言われるもの。
where文で「%keyword%」にすることで実質全文検索できるけど、しらみつぶしに探索する線形探索なので量に比例して計算量が増えていく。
そこで、文を文節に区切りトークン化。それをインデックスして検索しようというのが全文検索。
例えば、「私たちはDTMerだ」という文を記事ID1に作ったなら「私/たち/は/DTMer/だ」のように分けられる。気が効けばDTMerはDTMとDTMerで2つに分かれるかもしれない。
これでDBに
| トークン | 記事ID |
| 私 | 1 |
| たち | 1 |
| は | 1 |
| DTMer | 1 |
| DTM | 1 |
| だ | 1 |
のように保存できる。
もし記事ID2で「私はDTMが好きだ」という文を作ったら「私/は/DTM/が/好き/だ」となりDBは
| トークン | 記事ID |
| 私 | 1,2 |
| たち | 1 |
| は | 1,2 |
| DTMer | 1 |
| だ | 1,2 |
| DTM | 1,2 |
| 好き | 2 |
となるっていうイメージ。
このインデックスを使い、例えば「DTM」と検索すると一致するトークンの記事ID「1,2」が返ってくるみたいな。
検索ドライバについて
この全文検索はMySQLでも可能なんだけど、それに特化した専用ドライバがある。
有名どころは何個かあるっぽいんだけど、Laravel公式のScoutというツールを使うのであればAlgolia、Meilisearch、 Typesense、MySQL/PostgreSQLのいずれかから選択する。
結論から言えば、手軽さを求めるならMySQL/PostgreSQL。
日本語かつ無償ならMeilisearch。
日本語かつ有料ならAlgolia。
速いらしいのはTypesense。
少し調べた情報は以下
-
-
全探索SaaS
-
利用コストは2024年5月7日時点で10万レコード/1万検索まで無料で、それ以降は1000レコード/0.4$と1000検索/0.5$
-
日本語もいける
-
有料な分機能多め
-
-
-
SaaSもあるが、セルフホストもできるOSS
-
セルフホストすれば無償/MITライセンス
-
日本語に特化したMeilisearchを有志の方が作ってくれている
-
機能はAlgoliaと比較すると少ないが、全文検索は全然可能
-
-
-
OSSでGPL3ライセンス
-
日本語情報が全然ない
-
光のように早いらしい
-
日本語対応してないっぽい(情報が無い)
-
これ以降はMeilisearchを前提に話す
Scoutについて
Laravelを利用しているなら、Scoutというツールを使い全文検索を実装するのがおすすめ。
Scoutの目的は全文検索ドライバとLaravelを繋げるというもの。
Scoutの仕組みの理解
ソースコードの解説とかではなく、どんな感じで動くかという理解。
公式ドキュメントを参考にまとめてもいるけど、挙動から推測しているところもあるので注意。
ここで使うのはDB(MySQL)、検索ドライバ(Meilisearch)、Scoutの3つ。
また、articlesというテーブルの全文検索を目的とする。
主に、Scoutはデータ同期とデータ取得の2つの役割があると思っている。
データ同期
Meilisearchは全文検索を実行し検索結果を返す為、自身のDBを持っている。
推奨はされないが、Meilisearchを簡単なDBのように扱うことも可能のはず。
ということは、MeilisearchのDBにMySQLのarticlesのデータを写す必要があるよね。
それを(ある程度)自動でやってくれるのがScout。
Scoutを使い全文検索したいモデルを指定することで、そのモデルが変更される度に自動的にデータを同期してくれる。
これには以下の注意点がある
-
Laravelを通した更新じゃないと同期してくれない
-
同期するということは、そのたびにMySQLを動かしMeilisearchのインデックスを作り直すということなので負担がかかる
データ同期ではJobを使った非同期処理が可能なので、それが前提感はある。
データ取得
Scoutを使いデータを取得する仕組みを軽く。
Scoutでは以下のようにデータを取得できる。
Article::search($keyword)->where("id",1)->get();この例だと、$keywordで全文検索しそれに当てはまり、かつidが1の記事を取得している。
先の説明からするとこの挙動は以下のように想像できる
-
検索条件を作成
-
LaravelのScoutを通してMeilisearchにデータを要求
-
Meilisearchからデータを返却
-
Meilisearchから返ってきたデータを利用
実際にこのような使い方もget()ではなくraw()を使えば可能ではある。
しかし通常のget()のような取得では以下のようになっている
-
検索条件を作成
-
LaravelのScoutを通してMeilisearchにデータを要求
-
Meilisearchからデータを返却
-
Meilisearchから返ってきたidを利用しMySQLにデータを要求
-
MySQLから返ってきたデータを利用
つまり何が言いたいかというと、Scoutで先のようなデータ取得方法をする限り、Meilisearchはあくまで全文検索目的で利用されているということ。
私は、Meilisearchからデータが返ってきていて、それを利用していると思っていたので苦労した。
ここから先は実際に実装しながら書いたものなので、上の前提知識が無く検討違いのことを言っているかも。
Meilisearchを使い全文検索を実装するまで
RHELでDockerを使えるようにする
Meilisearchはcomposerを使っての導入も可能なんだけど、日本語に最適化されたMeilisearchを使いたいので、人生初のDockerを使う。
日本語に最適化されたMeilisearchのDockerイメージはこちら。
それに伴い、私のAlmaLinux8にDockerを入れる必要が出てきたので入れていこう。
どうやらRHELとDockerはややっこい関係があるらしく、AlmaLinux8では公式にDockerは対応していない。AlmaLinux7だと対応というか、フォークしたRHELバージョンがあったっぽい。
一応、色々策はあるんだけど、RHELが公式に用意しているPodmanという方法で一回やってみる。
Podmanとは何か
いや、Podmanってなに? っていう状況なのでそこから。
詳しくはRedHatのPodmanとはを参照。
PodmanはDockerと同じく、Linux上でコンテナを扱うツール。Dockerを意識して作られたので、使い方とかは殆ど同じっぽい。
じゃあ、何が違うかなんだけど、主に違うのはPodmanはデーモンレスだということ。
普通、Dockerはコンテナを処理するためにデーモンとして存在している。そして、デーモンの多くはroot権限で動くのでセキュリティ上色々よろしくないよねということみたい。
そこで、RedHatから生まれたのがPodmanという感じ。
正直、そこまで理解できていないんだけど使ってみよう。
Podmanをインストールする
なんとこのPodman、とほほさんで紹介されている。
とほほさんの通りインストールする
sudo dnf install podman-docker
インストールが終わったら
docker --version

こんな感じで、dockerと入れても裏でpodmanが動くんだね。
Meilisearchを入れる
docker(podman)が使えるようになったので早速入れてみる。
まず、composerで
composer require Meilisearch/Meilisearch-php http-interop/http-factory-guzzle
を実行し、MeilisearchをPHPで扱う為のMeilisearch PHP SDKを入れる。
podman pull getmeili/Meilisearch:prototype-japanese-10
でdockerイメージを持ってこれるのかな。

なんか選べと言われた。
複数のリポジトリがあるので、どこからダウンロードするんじゃいということらしい。
恐らく、docker.ioは一般的に広く利用されているdockerのリポジトリ。
上2つのregistry.access.redhat.comとregistry.redhat.ioについては「Red Hat コンテナーレジストリーの認証」を参照してほしいんだけど、簡単に言えば、Red Hatがリポジトリを作って配布してくれているっぽい。
なかでもregistry.redhat.ioはRed Hatにログイン(恐らくサブスク?)してたら使えるやつで、registry.access.redhat.comはログインしてなくても使えるやつ。
じゃあ今回はログインしてなくても使える一番上のregistry.access.redhat.comを選ぶ。

いや選択肢に出るのに無いんかい。
無いらしいので普通にdocker.ioからダウンロードした。
podman images
で入ったことを確認。

入ったらpodman run [対象のコンテナ]で新規起動
podman run —name Meilisearch-japanese -p 127.0.0.1:7700:7700 docker.io/getmeili/Meilisearch:prototype-japanese-10
-p 127.0.0.1:7700:7700が7700番でポート開きますという意味。
—name Meilisearch-japaneseがMeilisearch-japaneseという名前で起動しますという意味。
起動したらなんか抜け出せないと思うので「ctrl+P+Q」で脱出(デタッチ)。
もし、私みたいに「ctrl+C」で切っちゃった人は
podman start Meilisearch-japanese
で既に存在するコンテナを再開。
podman psでMeilisearch-japaneseが動いていればおk。
超簡単。docker素晴らしい。
LaravelにScoutを入れる
Meilisearchが恐らく入ったのでLaravelに移る。
まず、
composer require laravel/scout
でscoutを入れる。
次に、
php artisan vendor:publish —provider=“Laravel\Scout\ScoutServiceProvider”
で設定ファイルを公開。
最後に、検索したいモデルにuse Searchableを追加。
use Laravel\Scout\Searchable;
class Article extends Model
{
use Searchable;ここからはキューを設定している場合なんだけど、検索インデックスの処理をキューで非同期処理にする。
config/scout.phpにある
’queue’ => env(‘SCOUT_QUEUE’, false),
をtrueにする。つまり、envファイルに
SCOUT_QUEUE=true
を記述。
また、ここで気づいたんだけど、queueの処理をredisに指定してなかったので、envファイルに
QUEUE_CONNECTION=redis
を追加。
もし、追加してなくても
php artisan queue:work redis
とすればredisでqueueを処理してくれるし、
config/scout.phpの
’queue’ => env(‘SCOUT_QUEUE’, false),
を
'queue' => [
'connection' => 'redis',
'queue' => 'scout'
],にすれば
php artisan queue:work redis —queue=scout
でscoutだけを処理するqueueを起動できる。
とりあえずこれでscoutの準備はおk。
Meilisearchの簡単な仕組みを理解する
Meilisearchの設定をする前に以下の仕組みを理解しておいた方が想像できるのでよいと思う。
というか、疑問がいくつかあったのでそれを調べていく。
Meilisearchって検索結果をどうやって出力するの?
そもそも、Meilisearchって検索がメインの検索エンジンなわけだけど、検索結果はどうやって出力するのだろうか。
答えは、MeilisearchがDBのコピーを内部に保持していて、それを返している。
ソースは「All fields are stored in the database.」
勿論、Laravelとの連携だとSearchableトレイトを追加したモデルだけをコピーする。
つまり、MySQLは使わない。
これ、じゃあもうMySQLMeilisearchとの違いはなんだろうってところが気になると思うんだけど主に以下だと思っている
-
リレーションを付けれるか
-
トランザクション処理できるか
-
複雑なクエリ(SQL)が使えるか
Redisとかと同じで、重要なデータというか、OriginデータはMySQLにあってそれをもとにMeilisearchはデータを扱っている感じ。
DBのコピーってどのタイミングで更新されるの?
じゃあこのコピーってどのタイミングで更新されるのだろうか。
正式なソースを見たことがないので、憶測になっちゃうんだけど、日本語ドキュメントに
「モデルインスタンスを保存または作成するだけで、検索インデックスに自動的に追加されます」「Scoutは自動的に変更を検索インデックスへ保存します」とあるから、このタイミングでデータも同期されていると思われる。
Meilisearch(Scout)でリレーションはどう扱うのか
Meilisearchの仕組みが若干分かったわけだけど、これリレーションどうすんの? という疑問はあるよね。
私の場合、Articleを検索する際に「users,tags,likes」らへんのリレーションを使うことになる。
このデータもコピーしておかないとScoutだけで完結することは出来ないだろうし、これらのリレーション先も常に新しいデータにしておかないと予期せぬ検索結果が出る可能性は全然ある。
結論から言えば、取れる対策は以下
-
ArticleをScoutから取得してから、MySQLでリレーションを取得する
ScoutもMySQLも使うハイブリッド型。一番無難だと思われる。
Scoutでの探索でリレーション先の情報が使えない欠点がある。MySQLでの探索はScoutでとってきたidの探索になるので、インデックス張ればそこまで遅くないはず。
-
Scoutにリレーションのデータを保存しちゃって使う例えば、いいね数でソートしたかったらScoutにそのデータを入れておかないとScoutで完結しないよね。だから、記事をScoutに保存するときにいいね数を予め取得していいね数もScoutに保存しておく。
欠点は、ScoutとMySQLの同期はメインのモデルが更新されたときだけなので、いいね数が記事更新時のものに固定されてしまうというもの。つまり、新しい情報にならない。
いいねが追加されたら再同期(articleをtouchする)みたいな処理を書けばこの問題を解決できるが、パフォーマンスは落ちる。
主にこの2つになるだろうと思う。
結構難しいところなんだけど、Scoutで探索するなら探索に必要な値はどちらにしろScoutに保存しておく必要があるので、それらの値は必須なのかなと考えている。
また、リレーション先の情報が同期されない対策は、touchesプロパティを使うことで解決できそうなんだけど、Meilisearchはインデックス作成にメモリをめちゃくちゃ使うのでパフォーマンスが心配ではある。
とりあえず、やってみようか。
Meilisearchのenv設定
Meilisearchの設定をしていく。
envファイルの設定は
SCOUT_DRIVER=Meilisearch
Meilisearch_HOST=http://127.0.0.1:7700
Meilisearch_KEY=masterKeyの3つを設定すればおk。
マスターキーはMeilisearchを起動したときにログに出ているので、
podman logs Meilisearch-japanese
で確認。
これ、実質APIキーってことだよね。
Meilisearch特有の設定
続いて、Meilisearch特有の設定をする。
これはconfig/scout.phpの
'Meilisearch' => [
'index-settings' => [に設定する。
Laravelのドキュメントでは「filterableAttributes」と「sortableAttributes」の2つが紹介されているが他にもいっぱいあるので注意。
Meilisearchでされている初期設定は以下
{
"displayedAttributes": [
"*"
],
"searchableAttributes": [
"*"
],
"filterableAttributes": [],
"sortableAttributes": [],
"rankingRules":
[
"words",
"typo",
"proximity",
"attribute",
"sort",
"exactness"
],
"stopWords": [],
"nonSeparatorTokens": [],
"separatorTokens": [],
"dictionary": [],
"synonyms": {},
"distinctAttribute": null,
"typoTolerance": {
"enabled": true,
"minWordSizeForTypos": {
"oneTypo": 5,
"twoTypos": 9
},
"disableOnWords": [],
"disableOnAttributes": []
},
"faceting": {
"maxValuesPerFacet": 100
},
"pagination": {
"maxTotalHits": 1000
},
"proximityPrecision": "byWord",
"searchCutoffMs": null
}重要そうな設定をみていく。
filterableAttributes
フィルタリング、つまりScoutを使ったwhere()のフィルタをかけたいカラムを入れる。
もし、いつも通りMySQLを使う$query->where()で済ませるつもりならそのカラムは入れなくていい。
私の場合、記事検索に全文検索を入れる都合上Scoutを使った検索になるので、記事検索のWhereで使うカラムはすべて入れる。
'filterableAttributes' => ['id', 'title', 'body'],ここで気になってくるのが、リレーションから持ってくる値はどうするのかというところ。
例えば、記事の全文検索と共にタグ名、ユーザー名でも検索したい場合、それらの値もScoutに保存しておく必要があるよね。
これは、toSearchableArrayメソッドを使い解決するっぽい。
toSearchableArrayメソッドでScoutに登録するカラムを変更する
やりたいことは、リレーションのカラムもインデックスに登録すること。
デフォルトでは、そのモデルのtoArrayがすべて検索インデックスに保存される。
つまり、hidden設定以外は保存されるんだねこれ。
それをカスタマイズしたい場合、そのモデルでtoSearchableArrayをオーバーライドする。
例えば、以下のようになる
/**
* モデルのインデックス可能なデータ配列の取得
*
* @return array<string, mixed>
*/
public function toSearchableArray(): array
{
return [
"id" => (string)$this->id,
"user_id" => (int)$this->user_id,
"title" => (string)$this->title,
"body" => (string)$this->body,
];
}また、この時リレーション先が複数あるとN+1が起きると思うんだけど、makeSearchableUsing()メソッドを使うと解決する。
use Illuminate\Database\Eloquent\Collection;
/**
* 検索可能なモデルのコレクションを変更する
*/
public function makeSearchableUsing(Collection $models): Collection
{
return $models->load('author');
}のようにすればeagerロードできるとのこと。
これ普通にtoSearchableArray()でやるのと何が違うんだ感はあるんだけど、ドキュメント通りにする。
これで、
Article::search(“ye”)->raw();
のようにして確認すると。
{"hits":[{"id":"01HX9R0PAWG1NFX2JZRNQ6WBNQ","user_id":1,"title":"Yey\uff01","body":"<p>CSS\u30df\u30b9<\/p>",},こんな感じで表示される。これはMeilisearchから帰ってきた検索結果。
ちなみに、
Article::search(“ye”)->get();
だとさっきのMeilisearchから帰ってきた結果をもとにDBからデータを引っ張ってきた結果、つまりモデルにあるカラムしか取得しないので注意。
sortableAttributes
これはソートの基準に使うカラムを入れておくやつ。
searchableAttributes
これは、全文検索時に参照するカラムを指定するもの。
idとかを探索されても困るので指定する。
また、指定した順序でランキングというのが決まるので、重要なもの順で指定した方がよさげ。
typoTolerance
一言でいえばタイプミスの許容度。
例えば、以下のように設定すると
"typoTolerance" => [
"enabled" => true,
"minWordSizeForTypos" => [
"oneTypo" => 6,
"twoTypos" => 12,
]
],6文字以上なら1箇所のタイポ、12文字なら2箇所のタイポまで許容するよというもの。
これ、日本語サイトの場合有効にしない方が良い気がした。
理屈はわかんないんだけど、「やっちゃった」で調べると

のようにほぼ要素が無い記事もヒットするんだよね。
日本語だとタイポってあんまり無いし、ヒットしなかったらタイポって気づくと思うから一旦無しでいく。
"typoTolerance" => ["enabled" => false],タイポ補正無くしても以下のように
「やっちゃった」で検索しても内部的には「やっ」とかで検索してるっぽく、いい感じに動く。
synonyms
同義語を設定できる。すんばらしい機能。
そういえば忘れてたけど、タグの同義語対策とかしようとしてたな。これで良さそう。
例えば、以下のようにできる。
'synonyms' => [
"DnB" => ["D'n'B", "ドラムンベース", "drum and bass", "D&B"],
"ボカロ" => ["ボーカロイド", "VOCALOID"]
],ただし、これは一方項の同義語設定なので、「ドラムンベース」と調べてDnBが出てほしい場合
"ドラムンベース" => ["DnB", "D'n'B", "drum and bass", "D&B"],も指定しておきたい。
stopWords
簡単に言えば、検索ワードを無視できる設定。
過激な言葉もそうだけど、「あ」などの短い文字も禁止できる。
インデックスしないというだけで、検索できないわけでは無いので注意。
rankingRules
これは、優先度の重みと言えばいいのだろうか。
初期値は以下
"rankingRules":
[
"words",
"typo",
"proximity",
"attribute",
"sort",
"exactness"
],つまり、この初期値だとsort指示よりwordの関連度が優先させる。
例えば、
| タイトル | いいね数 |
| 初音ミクで踊ってみた | 99 |
| 私なりのミクの調声 | 100 |
という記事があり、「初音ミク」で調べたとする。
そうするといいね順でソートしてもrankingRules的に検索ワードに近い「初音ミクで踊ってみた」が一番上に来ちゃう。
いいね順でソートしたらいいね順で表示されてほしいので、そういう場合は
"rankingRules" => [
"sort",
"words",のようにwordsよりsortを上にもっていけばおk。
Meilisearch特有の設定が終わったら
設定が完了したら
php artisan scout:sync-index-settings
で設定を同期しなきゃいけない。
これ、忘れがちな気がするので注意。
デプロイ時にも必要だね。
実際に検索ロジックを書いてみる
MeiliSrarchやらの設定が出来た気がするので、一回検索ロジックを書いてみる。
書いてみた。
検索してみると
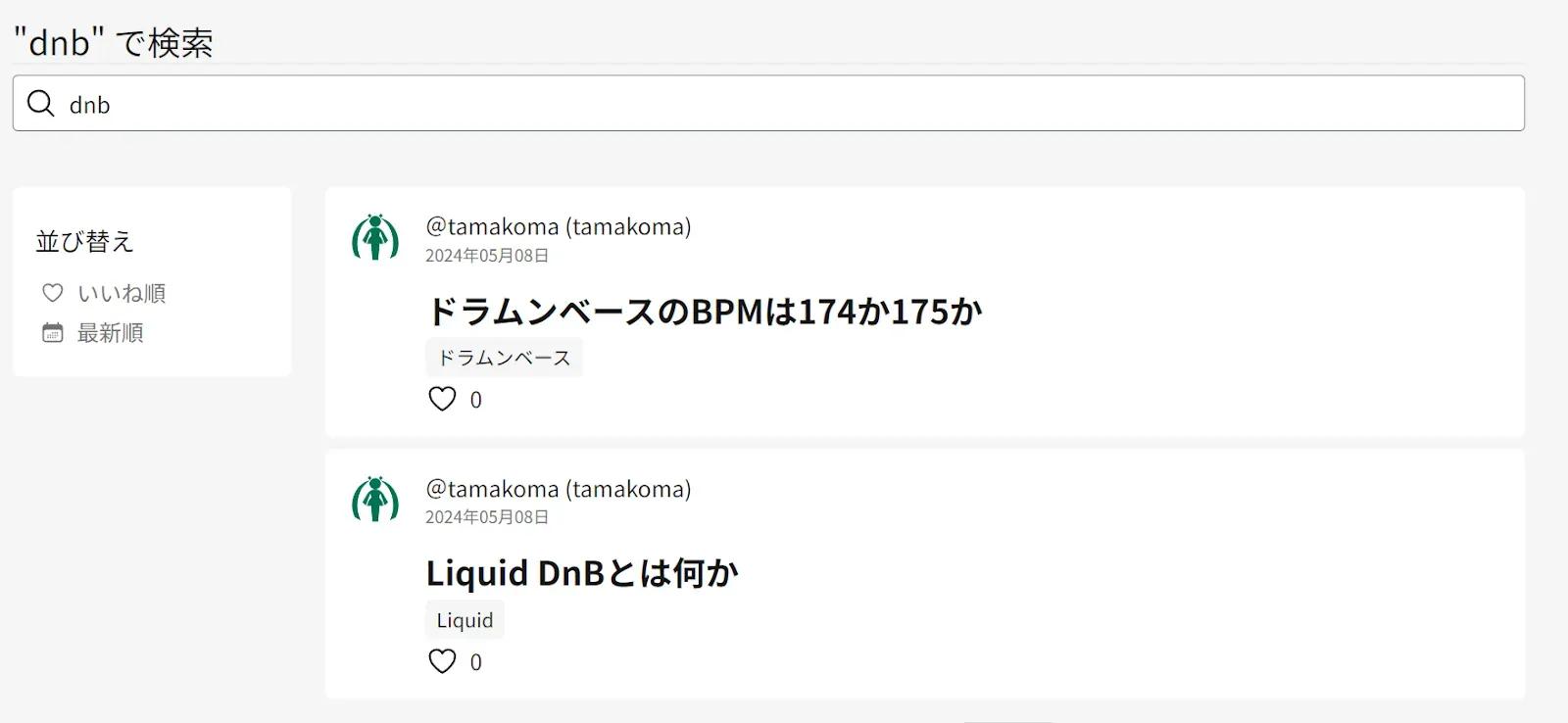
すごい! できてる!
現時点での探索パフォーマンス
一応、取得はできたんだけど、MeilisearchとMySQL間でどれだけデータを同期させるかが問題になってくる。
データの同期・インデックス作成がすぐ終わるなら全然問題ないんだけど、リレーションの取得にMySQLを動かす関係もあってかかなり遅い。
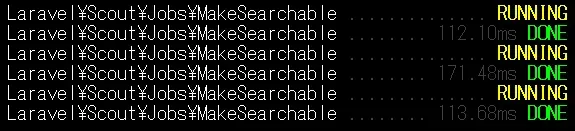
1回の同期で150msかかるということは、1秒間に6~7回程度しか捌けないってことだよね。
勿論マシンのスペックにもよるだろうけど、全てを同期するにはちょっと厳しい気がする。
一回テストで記事のデータを1万件追加してみる。
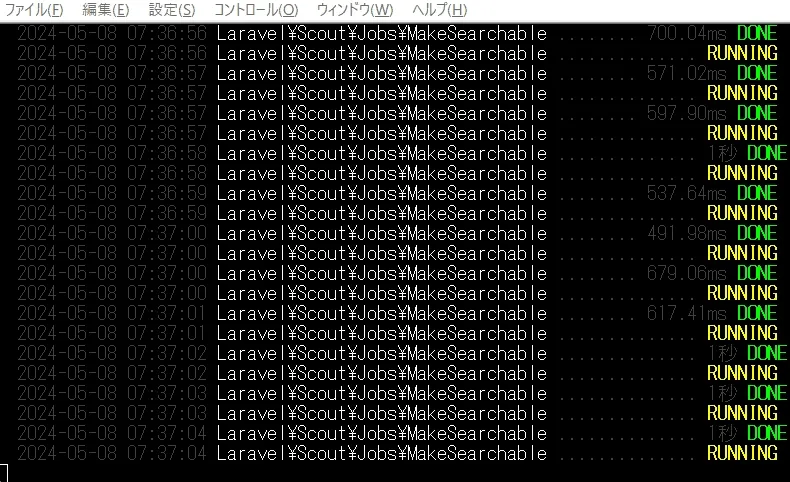
いやこれ終わらん。
このままだと1時間以上はかかりそうなので、DBをいったんリセット。
1万件追加した後に、バッチ処理で追加してみる。
php artisan scout:import “App\Models\Article”
で一気に読み込める。
恐らく、内部で同期のバッチ処理みたいなのをしてくれていて、10秒くらいで終わった。
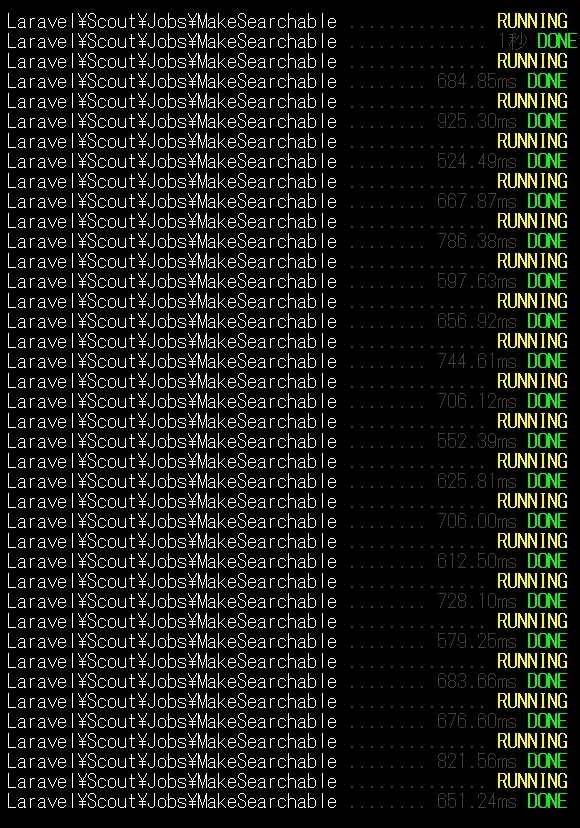
やっぱりMeilisearchが遅いんじゃなく、MySQLを含めたI/O処理の固定費みたいのがある程度あるから頻繁な処理にすると遅いっていう感じだろうか。
1万件からの検索のは以下のような感じ。
遅い。
ちなみに、1万件の時に記事を作成してもだいたい600~1000msくらいで同期はしてくれる。

メモリ2GBのVMなのでこんなもんな気もしなくもないんだけど、ちょっと分析したい。
改善できそうなところを考える
前使ったblackfireでボトルネックを見る。

なんと4秒もかかってる。
どうやら、クエリで記事をすべて取得してるところがあって、そこが遅いっぽい。そりゃ1万件も取ったら遅いわ。
どこでそんな処理してるんだろうと思ったら、どう考えても異常なところを複数発見。
「in ( 1,1,1,1, … ,1)」が恐らく1万件続いてる。
なんだこれ。
しかも、複数ある。
よくわからんので、Meilisearchを可視化してみる。
Meilisearchの可視化
可視化する為、dockerで入れなおす。
podman stop Meilisearch-japanese
podman rm Meilisearch-japanese
で削除。
runコマンドは以下
podman run \
--name meili-jp \
-p 127.0.0.1:7700:7700 \
-p [ホストオンリーネットワークのIP]:7700:7700 \
-e MEILI_ENV='development' \
-e MEILI_MASTER_KEY='aSampleMasterKey' \
getmeili/Meilisearch:prototype-japanese-10説明は
-
--name meili-jp \名前付けてる。meili-jpでアクセス可能に。\でコマンドを複数行に区切ってる。 -
-p 127.0.0.1:7700:7700 \と-p [ホストオンリーネットワークのIP]:7700:7700 \
指定のIP・ポートでアクセスできるように。ホストPCからアクセスするので。 -
-e MEILI_ENV='development' \
開発モード。これでデバッグができる。 -
-e MEILI_MASTER_KEY='aSampleMasterKey' \
キーの指定。
という感じ。
podman start meili-jp
で起動したら、
sudo firewall-cmd —zone=public —add-port=7700/tcp —permanent
sudo firewall-cmd —reload
で7700番を開放。
[ホストオンリーネットワークのIP]:7700でアクセス。
アクセスすると
こんな感じになるので’aSampleMasterKey’を入力。
すごい、記事1万件あっても4msで探索してる。驚愕。
うん、当たり前ではあるんだけどSearch Previewはサーチのプレビューをしてくれるだけで、あんまり手がかりはなかった。
とりあえず、内部でMeiliSarchがめっちゃ早く動いていることはわかった。
謎のidが1のクエリがめちゃくちゃ生成される謎に迫る
これ、色々見てて思った仮説なんだけど、以下を見てほしい。
0 => "01HXAM7J8346Y4KEA0061Z2G2D"
1 => "01HXAM7KWGWYC66AXRQ6525N4A"
2 => "01HXAM7M4HXTSDBF9ESFN4RG8Y"
3 => "01HXAV0ESJGG77TC35W95WBYJV"
4 => "01HXAM7HRP1Q7WK7MFMHASSXHG"
5 => "01HXAM7KC43EFAFNJZF0KD5X2C"
6 => "01HXAM7KSZRVAQ5YFT1TZ1ZEV3"
7 => "01HXAM7J3P0XDRH20W9RBHN2KZ"
8 => "01HXAM7J74VQ02BXASBGWXEPNY"
9 => "01HXAM7K8SNTGB4KFS5T9M31ZW"
10 => "01HXAM7HXVYN21HWJJDBZTZX2K"
11 => "01HXAM7J76Z8T8W8MQRP9Q7ZGS"
12 => "01HXAM7JWT12XNVFSNH5C587FA"
13 => "01HXAM7JA0Y7SYD58XGTVZP0R1"
14 => "01HXAM7K3XPHHNR31MRF1MJ249"
15 => "01HXAM7KK79FDGAEGBKF0R7R4M"
16 => "01HXAM7KM8NZ5F63C7GKD4VR27"
17 => "01HXAM7KYAQ6JKHNR9T250B65R"
18 => "01HXAM7M20KF3KRZEQCKE52728"
19 => "01HXAM7KN14CFD58ZZD4HFPS43"これはULIDの一覧。
全て01から始まってるよね。
これ、どっかでIDをintで扱って01以降が消えてるのではと思った。
それで色々調べてたら日本語ドキュメントにこんな記述が
モデルの主キーが整数でない場合は、モデルにprotectedな$keyTypeプロパティを定義する必要があります。このプロパティの値はstringにする必要があります。
知らなかった。
試しにArticleのモデルに
protected $keyType = 'string';を入れたら…
解決したぁ。
めっちゃ初歩的なミスだったなぁ。
つまり、ULIDで主キーを実装するなら
public $incrementing = false;
protected $keyType = 'string';が必須なんだね。
この設定をしたら速くは無いけど許容範囲くらいで動くようにはなったのでおk。

Scoutを使うとペジネーションが正常に動かない現象
無事クエリは改善できたけど、ペジネーションの問題が。
さっきクエリでarticle_id==1をずっと取得し続けようとするクエリがあったけどあれは治っていなかった。
ペジネーションがバグって全記事の数を取得しちゃってるっぽい。
卵が先か、鶏が先かみたいなペジネーションバグが先か、全記事取得が先か問題はある。
これ、何だろうと思ったら普通にMeilisearchとScoutの相性問題っぽい?
参考元
-
GitHub issue「Meilisearch engine pagination total broken 」
いや、更に調べると今が旬のバグのっぽい。
- GitHub issue「Incorrect Total Count in Laravel Scout Pagination 」

1個だけIssue開いてるのが正にそう。
Scoutを使うとペジネーションが正常に動かない現象の現時点での解決策
issue見る限り普通にバグっぽいのでScoutが修正してくれるのを待つのが得策ではあるんだけど、一応回避策としてあるのは、一回対象記事のIDだけを取得しMySQL経由で取得するというもの。
2度手間感は否めなくもないんだけど、責任の分割としてScoutは記事の全文検索を、MySQLは記事の取得をという意味では一番自然だと思った。
つまり、以下のようなコードは
$articles = Article::search($keyword)
->paginate(config("const.pagination.perPage"));以下のようにできる
// Scout #824 のissueでペジネーションの問題があるので、記事の取得はMySQLからするように
$ids = Article::search($keyword)
->keys()->toArray();
$articles = Article::query()
->paginate(config("const.pagination.perPage"));こうすれば普通にMySQLから記事を取得できるのでペジネーションは正常に動く。
Scoutを使うとPaginateがバグる現象について(追記)
色々弄ってたら、私の環境での発生条件がわかった。
-
モデル主キーがULIDであること
-
protected $keyType = ‘string’;をモデルに指定していないこと
-
ドライバにMeilisearchを使っていること
が条件で私の場合は発生している。ドライバはMeilisearch以外でも起こるかも。
実際にみると以下のような感じ
issueに実際報告してみる
そろそろOSSを享受するだけでなく、貢献くらいしたいという気持ちがあるので、この発生条件を報告してみようと思う。
まじで見当違いだったら恥ずかしいし、そもそも初歩的な間違いすぎて恥ずかしいけど、これから先もやりたいのでやろう。
一応、貢献の仕方みたいなドキュメントはあるので、それを読みつつやる。
とりあえず日本語で文章書いて、DeepLやChatGPTに添削してもらった。
めっちゃ恥ずかしいし怖いけど、とりあえず報告してみた。
間違った報告、見当違いの報告だったとしても何かしらの情報ではあると思うので、これからは出来るだけこういうのは積極的に報告していければと思う。
今思うと報告のわりに文章長かったかな。
検索インデックスを付ける基準を設ける
初期設定だと、articlesの処理すると自動的に同期して検索インデックスに保存されるようになっている。
しかし、そもそもBANされている記事やpublicじゃない記事は絶対に使わないのであれば検索インデックスに入れる必要が無いよね。
そんな検索インデックスに入れる入れない設定ができるのでやろう。
public function shouldBeSearchable(): bool
{
return $this->isPublished();
}のようにこのメソッドの返り値がtrueだった時だけ検索インデックスにインデックスするみたいなことができる。
つまり、
public function shouldBeSearchable(): bool
{
return $this->isPublic() && $this->isNotBan();
}のようにすれば記事がPublicかつBANされていないときだけ検索インデックスに入れるようにできる。
これ、PublicのものがDraftとかに変わったらどうなるんだろうか。
どうやら、以下のようにshouldBeSearchableがfalseだとRemoveFromSearchが動きIndexから削除され、trueならMakeSearchableが動きindexに追加されるということみたい。

既にindexから削除されていたとしてもこのJobは動くので、Job削減には繋がらなさそう。
DBのidにインデックスは張ってあるのか
Scoutは全文検索のみで扱い、検索結果のID配列からMySQLで再取得することにしたんだけど、これIDって初期からインデックス張ってあんのかなて疑問に思ったので。
PhpMyAdminを見る感じ、idというかキー系には勝手にインデックス張ってあるっぽい。
というか、日本語ドキュメントにあった。
以下はインデックスを張るみたい。
| コマンド | 説明 |
| $table->primary('id'); | 主キーを追加 |
| $table->primary(['id', 'parent_id']); | 複合キーを追加 |
| $table->unique('email'); | 一意のインデックスを追加 |
| $table->index('state'); | インデックスを追加 |
| $table->fullText('body'); | フルテキストインデックスを追加(MySQL/PostgreSQL) |
| $table->fullText('body')->language('english'); | 特定言語のフルテキストインデックス追加(PostgreSQL) |
| $table->spatialIndex('location'); | 空間インデックスを追加(SQLiteを除く) |
最終的な全文検索の実装について
なんかめっちゃ長くなったのでまとめる。
リレーションについて
実装で厄介になるのがリレーションだと思う。
いいね数やユーザーがBANされているか等を検索条件に入れたいんだけど、Scoutでこの値を管理しようとすると、「usersやlikesの特定の値が変わったときだけ同期する」という処理が欲しくなる。
この処理はできなくはないんだけど、管理するものが増えることになるので後の負債になりそう。
逆に、MeilSearchには最低限のデータだけを保持し、$queryを使っていいね数やユーザーがBANされてるかをフィルターすることはできなくはない。
しかし、これにも弱点がある。
それがペジネーションとソート。
どうやらソートやペジネーションは検索エンジンの結果をもとに生成しているらしい。そして、このコールバック$queryは日本語ドキュメントにもある通り
このコールバックは、関連モデルがアプリケーションの検索エンジンからあらかじめ取得された後に呼び出されるので、queryメソッドを結果の「フィルタリング」に使用しないでください。代わりに、Scout WHERE句を使用してください。
とのこと。
つまり、with()とか専用。whereとかソートをここでするとペジネーションやほかの部分でバグる可能性が高い。というかバグった。
じゃあどうするかなんだけど、やっぱりScoutで検索条件系の状態は常に保持しておく必要がありそうなので、全て同期させていく方針でやっていく。
Meilisearchの自動同期はどのタイミングで発火するのか
use Searchable;を付けたモデルはその内容が変わる度にMakeSearchableまたはRemoveFromSearchジョブが働き、内容が同期される。
これ、どのタイミングかなんだけど、モデルを通して
-
saved
-
deleted
-
forceDeleted
-
restored
が実行されたときに同期される。ソフトデリートを使ってないならsavedかdeletedの時だけ発火するってことだね。
この発火関連のソースコードは「vendor/laravel/scout/src/ModelObserver.php」にある。
つまり、逆に言えばこれらが発火しない限り自動的に同期されることはない。
ということは、リレーション先が変わった時、カスケード処理、モデルを通さない処理をしたときにデータの不一致が起こる可能性がある。
Scout(Meilisearch)とのデータ整合性をどうとるか
上で発火タイミングの説明をした通り、
-
リレーション先の値が変わったとき
-
カスケード処理で削除された時(モデルを通さずに削除される)
-
他のモデルを通さない処理をしたとき
にデータ整合性が取れなくなる可能性がある。
これ以外にも私が見逃しているだけでこれ以外にもデータ整合性を取れなくなるタイミングはありそう。
私が思いつくこれ等に対する対応方法は、
-
自動同期が発火しない変更タイミングをしらみつぶしに探し、同期するコードを書く
-
ある程度の不整合は妥協し、定期的に全ての同期を取り直す
のどちらかかなと思う。
今回の実装ではどちらも使って整合性をとっていこうと思う。
Meilisearchに同期させるもの
ScoutではtoSearchableArray()でどの値をどんなカラム(フィールド)名で同期させるかを指定できる。
同期させる値を使い全文検索、絞り込み、ソートを行うのでこれ等に使う値は必ず同期させなきゃいけない。
一番楽なのは全てを同期させることだと思う。先にも言った通り、savedかdeletedをしたら必ず同期処理は発火するので、全部同期させちゃっても良いと感じた。
ただし、外部との同期に気を付けなきゃいけない。
これ、どうやって同期取るかなんだけど、
$user->articles()->searchable();でMakeSearchableのJobを
$user->articles()->unsearchable();でRemoveFromSearchのJobを発火できる。
その為、Userモデルで以下のような定義をした
protected static function booted()
{
parent::boot();
static::updated(function ($user) {
// Meilisearchと同期
if ($user->wasChanged('カラム')) {
$articles = $user->articles()
->with('user')->get();
$articles->searchable();
}
});こんな感じで、特定のカラムが変わったら同期取るようにする。
注意点は、$articles->searchable()だと全ての記事をインデックスしちゃうからしっかり絞ってからインデックスするように。
カスケード処理時にデータ同期する
ユーザー退会時、ユーザーが削除されると同時に関連記事も削除される。
これはいちいちモデルを読み込んで削除しないので、同期イベントが発火しない。
なので、こちらも
static::deleting(function ($user) {
// Meilisearchと同期
$articles = $user->articles()->with('user')->get();
$articles->unsearchable();のように削除に伴いunsearchable()を実行する。
定期的にデータを同期する
以上の対策だけだと、手動でDBを弄ったときや予期せぬデータ不整合に対応できない。
Meilisearchは幸いインデックスにそこまで時間がかからないので、定期的にデータをfreshし同期しなおすという動作を行う。
記事1万件でだいたい4秒くらいだったので、そこまで問題ないだろうと踏んでいる。
わからんけど以下のような感じでいいのではないだろうか。
public function handle()
{
$chunkSize = 1000;
$cnt = 0;
Article::removeAllFromSearch();
Article::query()
->where("任意の絞り込み")
->with("user")
->chunk($chunkSize, function ($articles) use (&$cnt) {
$articles->searchable();
$cnt += count($articles);
});
$this->info("計{$cnt}個の記事を処理");
$this->info('Scoutのflushとimportを完了しました');
}記事の総数は大きくなる可能性があるのでchunkで分割している。
とりあえずなんやかんやでできた。
記事検索のテストを作る
考えなきゃいけないことが多いし、そもそもどうやってテストするのという疑問があるのでここにまとめる。
テスト中のMeilisearchやジョブはどう処理されるのかなんだけど、結論から言えば.envの設定による。
-
phpunit.xmlに
<env name="APP\_ENV" value="testing"/>があれば.env.testingが利用され、.env.testingがなければ.envが利用される。 -
その環境が読み込まれた上でphpunit.xmlに設定された
<env name="DB\_DATABASE" value="qtm\_test"/>で上書きされる。
その為、Meilisearchの設定があれば普通にそのMeilisearchとインデックスは同期される。
ジョブも普通にキューされ処理されるが、<env name="QUEUE\_CONNECTION" value="sync"/>を設定していると同期処理になるのでそれが良さそう。
じゃあ実際に何をするかというと
phpunit.xmlに
<env name="SCOUT_PREFIX" value="test_"/>を追加する。
こうするとテスト実行時にtest_○○でインデックスを作成してくれる。
次にTestCase.phpに
protected function setUp(): void
{
parent::setUp();
// setUpBeforeClassだとArtisanファザード使えなかったので
if (!self::$setUpHasRunOnce) {
// Meilisearchの設定を適用
Artisan::call('scout:sync-index-settings');
self::$setUpHasRunOnce = true;
}
// Meilisearchのデータクリア
Article::removeAllFromSearch();を入れる。
Article::removeAllFromSearch();はテスト実行毎にMeiliserachのインデックスをflushするもの。
if (!self::$setUpHasRunOnce) {
// Meilisearchの設定を適用
Artisan::call('scout:sync-index-settings');
self::$setUpHasRunOnce = true;はmeiliserachの設定を同期するもの。
setUpBeforeClassというのを使うと最初の1回だけ実行してくれるんだけど、Artisanファザードがセットされていなくて使えなかったのでごり押し実装。
これで後は普通に実装すればMeilisearchはテスト環境で実行されるんだけど、インデックスに少し時間がかかるっぽくて、sleep(1)くらい必要なので注意。
非同期処理のテストをできるだけ正確にアサートするにはどうするか
Meiliserachでインデックス処理が行われるまでsleep(1);で待ったりもできるんだけど、いかんせん不安定。
sleep(1);だとインデックス完了するときもあるし、してないときもあるんだよね。
ちょっとどうにかできないかなということで、ChatGPTから出てきた対策がポーリングによる動的待機。
ポーリングというのは、一定間隔毎に問い合わせる、監視するみたいな意味があるっぽい。
つまり、一定間隔事にMeiliserachからデータを取得し、特定の条件を満たせば次に進むよみたいな。
こっちのほうがいいね。
一応以下に置いとく。TestCase.phpとかで宣言して使う想定。
protected function waitForIndexingToComplete(
$model,
string $searchWord,
int $expectedCount,
int $timeout = 10
) {
$startTime = microtime(true);
while (true) {
$result = $model::search($searchWord)->get();
if (count($result) == $expectedCount) {
return;
}
if (microtime(true) - $startTime >= $timeout) {
throw new \Exception("インデックス完了前にタイムアウトしました");
}
usleep(500000); // 0.5秒待つ
}
}以下のように使うことで確実にMeilisearchが準備完了してからそれ以降の処理に移れる。
$this->waitForIndexingToComplete(Article::class, "DTM", 5);最終的な記事一覧
トレンドとタイムラインの2つを作り、記事検索はScoutとMeilisearchで全文検索を実装した感じ。
トレンド
タイムライン
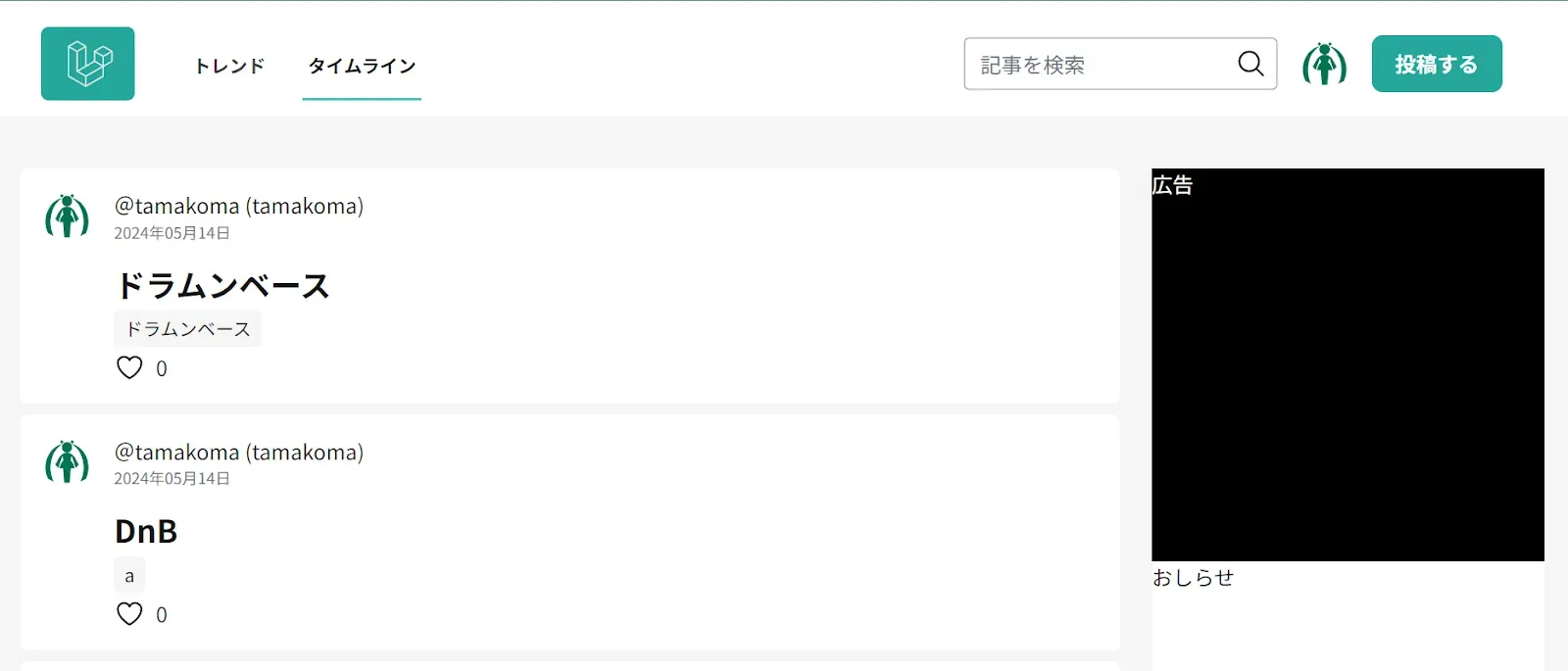
記事検索
見た目は最低限。レスポンシブ対応も最低限した。
ユーザー通知機能を作る
ガイドライン違反で記事を修正してほしいとき、配信の一時停止をしたいときにユーザーへの通知機能があった方が良いよね。
できればいいねとかの通知も送りたいね。
理想は
-
通知ログは一生残る。カスケード処理しない。
-
重要な通知は通知したと同時にメールにも通知したい
-
運営→ユーザーへの一方通行の通知
-
通知が来たらナビゲーションバーにわかるようにしたい
-
管理画面からできるようにしたい
見た目はQiitaやSoundCloudと同じでよいのではと思っている。


ユーザー通知機能の設計が思ったより深い
なんか最初は、以下のようなデータベースを作り、
-
id通知のid
-
user_id通知先のid
-
type通知タイプ。通知クラス名を入れる。
-
data通知する際に必要なデータ(「いいね」の通知なら、誰が何にいいねしたのかのデータなど)
-
read_at既読日
-
created_at作成日
適当に管理すればいけるんじゃないかと思ってたんだけど、かなり考慮できるところが多い。
参考元は
要件
-
プッシュ通知ではなく、サイトにアクセスしたときに受動的に引っ張られるプル通知
-
今のところ、いいね、こちらから個人へのお知らせ、こちらから個人への警告系に利用予定
-
特定の通知は対象ユーザーが削除されても永久的に残したい
機能として含めようとしたけど、しなかったもの
-
時間経過で通知の自動削除
ツイッターやインスタ等のSNSほど流動性が高いサービスではないので、必要ないと判断。 -
複数のいいねをまとめて表示上と同じ理由。あとややこしい。
-
全体的なお知らせ
運営から全ユーザーへの通知になると、それだけ通知レコードを発行しなきゃいけなくなる。
これを解消する為、user_id==0を全体として管理したりしようかと思ったんだけど、こちらもややこしさが生まれるのと、既読の管理で別のテーブルが必要になるのが×。
その為、全体へのお知らせはメインページやメールを送るのが丸い。
報告系データはcascadeするか
以前のレポート機能もそうだったんだけど、このような報告系データは削除したくない気持ちがある。
この報告系、通知系は複数の人が関連している可能性が高いので、片方のユーザーが消えたらそれに関連する報告・通知データがすべて消えるのはどうなんだろという考え。
でも、完全に残すとしても懸念点があって
-
外部キー制約を受けられない削除されているのにデータがあるということは外部キー制約に違反するので、外部キー制約に頼らない設計にする必要あり。
-
論理削除にすれば外部キー制約受けられるかもだけど、論理削除自体あまりしたくない
論理削除はややこしさも上がるし、容量食うしであまりしたくない。 -
容量圧迫報告と重要な通知系のみだったら極僅かだと思うので、そこまで問題ない。
-
プライバシー
日本であれば必要な情報は保持できるので変な使い方・漏洩とかしなければ問題は無いはず。
という問題がある。
前回のレポートとかは残して良いと思ったんだけど、今回の通知の場合、重要な通知は規約違反者に対する警告とかだと思う。
でもそれを通知しましたっていう記録の保存は通知が担うところではないかなと思った。
また、そういう重要な通知はメールでもすると思うので、記録に残る。
じゃあこの通知はcascade付けて良いかという判断をした。
Laravelの通知システムをちょっとだけ覗いてみる
最初はドキュメントに書いてあるデータベース通知を実装しようと思ったんだけど、これがあまりに自由度が低い。
「【Laravel】 通知に関する補足と拡張の手引き」の記事を読んでもらうとわかるんだけど、このデータベース通知を実装しようとするとソースコードを弄ったり拡張しないとデータベースの形は「php artisan notifications:table」で生成されたもの固定だし、idも指定される。
恐らく、メールや他の通知にも汎用的に扱えるように、データベースファーストの考えではないからこのような実装になっているんだけど、ちょっと使いづらい。
簡単にデータベース通知の流れを上の参考記事を焼きなおして説明する。
まず、UserモデルなどにNotifiableトレイトを入れると
trait Notifiable
{
use HasDatabaseNotifications, RoutesNotifications;
}のように、HasDatabaseNotificationsとRoutesNotificationsトレイトの2つが使えるようになる。
HasDatabaseNotificationsトレイトはリレーション先から通知一覧を取得するコード。
RoutesNotificationsトレイトはQueueに通知をディスパッチするコードが書かれている。
ここで注意なのが、HasDatabaseNotificationsの中のコードは
public function notifications()
{
return $this->morphMany(DatabaseNotification::class, 'notifiable')->latest();
}のようにポリモーフィック前提のコードになっているので、私のようにuser_idとのリレーションにしている場合動かない。
また、この「DatabaseNotification::class」を見てみると以下のようになっている。
class DatabaseNotification extends Model
{
protected $keyType = 'string';
public $incrementing = false;
protected $table = 'notifications';
protected $guarded = [];
protected $casts = [
'data' => 'array',
'read_at' => 'datetime',
];
public function notifiable()
{
return $this->morphTo();
}つまり、テーブルの構成はある程度指定されてしまっている。
テーブル名は’notifications’じゃなきゃいけないし、主キーはstringの非増加型じゃなきゃいけない。
更に$castsにdataやread_atの型が指定されており、これ等のカラムが無い場合や型が違う場合エラーになる可能性がある。
すなわち、テーブルの自由度がひっくい。
続いて、通知を
$user->notify(new LikedArticle($article));
で行うとする。
するとRoutesNotificationsにある以下のコードが実行される。
public function notify($instance)
{
app(Dispatcher::class)->send($this, $instance);
}つまり、通知クラスと自分自身(今回ならUser)を引数に受け取っている。
このsendがどこに行くかというと、「NotificationServiceProvider」で
$this->app->alias(
ChannelManager::class, DispatcherContract::class
);のようにバインディングされている通り、以下のChannelManagerのsendメソッドに行く。
public function send($notifiables, $notification)
{
(new NotificationSender(
$this, $this->container->make(Bus::class), $this->container->make(Dispatcher::class), $this->locale)
)->send($notifiables, $notification);
}このメソッドでは更に以下のNotificationSenderのsendメソッドに送ってる。
public function send($notifiables, $notification)
{
$notifiables = $this->formatNotifiables($notifiables);
if ($notification instanceof ShouldQueue) {
return $this->queueNotification($notifiables, $notification);
}
$this->sendNow($notifiables, $notification);
}このコードでは「$notification instanceof ShouldQueue」が定義されていれば、Queueの非同期処理を、そうでなければsendNow、つまり同期処理をしている。
今回は非同期処理の処理を追ってみる。
protected function queueNotification($notifiables, $notification)
{
$notifiables = $this->formatNotifiables($notifiables);
$original = clone $notification;
foreach ($notifiables as $notifiable) {
$notificationId = Str::uuid()->toString();
foreach ((array) $original->via($notifiable) as $channel) {
$notification = clone $original;
if (! $notification->id) {
$notification->id = $notificationId;
}
if (! is_null($this->locale)) {
$notification->locale = $this->locale;
}
$connection = $notification->connection;
if (method_exists($notification, 'viaConnections')) {
$connection = $notification->viaConnections()[$channel] ?? null;
}
$queue = $notification->queue;
if (method_exists($notification, 'viaQueues')) {
$queue = $notification->viaQueues()[$channel] ?? null;
}
$delay = $notification->delay;
if (method_exists($notification, 'withDelay')) {
$delay = $notification->withDelay($notifiable, $channel) ?? null;
}
$middleware = $notification->middleware ?? [];
if (method_exists($notification, 'middleware')) {
$middleware = array_merge(
$notification->middleware($notifiable, $channel),
$middleware
);
}
$this->bus->dispatch(
(new SendQueuedNotifications($notifiable, $notification, [$channel]))
->onConnection($connection)
->onQueue($queue)
->delay(is_array($delay) ? ($delay[$channel] ?? null) : $delay)
->through($middleware)
);
}
}
}コードは長いけど、やってることは単純で、Notifiableでforeach回し、Channelでもforeach回し、全てのパターンでJobを生成している。
つまり、user1とuser2がNotifiableに存在し、mailとdatabaseがChannelに存在すれば2*2の4回Jobが生成される。
そして大事なのが以下の部分
foreach ($notifiables as $notifiable) {
$notificationId = Str::uuid()->toString();
foreach ((array) $original->via($notifiable) as $channel) {
$notification = clone $original;
if (! $notification->id) {
$notification->id = $notificationId;
}「$notificationId = Str::uuid()->toString();」でUUIDを生成し、
if (! $notification->id) {
$notification->id = $notificationId;
}でidを指定している。
古いUUIDは時間軸のソートができないので、キャッシュ効率が悪いらしくあまり使いたくない。その為、ULIDにしたいところ。
参考記事だとIDの変更はソースコードを直接弄らなきゃいけないぽかったんだけど、Laravel10だとソースコードが変わり「if (! $notification->id) {」のようにidを予め指定すればそのIDを使うようになっている。素晴らしい。
そして、queueから取り出すときはSendQueuedNotificationsのhandleメソッド
public function handle(ChannelManager $manager)
{
$manager->sendNow($this->notifiables, $this->notification, $this->channels);
}のように同期処理のsendNow()と合流するという感じ。
これらのことを考慮すると以下のようなことが言えそう
-
notificationsはポリモーフィックを前提に設計されており、これを覆すにはソースコードから変えなきゃいけなさそう
-
テーブル名もnotificationsで指定されているので、これを上書きするにもソースコードから変えなきゃダメそう
-
idはデフォルトでUUIDだが、ULID等の好きなString型IDにできそう
-
元の設計ではポリモーフィックという性質上、データが永遠に残る設計になっている
-
cascadeなどが設定できないが、「$this->morphMany(DatabaseNotification::class, ‘notifiable’)->latest();」のように取得する性質上、問題ない
Laravelの通知システムを考慮した上でのシステム再設計
Laravelの通知システムを利用したシステムを作るには色々制約があることがわかった。
ここで私が取れる選択肢は以下の4つ
-
初期のnotificationsテーブルを使う誰からの通知か、同じ通知を既に送っているかがわからない。
-
リソースを持ったnotificationsテーブルを使うこちらのやり方。
直観的だが、1つのテーブルにポリモーフィックが2個あることになるのが怖い。
また、データの存在ケアや、Eagerロード対応が面倒そう。 -
オーバーライドしたり継承してオリジナルのテーブルを無理やり使う今は良いけど、将来の負債になる可能性大。
-
Laravel通知システムを使わない1から設計する必要があるけど、オーバースペックにもならず最低限の実装ができるので良さそう。
その代わり、Laravelの通知システムの機能を使えないのがデメリット。
自分で作るので責任も増える。
うーん。どうしてもLaravelの通知システムを介すると無理が出てくるので今回は自作することにする。
簡単なものを目指し、単純化できるところはできるだけ単純化する。
自作部分はブログにのっけないけど、通知といってもDatabaseに保存するだけなのでそんな特殊なことはやってない。
通知を閲覧する画面
本当はQiitaやNoteみたいな非同期のかっこいい通知閲覧画面にしたいんだけど、まだAPIの扱いになれていないので通知専用の画面を作りそこで閲覧する方式にする。
ペジネーションなどを使い簡単に以下のような感じにした。
Qiitaをめっちゃ参考にしたので、ほぼ同じ。
これに運営からの通知もできるようにする。
運営からの通知はとりあえずCSSで生成するグラデーションアイコンにした。
未読通知数をビューコンポーザで取得する
ナビゲーションバーに以下のようなよくある通知ボタンを追加した。

通知テーブルには既読カラムがあるので、既読数を見れるようにしたい。
Viewで「{{auth()->user()->Notifications()->count()}}」のようにしても数は取得できるんだけど、ViewでカウントするのはMVCに反するのでやりたくない。
かといって、コントローラーで毎回取得するのかというとナビバーを使うコントローラーすべてに入れる必要があるし、面倒だよね。
そこで便利そうなのがビューコンポーザ。
日本語ドキュメントそのままもってくると
ビューコンポーザは、ビューをレンダするときに呼び出すコールバックまたはクラスメソッドです。ビューをレンダするたびにビューへ結合するデータがある場合、ビューコンポーザを使用すると、そのロジックを1つの場所に集約できます。ビューコンポーザは、アプリケーション内の複数のルートかコントローラが同じビューを返し、常に特定のデータが必要な場合にきわめて役立ちます。
つまり、特定のビューを読み込むときのロジックを書ける。
利用例的には、AppServiceProviderなどのboot()メソッドに
Facades\View::composer('layouts.navigation', function ($view) {
$user = auth()->user();
if ($user) {
$unreadCount = $user->unreadNotifications()->count();
$view->with('unreadCount', $unreadCount);
}
});のようなメソッドを書く。
こうすると、layouts.navigationのviewをレンダリングする際にこのロジックが処理されunreadCountの値が使えるようになるという感じ。
これで以下のようにできた。
 |  |
かなり無難だけど分かりやすいし良いと思う。
とりあえずなんだかんだで通知システムは完成。
本当の本当に、システムの実装関連で最低限やることは無くなったのでは。
おわりに
とりあえずシステム実装関連は本当にもう最低限やることは無くなった。
後はサービス名決めてインフラやればサービス開始できる。
サービス名決めるのに難航していて、むずむずしている。
サービス名って無くてもサービスは成立するはずなのに、大事なところだから無下にもできないというジレンマ。