2023年6月10日
はじめに
機械学習の目標がとりあえず定まった。
-
学生、独学でもできそうな規模、難易度
-
実際に私の役に立つもの(モチベーションにもなるし)
-
データの収集が難しくない
-
データの形が難しくない
-
機械学習じゃないとできないこと
を条件に色々題材を考えたんだけど、まじで難しいんだこれが。
なんだかんだ色々考えて、今は”音の分類”という題材に落ち着いた。これなら、機械学習の基礎であり、本質でもあると勝手に私は思っている分類問題にできるし、シンプルで何となくやるべきことがわかるからとっかかりやすい。
何故音の分類問題を選んだか?
私自身音楽を作るんだけど、私達DTMerはSpliceとかそういうサイトから音源をめちゃくちゃダウンロードする。実際にSpliceでは一番安いプランでも月に100個くらい音源をダウンロードできて、この管理が難しい。実際に、HDD/SSDにフォルダを作りまくって手動で管理している人が大半だと思う。
そこで、音源に自動的にラベルを付けて管理してくれるソフトがあったら滅茶苦茶便利じゃないかと考えたのが選んだ理由。なんか既にありそうなんだけど、これが調べて見ると意外とない(難しいのかな? というか地味すぎ?)。一応Music Information Retrieval、略してMIRとして研究されてはいるらしい。
これであれば、この音源がピアノか否かみたいなシンプル化、小規模化もできるし、データも音源であればいいから収集が難しくない。また、集めるデータの形もとりあえず波形になればいいからmp3とかwavとかで問題ない。しかも役に立つ。とりあえずこれでいいんじゃないかな。
まず何からするか。
MIRの情報を集める
まじで何からしよう。とりあえず、MIRの情報を集めよう。
実際にGoogleで「Music information retrieval」と調べても英語記事しか出ない。まあ、そりゃあ英語で調べてるから当然ではある。因みに、MIRという言葉はChatGPT-4から仕入れた。
DeepLを使って無理やり英語記事を読むこともできるんだけど、とりあえず易しい情報が欲しいので日本語記事を探し、読む。
2021年11月にNoteで大学院生さんが分かりやすく解説してくれている記事があったのでこれで情報収集。
見たところによると、MIRは
-
音楽データから情報を抽出、その情報を検索に使えるようにする技術
-
様々な学問で構成されている学際的研究分野。音楽学、音響心理学、物理学、信号処理、情報科学、機械学習等
-
研究が始まったのは1990年代
とりあえず最初に気づいたのは、これ音源じゃなくて音楽に関する研究じゃん……ということ。そうだよね! Soundじゃなくて、Musicだもんね! ごめんね!
でも、MIRの音楽系音源バージョンが私の理想だと思うので、将来的に参考にしようと思いつつ一回離れる。
とりあえずやってみる
うーん、とりあえずやってみないと分からないからやってみよう。
全ての音源を判別するとなるとデータ量が多くなりすぎて、学習も大変だし、集めて前処理するのも大変だろうから、とりあえず私が今持っているドラム音源を学習させて、ドラムの種類を判別させるものを作ることにする。テストデータは、私のSpliceクレジットが600弱余ってるのでそれを使って適当に持ってくる(余り過ぎ)。
本当は深層学習とかさせたいんだけど、何か難しそうなのと、ChatGPTに最初はSVMとかがいいよと言われたのでSVMを使う。
とりあえず、先行研究がないかを調べる……あった。そりゃあるか。
今見てるのは高津高校さんの研究ドキュメント……というか高校生でこれできるのスゴイな。羨ましい。
なるほど、SVMは2クラス分類が得意だからそれぞれの楽器で機械学習モデルを作って、その楽器か否かを判定させてるのか。その発想は無かった。
今回のドラム音分類にもその方法は使えそうなので、拝借。
というか、色々調べたらScikit-learnのSVMにその機能はあるらしい。
データの特徴量はメル周波数ケプストラム係数(MFCC)というのを使っているらしい。まじでなんだこれ……
うーーーーん。よくわかんないけど、音を良い感じに特性だけ取り出して圧縮してくれる技術? って感じ。
具体手法としては、フーリエ変換、離散コサイン変換とかを使ってるらしい。うん、聞いたことだけある。
MFCCはメル尺度という人間は低い音に敏感で、高い音に鈍感であるという特性に基づいた尺度で音を解釈するらしい。また、深層学習では必要な情報が抜け落ちてしまうことから、メルスペクトラムを使うらしい。
なんか音をデジタルで表現する上で重要な技術な感じがするので、これからもお世話になりそう。
このMFCCはPythonのライブラリlibrosaというので出来るらしいので、とりあえず理解はこんなもんで。
参考にしている高津高校さんの研究ドキュメントではデータの無音部分を削除とかしているんだけど、そこら辺は問題ないと思われるのでそのままlibrosaに食わせることにした。
通常は音源をモノラルにして、サンプリングレートを22050 Hzにしてー……とかするらしいんだけど、librosaはload関数でそういうのやってくれるみたい。えらい子。
じゃあもうこれ、
-
ドラム音源データを集める
-
LibROSAにデータを食わせて前処理と特徴抽出をする
-
ラベルを付ける
-
SVMに学習させる
-
学習させたのを実際に使う
で出来ちゃうのかもしかして!?
じゃあ取り掛かろう。
ドラム音源データを集める
私はCubaseとかSplice経由で音源をいくつか持っているので、とりあえずそれを集める。
数百データになればいいかなぁという感じ。
今気づいたんだけど、Cubaseとかの付属音源ってvstファイルになってんのね。これちょっと面倒だけど、一つずつエクスポートしていくしかないっぽい?
うーんちょっとさすがに面倒なので、フリー音源からドラムの音を持ってくることにする。
とりあえず出来るだけ多様性と数を重視して素材を集める。
集めたデータは
-
Kick 66個
-
Snare 81個
-
openHihat 42個
-
closeHihat 57個
-
Crash 22個
-
Tom 65個
の合計333個で、どれもwav形式のone-shotで44100Hz。データはフォルダで分けている。
こうやって色んな音源聞くとtomなのかkickなのかまじでどっちかわかんないみたいな音源が沢山あることに気づく。正直、CHihatとOHihatのところとかちょっと不安。
LibROSAにデータを食わせて前処理と特徴抽出をする
まず、どの環境でやろうか。
今回の音源データは合計80MB=wavで5分くらい。80MBであればGoogle Colaboratoryで問題ないと思うんだけど、将来のことを考えるとグラボを載せたPCで実行するのにも慣れておきたい気持ちがある。
なんかグラボ使って機械学習動かすのって面倒だった覚えがあるんだよね。
うーん。面倒だからとりあえずColaboratoryでやっていこう。
今まで数字の認識とか、花の分類とかそういう初心者向け機械学習みたいなのはちょっとやったことあったけど、自分でデータを集めてっていうのは始めてだから分からないことが多い。
まず、一応ColabをGithubと連携させてコミットする。
次に、データを永続化するために、GoogleDriveに音源データを保存する。
これで、下準備おkって感じ?
そしたら、以下のコードを実行
import os
import glob
import numpy as np
import librosa
#wavファイルをmfccにして、numpy配列で保存
# 対象とするフォルダのパスを指定
folder_path = "/content/drive/My Drive/..."
# フォルダ内の全てのwavファイルに対して処理を行います
for filename in glob.glob(os.path.join(folder_path, '*.wav')):
# 音声ファイルの読み込み
y, sr = librosa.load(filename, sr=None) #sr=Noneにすることでオリジナルサンプリングレートで読み込む
# MFCCの計算
mfccs = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=13) #13次元を指定しているが、とりあえずなので後から修正も
# MFCCsを'.npy'ファイルとして保存
# ファイル名から拡張子を除いたものに'_mfccs.npy'を付けた名前で保存します
np.save(os.path.splitext(filename)[0] + '_mfccs.npy', mfccs)これは、指定したフォルダ内にあるwavデータを全てMFCC化し、永続保存するためにNumpy配列で保存するコード。
ChatGPT-4に出力してもらったのを一部改変した。
とりあえずこれでメル周波数ケプストラム係数にできてるっぽい?
SVMで処理させる前にデータ時間を調整
なんか色々やってSVMで学習させようとしたら、「setting an array element with a sequence. The requested array has an inhomogeneous shape after 1 dimensions. The detected shape was (265,) + inhomogeneous part.」というエラーが。
これは、入力データが他のデータと形状が違うかららしい。
要するに、データを全て同じ時間にしなきゃいけないということ。
全体の時間の分布を見て決めるために、ヒストグラムで全データの時間を見るコードをChatGPTに出力してもらう。
import matplotlib.pyplot as plt
import numpy as np
import librosa
# 指定したフォルダにあるフォルダのwavファイルを見る
file_paths = glob.glob(os.path.join("/content/drive/MyDrive/…", '*', '*.wav'))
# 各音声ファイルの長さ(秒)を格納するリスト
lengths = []
# 各ファイルの長さを計算します
for file_path in file_paths:
y, sr = librosa.load(file_path, sr=None)
length = librosa.get_duration(y=y, sr=sr)
lengths.append(length)
# numpy arrayに変換します
lengths = np.array(lengths)
# ヒストグラムを表示します
plt.hist(lengths, bins=50)
plt.xlabel('Length (seconds)')
plt.ylabel('Count')
plt.show()結果
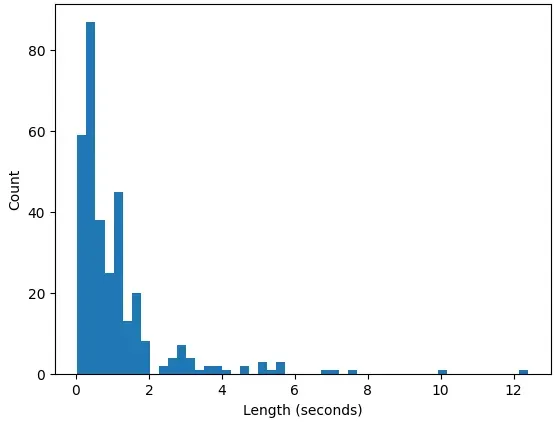
大体6秒くらいで調整すればいいかな?
調整する関数は以下の通り
max_length = int(44100 * 6) # 今回は6秒でパディングするので、44100Hz*6
def load_and_pad(file_path):
y, sr = librosa.load(file_path, sr=None)
if len(y) > max_length:
y = y[:max_length] # If もし長ければ切る
else:
y = np.pad(y, (0, max_length - len(y))) # もし短ければ増やす
return y全てのコード
ここまで出来たらデータを取り出すときにラベルを付けて、SVMに入れればおk。
以下のコードはwavファイルをMFCCにして、データの訓練とテストを100回やって平均正答率、標準偏差を出し、混同行列を表示するところまでやってるよ。
import os
import glob
import numpy as np
from sklearn import svm
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
import librosa
from sklearn.metrics import confusion_matrix
from sklearn.metrics import ConfusionMatrixDisplay
import matplotlib.pyplot as plt
import random
max_length = int(44100 * 0.2) # 今回は6秒でパディングするので、44100Hz*6
def load_and_pad(file_path):
y, sr = librosa.load(file_path, sr=None)
if len(y) > max_length:
y = y[:max_length] # If もし長ければ切る
else:
y = np.pad(y, (0, max_length - len(y))) # もし短ければ増やす
return y
# フォルダ名とそのラベルを格納するリスト
data = []
labels = []
# フォルダのパスを指定します (e.g., "/content/drive/My Drive/A/data/")
base_folder_path = "/content/drive/MyDrive/…"
# フォルダ内のサブフォルダ(ジャンル)を一つひとつ見ていきます
for genre_folder in os.listdir(base_folder_path):
# サブフォルダ内の全ての.wavファイルに対して処理を行います
for filename in glob.glob(os.path.join(base_folder_path, genre_folder, '*.wav')):
# 音声ファイルの読み込みとパディング
y = load_and_pad(filename)
# MFCCの計算
mfccs = librosa.feature.mfcc(y=y, sr=44100, n_mfcc=13)
data.append(mfccs.flatten()) # SVMの入力に合わせデータをフラット化します
labels.append(genre_folder) # フォルダ名(ジャンル名)をラベルとして追加
# ラベル(ジャンル名)を数値に変換します。例えば、'CHihat' -> 0, 'OHihat' -> 1のような変換を行います
encoder = LabelEncoder()
labels = encoder.fit_transform(labels)
accuracy100 = 0
accuracy_list = []
cm100 = np.zeros((len(encoder.classes_), len(encoder.classes_)))
for _ in range(100):
# データとラベルを訓練データとテストデータに分割します
X_train, X_test, y_train, y_test = train_test_split(data, labels, test_size=0.2, random_state=random.randint(1,10000))
# SVMのモデルを作成し、訓練データで学習します
model = svm.SVC()
model.fit(X_train, y_train)
# テストデータでモデルの精度を確認します
accuracy = model.score(X_test, y_test)
accuracy_list.append(accuracy)
print("Accuracy: ", accuracy)
accuracy100+=accuracy
# テストデータの予測値を得ます
y_pred = model.predict(X_test)
# 混同行列を計算し、加算します
cm = confusion_matrix(y_test, y_pred)
cm100 += cm
accuracy_std = np.std(accuracy_list)
print("標準偏差: ", accuracy_std)
print("平均正答率",accuracy100/100)
# 混同行列の平均を計算します
cm_avg = cm100 / 100
# 混同行列をプロットします
disp = ConfusionMatrixDisplay(confusion_matrix=cm_avg,display_labels=model.classes_)
disp.plot()
plt.show()
cnt=0
# 各ラベルに対応した名前を表示します
for i in encoder.classes_:
print(f"{cnt}:{i}")
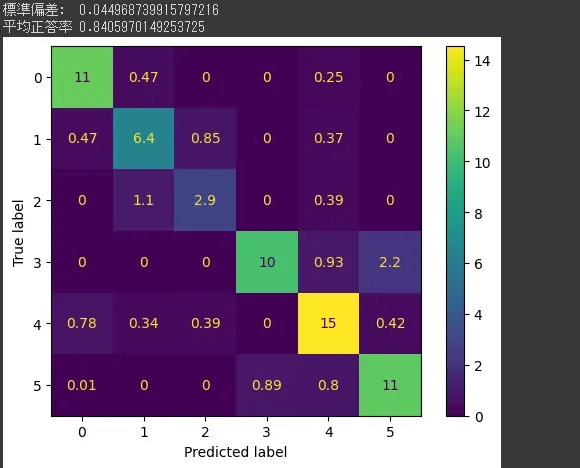
cnt+=1これで大体正答率が59%。流石に低すぎないか?
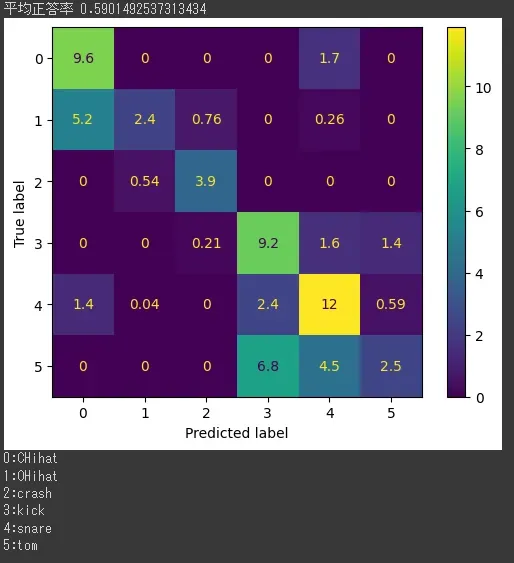
結果を見てみるとタムの正答率が著しく低い。まあ、タムがkick、snareと似てるのはわかる。
色々試したら、データ時間を調整する秒数を短くすると結果が良くなった。
最初は6秒だったけど、0.2秒にするとおよそ正答率80%に上昇した。
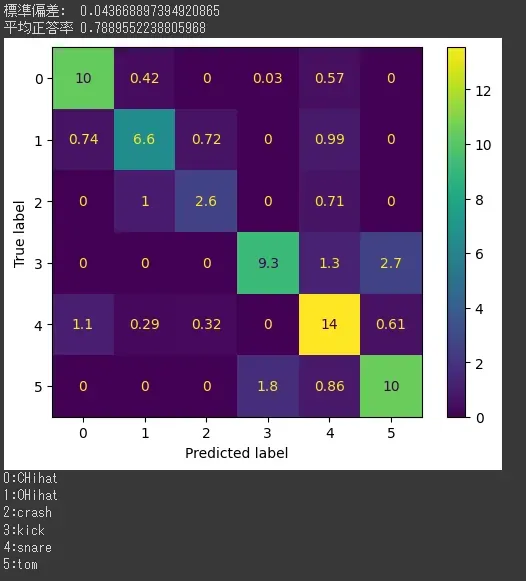
混同行列を見ると、
-
kickとtomがお互いにまあまあ間違われている
-
kickがスネアにある程度間違われている
-
openHihatとスネアがお互いにある程度間違われている
-
openHihatとcrashがお互いにある程度間違われている
という感じ?
実際のところ、間違って分類しているところ(kickとtom、openHihatとスネア)はリアルな音とかじゃなく電子音になると人間でも間違うというか、ただその音にその名前がついているだけで本質的なところは一緒じゃない? みたいのもあるので限界はあるだろうし、もし複数の候補があるなら「どちらの可能性もあります」と表示してくれた方が音楽の幅も広がるから、それを目指したい。
<追記>mfcc化する際のサンプリングレートを176400、次元を40にしたら平均正答率が84%になった。次元数を上げると精度が上がるのはわかるんだけど、サンプリングレートを上げると精度が上がるのがマジでわからない。解像度を引き延ばしたところで情報は変わらない気がするんだけど、何か認識が違う?
結果
とにかく、やってみて気づいた、感じたことは
-
データ時間を0.2秒と短くすることで今回の条件下でのドラム音源分類の精度が著しく上がった。
-
ということは、無音区間の除去などの処理を行えば精度がもっと上がるのでは?
-
正答率84%が高いか低いかはわからないが、データの質、量がともに少なく悪かったとは思われるので、次はそこを改善したい。
-
今回はSVMを利用したが他のアプローチも試してみたい
って感じ?
とりあえずお遊び程度ではあるけど、何となく機械学習に触れられてよかった。
今回はChatGPT-4を使ってコードを出力→理解→私の方で修正という感じで進めていったから1日で終わったんだけど、どうなんだろうか。
この、ChatGPTに頼る方法が正しいのか、本当に自分の為になるのかは常に考えてるんだけど、別に悪くない気はする。しかし、ChatGPTだけから情報を得るのは真偽以前に情報が偏る気もするので慎重に扱っていきたい。
今のChatGPTの使い方にもやもやする理由が何となくわかった。
今までのプログラミングの学び方は言わば高校数学のある問題を数学の教科書を見て学び解くイメージ。
ChatGPTを使ってプログラミングを学ぶ方法は言わば高校数学のある問題を解くとき、その解法を教えてもらって学び解くイメージ。
確かに、回答を見て学ぶ方法もあるんだけど、実際に解いて理解するのと回答を見て理解するのでは身に付くレベルが違う。
かといって今まで通りネットの海にある大量の情報から自分の欲しい情報をピンポイントで探し回るのは違う気がする。
一回ChatGPTと一緒にプログラミングを作ってから、ちょっとだけ内容を変えたものを自分で作れば身に付くか?
というか、そもそも本当に身に付く必要があるのか? 調べて使えれば問題ないのではとも思う。
どちらにしろ、ChatGPTとは慎重にお付き合いしたい。