2023年6月25日
とりあえず、規模は小さくということで、ジャンルを絞った音源分類ツールを作る。
前回のドラム音源分類の続きなので、それを見ないと何やってるのかわからないかも。
前回試作的なものを作ったけど、とりあえずそれにフロントエンドっぽい所を追加して、実際に使えるソフトを作りたいと思う。1週間で。
作る理由は
-
私自身、音楽にプログラミングで貢献したいため
-
ブログのタイトルにもある通り、Pythonで音楽系人工知能を作るため
実践する前に考えてること
-
今回は音源をSpliceから取ってくる予定。恐らく、日本の法律的に勝手にスクレイピングしても問題ない気もするんだけど(出来るかはわからん)、普通に世界の法がよくわからんってのと、クレジットめっちゃ余ってるから買ったものを使用する。大体600クレジット強あるので、6種類を100音ぐらい?
-
今回は手軽さからSVMを使うけど、SVMだと音源の”時間の違い”を食わせるのが難しい。だから、もっと違う方法の方がいいとは思う。調べたら色々出てくるんだけど、論文の読み方とかがちょっとまだわかんなくて学習コストが高いので、今回はSVMで勘弁。
-
それと、今回のSVMを各ジャンルごとに学習させる方法の悪いところ? にタグ同士の関連性を考慮できないってのもある。Stabっていうタグが付いてたらEDMっていうタグが付いてる可能性が高いと思うんだけど、それぞれタグ毎にSVMのモデルを作るからそういう考察ができない。果たしてこれがいいのか悪いのかはちょっとまだわからない。
-
将来的には、Spliceにある音を大量に、Spliceにあるタグを正解ラベルとして食わせたら普通に実用的な物になると確信してる。けど、正直結構真似しやすいツールにはなると思うので、こうやってブログに残してる。
-
あと、音楽みたいに多様性がすこぶるある物の分類の場合、もっとサンプル数があったほうが絶対にいいと思う。
今回作るものと、データ集め
最初は前回と同じドラムの分類にしようと思ったんだけど、前回と同じだとちょっと面白くないのでシンセ音の分類にする。
Spliceにある代表的なシンセタグの子タグは以下の感じ。
ここから6種類となると……
-
Bass
言わずもがなのベース。しかし、ベースといってもサブベースとかkickっぽいベースとか、ジャンルによっても全然違うので、SVMで捌けるかが今回の見せ所。 -
Leads
なんだろうね、リードって。なんか、音が高くて長めなメロディを奏でてる感じ?こちらも癖強リード…というかリードの種類が多いので、SVMで捌けない気がする。 -
Pads
パッドは空間を作る系の音。なんか優しい。これは簡単に分類できそう。 -
Stabs
正直あんまよくわかってないんだけど、アクセント系の音。EDMっぽい感じ。FXと何が違うねんと言われたらわからんし、ベースっぽいものもあればブラスっぽいのもある。こういうのを機械学習にいい感じにラベル付けして欲しい。 -
Plucks
プラックは一応弦楽器っぽい音となんだけど、シンセになるとそうでもない。対旋律とかでかっこいいプラックが奏でられてると超テンション上がる。 -
FX
その他=FXみたいな感じが正直あるから、機械学習で捌くには大量のデータが必要な気がするんだけど、機械学習にやってほしいのは”正解に分類すること”じゃなくて”この音はこのジャンルの音にも聞こえます”ってことなので、かき乱し要員で入れる。
こんな感じ。
とりあえず、全部One-Shotsで人気順に100個ずつ取っていこうかな。普通に私の音楽制作にも使えるし。あと、1分とかの長すぎる音はダウンロードしてない。
あと、時々複数の要素を持ってる音源があるんだけど、マジでどうしよう。

上のやつとか、fxとplucksの2要素を持ってる。
ラベル付けする時フォルダに分けてラベル付けしてたからちょいと困る。
普通に2つのフォルダに入れればいいか? とりあえず今回はそれでやろう。
ダウンロードしてみると、1ページで50個の音源が表示されるっぽいので、1種類につき2ページ分かな。
まとめると、
-
学習の為の素材はSpliceから買ってダウンロードしてくる
-
1タグ当たり100個程度の音源
-
One-Shots形式、wav形式
-
1分以上のものは、容量が重いのと、少し例外的なので除外
-
余りにもそのジャンルの音でないものはそのタグが付いてても除外(padはpadでも紙を叩く音みたいのがあったのでそれは除外)
-
複数の要素を持ってたら、すべてのラベルを付ける。
実際にSVMに食わせてみる
上の要件の感じで、ダウンロードし……ました!
マジで疲れた。1時間以上はかかった。下手したら2時間くらいかかったかもしれない。
やっぱり学習データは既にあるものを使うか、スクレイピングして自動的に収集したほうがいいね。
最終的に
-
Bass 136個
-
Leads 102個
-
Pads 100個
-
Stabs 101個
-
Plucks 100個
-
FX 137個
になった。
FXとBassが多いのは他のタグとよく被ったからだね。特に、Stab×Bass、Pad×FXで被ることが多かった印象。Most popular順に並べて、ダウンロードした順番も影響した結果こんな比率になってるよ。
結構今更なんだけど、これサンプルによってサンプリングレート違うこととかあるかな?
……
調べてみた感じ、サンプルによってサンプリングレートは違う。
mfccs = librosa.feature.mfcc(y=y, sr=44100, n_mfcc=20)で勝手に44100に統一はしてくれるっぽいんだけど、max_length = int(44100 * 3)でパッティングの時間指定をしてて、これだと44100の時の時間指定になるから、ちょっと不具合というか、想定してないことにはなるかもしれない。
もし、ダメそうなら一回wavファイルを44100に変換→パッティング→mfccs化という動作が必要そう。
とりあえず、前回作ったドラムの分類のコードにシンセ音源を入れてみよう。
設定はとりあえずサンプリングレート44100で、3秒、次元数20でやってみる。
結果はこんな感じ。
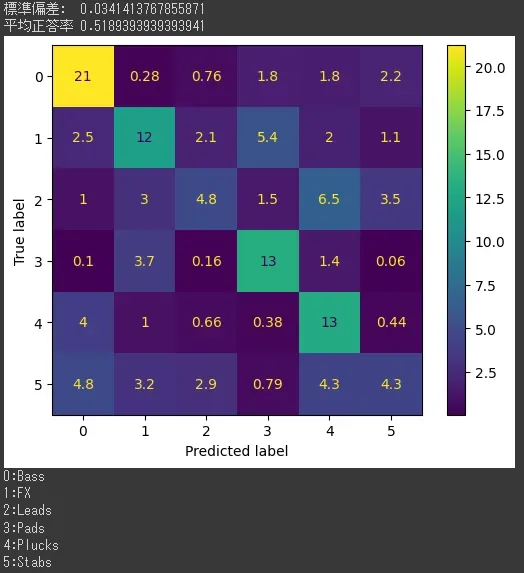
100回あたりの平均正答率は52%弱。うーん。
正直、正答率というよりどう特徴を捉え、どう間違えたかが大事だと思うので、この数字はそこまで悪くないかなと思う。
混同行列を見ると、
-
Bassの正答率は大体75%で、主に、Pads,Plucks,Stabsと間違えてる。PluckとStabに間違えるのはむしろ成功だと思うんだけど、Padと間違えるのはあんま良くないかなぁという感じ。
-
FXの正答率は大体48%で、主にPadと間違えてる。これは普通に良い間違いなので、おk
-
Leadの正答率は大体23.5%で、主にPlucks,Stabsと間違えてる。ここは正直Leadの特徴が捉えきれてない感じが正直する。難しいな。
-
Padの正答率は大体70%で、主にFXと間違えてる。これも良い間違いなのでおk。
-
Plucksの正答率は大体67%で、主にBassと間違えてる。これも良い間違い。
-
Stabsの正答率は大体21%でかなり低い。でも、Stabの場合はどの音をどう間違えたかが結構大事なので、%だけじゃ評価できないかな。って感じ。
今のところは概ねいい感じだけど、Leadだけちょっと不安かな。
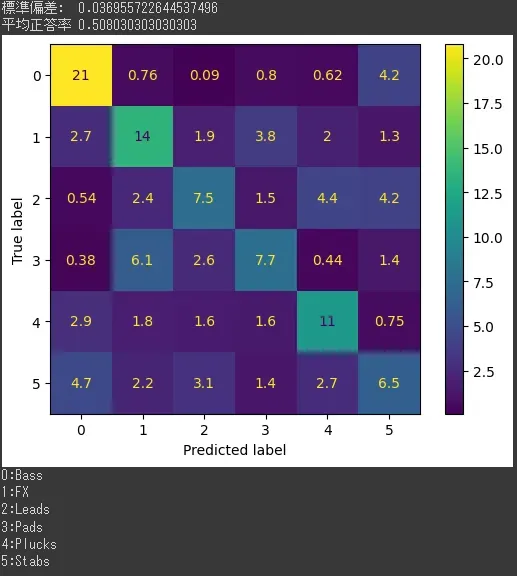
一回、前回正答率が伸びたパッティング0.2、サンプリングレート176400、次元数40とパッティング2、サンプリングレート44100、次元数40をやってみる
パッティング0.2、サンプリングレート176400、次元数40
パッティング2、サンプリングレート44100、次元数40
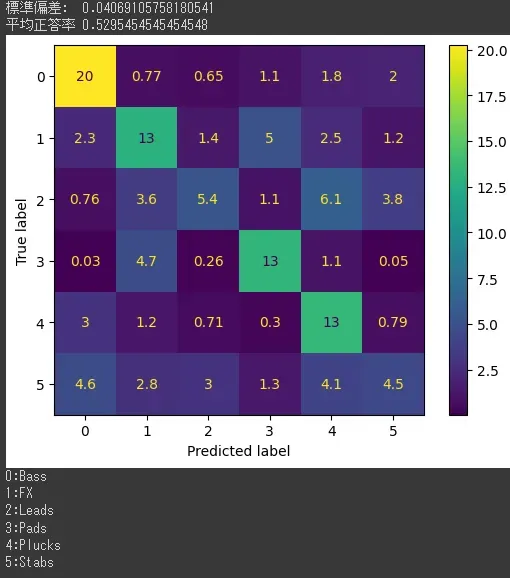
うーん。とりあえずサンプリングレートはやっぱり関係なさそう。
そんで、今回の場合、Padは基本的に時間が長い傾向があるから、パッティングはある程度長いほうがPadの正答率は上がる感じがする。
とりあえず、実際に音を食わせてどんなラベルを付けるかというのをやりたいので、閾値を決めて一定以上になったらラベルをつけるというコードを作りたい……が、もう今日は夜遅いので今日はここまでで明日やろう。
おやすみなさい。