2023年9月7日~2023年9月29日
やっていこう。
もっと使いやすく・実用的にするために以下の機能を追加したい
- いいね、おすすめ、新着順などのソート
- おすすめ順を作るならアルゴリズムが必要?
- 音源投稿方法の修正
- できればCKEditorにD&Dで音源投稿できるようにしたい
- タグを押すことでタグ検索
- マイページにもう少し”特別感”を
- 目次機能
- 記事自動保存機能
- midiとか埋め込みたいなぁ
- 記事内でのSoundCloud・Spotify・YouTube・Twitterらへんのリンクを綺麗にしたい
音源投稿方法の修正
音源投稿方法の修正からしていこう。
現在、音源を記事内に入れるには、以下のようにわざわざ音源をアップロードして、そのパスを記事内に入れるという超絶面倒くさい作業を必要とする。

流石にこんな仕様、ユーザビリティもなにも無いので、imageファイルをアップロードする時と同じように、記事内にドラック&ドロップするだけでアップロードできるようにしたい。
やり方は……まじでどこにもないので、とりあえずCKEditor5の公式チュートリアルを読み漁る。
CKEditorを学ぶ
急がば回れとはよく言ったもので、とりあえず基礎を学ぶのがなんだかんだ速かったりするよね。
CKEditor5の公式チュートリアルで学んでいく。
環境を整えて基礎を学ぶ
とりあえず、ホスト環境にnpmを入れてチュートリアル用の環境を整える。
チュートリアル用のフォルダは普通に.zipでダウンロードした。
そんで
“npm install”
“npm run dev”
npm installが3分以上かかった。
いいね。
src/main.jsに以下のコードを記述してみる
// エディタのインポート
import { ClassicEditor } from '@ckeditor/ckeditor5-editor-classic';
// IDが”app”のHTML要素を取得し、elementに代入
const element = document.querySelector( '#app' );
// createメソッドを使ってエディタをインスタンス化
const editor = await ClassicEditor.create( element );コメントは日本語に変えておいた。
HTMLも同時に見てみよう。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>CKEditor 5 Tutorial</title>
</head>
<body>
<div id="app">
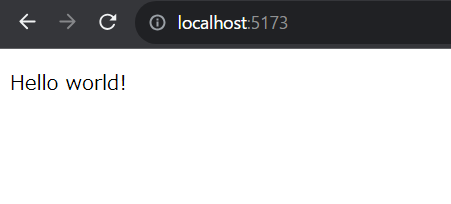
<p>Hello world!</p>
</div>
<script type="module" src="/src/main.js"></script>
</body>
</html>なるほど。
divの1つがid=”app”に指定されているので、ここがCKEditorになるという認識でいいのかな。
実際に更新して見てみると
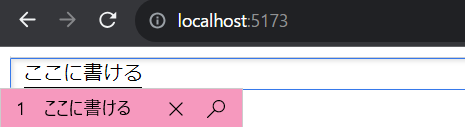
分かり難いけど、Hello World!が入力スペースになっていた。
でも、書いても直ぐ消えちゃう。
これは、プラグインが何も入っていないかららしい。
機能は全てプラグインが賄うんだね。
src/main.jsのコードを以下のように更新する。
// Import
import { ClassicEditor } from '@ckeditor/ckeditor5-editor-classic';
import { Essentials } from '@ckeditor/ckeditor5-essentials';
import { Paragraph } from '@ckeditor/ckeditor5-paragraph';
// IDが”app”のHTML要素を取得し、elementに代入
const element = document.querySelector( '#app' );
// createメソッドを使ってエディタをインスタンス化
const editor = await ClassicEditor.create( element, {
plugins: [
Essentials,
Paragraph
],
// ツールバーの追加
toolbar: {
items: [
'undo',
'redo'
]
}
} );pluginsにEssentialsとParagraphが入った。
Essentialsはundoとredoを出来るようにするプラグインみたいで(他にもいろいろ機能あった)、toolbarにその機能のボタンを追加してるという感じかな。
カスタムプラグインの呼び出し
undo,redoとかenterで改行とかそういう基本的な機能はCKEditor側でプラグインとして用意していくれているのでヨシとして、何か自分で機能が欲しくなった時は自分でプラグインを作る必要があるよね。
src/plugin.jsにカスタムプラグインを作って呼び出してみる。
内容は、呼び出すとコンソールに「このプラグインはハイライトプラグインです!」と出てくるプラグイン。
src/plugin.jsに以下を記述
export function Highlight( editor ) {
console.log( 'このプラグインはハイライトプラグインです!' );
}src/main.jsに以下を追加
import { Highlight } from './plugin';
const editor = await ClassicEditor.create( element, {
plugins: [
// 他のプラグインは隠しています
Highlight,
],起動してf12でコンソールをみてみると
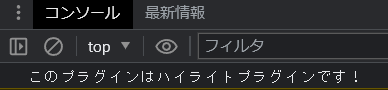
ちゃんと動いてるね。
CKEditor5のモデルとビュー
CKEditorにはモデルとビューという概念がある。
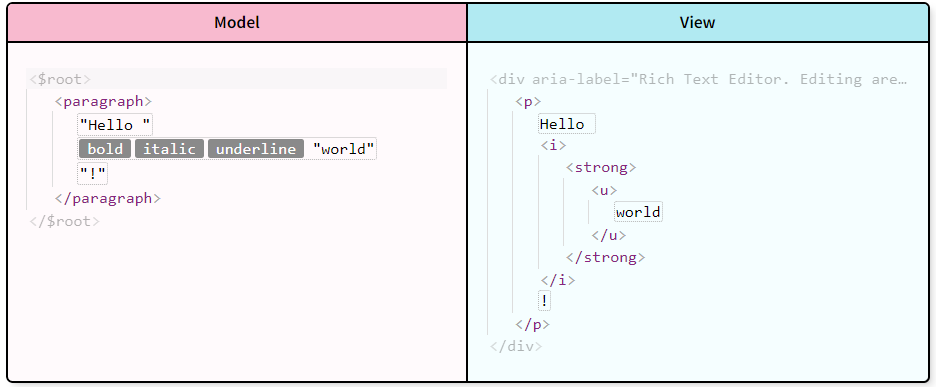
モデルはデータの構造を表現するもので、ビューはモデルを元に生成されるHTMLのこと。
この変換にはconversionというのが使われる。
また、モデルのルール(このモデルを使える、このモデルは入れ子できる)というのはスキーマというので定義する。
例えば、imageタグに太文字にするタグを付けたりするのはおかしいから、そういうのを制限するのかな。
さっきのプラグインにconversionとスキーマを追加してみる。
export function Highlight( editor ) {
console.log( 'このプラグインはハイライトプラグインです!' );
editor.model.schema.extend( '$text', {
allowAttributes: 'highlight'
} );
editor.conversion.attributeToElement( {
model: 'highlight',
view: 'mark'
} );
}
こうすることで、highlightというモデルが使えるようになり、viewとmodelにmarkとhighlightという変換関係ができた。
つまり、モデルで文章にhighlight属性がついてたらviewに変換するときにmarkタグを付けてくれる。
カスタムプラグインのロジックを書く
ロジックはコマンドというので書く。
src/plguin.jsを弄る。
まず、コマンドを継承するために
import { Command } from ‘ckeditor5/src/core’;
を記述。
そんで、コードは
export function Highlight( editor ) {
console.log( 'このプラグインはハイライトプラグインです!' );
editor.model.schema.extend( '$text', {
allowAttributes: 'highlight'
} );
editor.conversion.attributeToElement( {
model: 'highlight',
view: 'mark'
} );
editor.commands.add( 'highlight', new HighlightCommand( editor ) );
}
class HighlightCommand extends Command {
refresh() {
const { document, schema } = this.editor.model;
// 選択範囲がすでにハイライトされているかのチェック
this.value = document.selection.getAttribute( 'highlight' );
// 選択範囲でハイライトが許可されているかのチェック
this.isEnabled = schema.checkAttributeInSelection( document.selection, 'highlight' );
}
execute() {
const model = this.editor.model;
const selection = model.document.selection;
const newValue = !this.value;
model.change( ( writer ) => {
if ( !selection.isCollapsed ) {
const ranges = model.schema.getValidRanges( selection.getRanges(), 'highlight' );
for ( const range of ranges ) {
if ( newValue ) {
writer.setAttribute( 'highlight', newValue, range );
} else {
writer.removeAttribute( 'highlight', range );
}
}
}
if ( newValue ) {
return writer.setSelectionAttribute( 'highlight', true );
}
return writer.removeSelectionAttribute( 'highlight' );
} );
}
}Highlight関数には
editor.commands.add( ‘highlight’, new HighlightCommand( editor ) );
を足しただけ。
コマンドを使う為のコードかな。
HighlightCommandにはrefresh()とexecute()がある。
refreshが”状態”を処理するところで、executeがロジックを書くところ。
executeについて、
model.change( ( writer ) => {
は処理をグループ化するための物。
グループ化することで、undo,redoで1回で処理できたりする。
if ( !selection.isCollapsed ) {
const ranges = model.schema.getValidRanges( selection.getRanges(), 'highlight' );はif文で選択範囲に文字があるかを判定して、あればその長さをrangeで取得している。
そして、以下のところで選択範囲のモデルをhighlightにしたり、取り除いたりしている。
for ( const range of ranges ) {
if ( newValue ) {
writer.setAttribute( 'highlight', newValue, range );
} else {
writer.removeAttribute( 'highlight', range );
}
}
}以下の部分で選択範囲のテキストをhighlightにしたり、取り除いたりしている。
if ( newValue ) {
return writer.setSelectionAttribute( 'highlight', true );
}
return writer.removeSelectionAttribute( 'highlight' );つまり、モデルだけ変更しても更新しないとテキストに反映されないので、テキストも同時に更新しているという感じ。
ユーザーインターフェースの実装
ロジックは作ったけど、それを実行するインターフェースがないので、インターフェースを作ろう。
つまり、ツールバーの編集をする。
ボタンも今までと同じようにplguin.jsに記述する。
import { ButtonView } from ‘ckeditor5/src/ui’;
をインポートして、highlight関数の最後に以下を追記
editor.ui.componentFactory.add( 'highlight', ( locale ) => {
const button = new ButtonView( locale );
const command = editor.commands.get( 'highlight' );
const t = editor.t;
button.set( {
label: t( 'Highlight' ),
withText: true,
tooltip: true,
isToggleable: true
} );
button.on( 'execute', () => {
editor.execute( 'highlight' );
editor.editing.view.focus();
} );
button.bind( 'isOn', 'isEnabled' ).to( command, 'value', 'isEnabled' );
return button;
} );そんで、src/main.jsのツールバーに追加すれば
toolbar: {
items: [
'undo',
'redo',
'highlight'
]
}ハイライトボタンの完成!
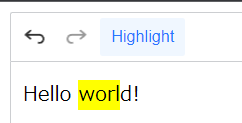
音声ファイルのドラック&ドロップ機能の追加
うーん。何となく大まかなCKEditor5の仕組みは分かったかもしれない。
とりあえず、今欲しい機能の要件をまとめてみる
- ユーザーがAudioファイルをCKEditor内にドラック&ドロップ
- アップロードのAPIエンドポイント(URL)にオーディオファイルを送る
- アップロードが終わるとそのパスを取得
- パスから,<audio controls=”” src=”http://xxx/xxx”>audio</audio>のようなaudioタグを生成し貼り付け
という感じかな。
CKEditorの仕組みをもう少しちゃんと理解してあげればそこまで難しくは無さそう。しらんけど。
また、色々調べて見るとアップロードアダプターという概念があった事を思い出した。
ここら辺を使ってちょっと頑張ってみる。
CKEditorをカスタムビルドにする
そもそも自分でプラグインを追加したり削除したりするには、カスタムビルドということをしなきゃいけないみたい。
参考サイトも何も情報が本当にないんだけど、一応少し参考になったのはこちらと公式サイト。
CKEditorにはオンラインビルダーというのがあるけど、あれで作れるのは既にBuildされたもの。何か自分でプラグインを作ったり入れたりしたいなら、ビルド前の環境を自分で整えて、npm run buildで自分でビルドする。
githubからckeditorをダウンロード
まず、githubからCKEditorをダウンロードする。
恐らく、ZIPでダウンロードしてもいいしCloneしてもいいし、Forkしてもいい。
とにかく、このソースコードが必要。
ダウンロードしたら、Zipの人は解凍してもろて。
メインフォルダにpackagesというフォルダがあるので、packagesに移動。
ここで、エディタタイプを選ぶ。色々あるので調べてほしいけど、よほどな理由が無ければClassicで問題ないはず。
今回の私はエディタタイプをClassicにするので、このckeditor5-build-classicをそのままデスクトップかどこか弄りやすいところに移動する。
チュートリアルだと移動させずにやってたんだけど、私の環境だと無理だった。
この、ckeditor5-build-xxxxxがビルドしていく環境。
既に、フォルダにbuildフォルダがあると思うんだけど、それをLaravelに持っていって適用すると、初期の最低限のプラグインが入ったCKEdtior-Classicが使える。
npm install
まず、cmdを開いてckeditor5-build-classicの場所まで移動。
移動したら”npm install”を行う。
npmが入ってない人は最新バージョンでいいので入れてくる。
ここでエラーが出るひとも結構いるのではと思うんだけど、エラー文を見て自分で解決するか、GPTに相談。
もし、
npm ERR! code ERESOLVE
npm ERR! ERESOLVE unable to resolve dependency tree
npm ERR!
npm ERR! While resolving: ckeditor5@39.0.2
npm ERR! Found: react@18.2.0
npm ERR! node_modules/react
npm ERR! dev react@"^18.2.0" from the root projectというエラーだったら、ckeditor5-build-xxxxxより上のフォルダにnpmとか関係ありそうなフォルダを含めないように、つまりデスクトップ直下とかにckeditor5-build-xxxxxを置いた上で、npm install react@17.0.2 react-dom@17.0.2をするといけたよ。
公式プラグインの取捨選択
次に、公式プラグインの取捨選択をする。
これは、オンラインビルダーで実際にビルドしちゃうのが一番早いと思う。
これはビルド後のデータになるので、使うわけじゃないんだけど理想のビルドとして使う。

編集し終わったらダウンロードする。
ダウンロードしたら、ckeditor5-39.0.2-xxxxxxxxx/src/ckeditor.tsファイルをIDEか何かで開く。
開くとこんな感じ。
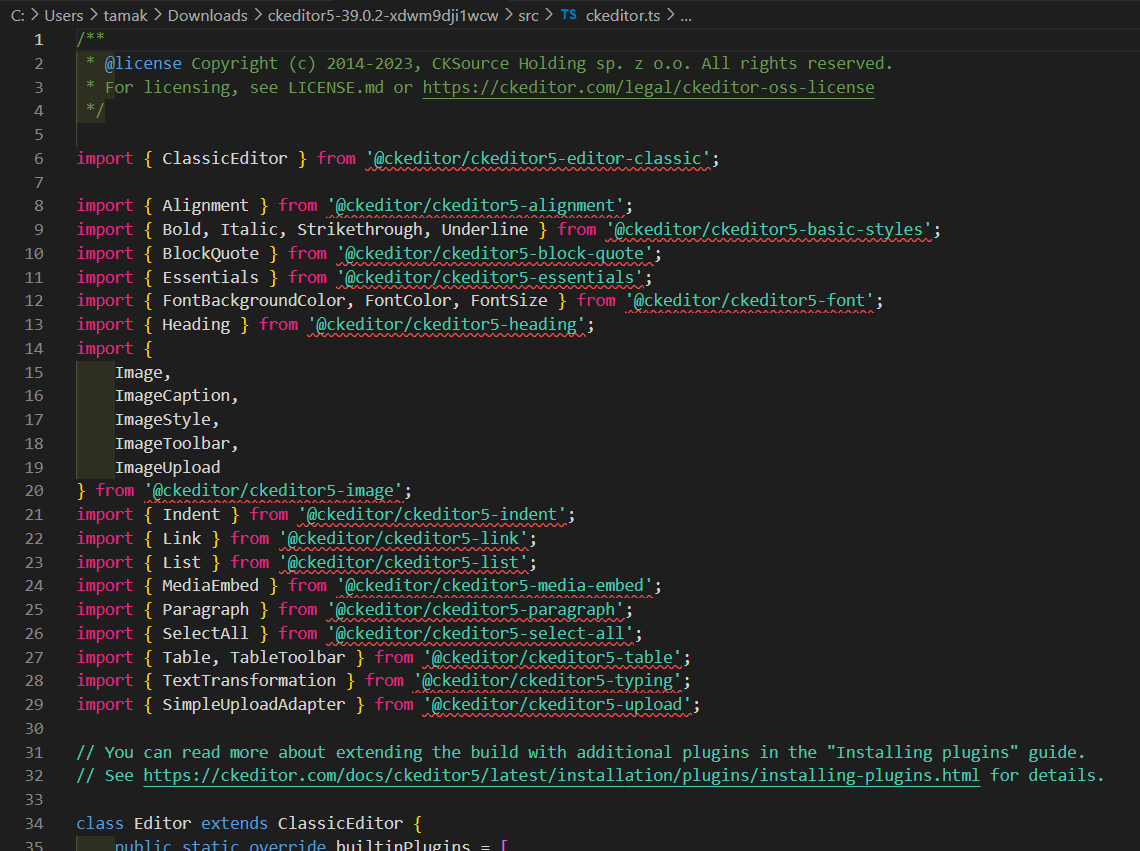
これの、import文一つ一つがプラグインなので、ビルド用のckeidtor.tsフォルダと比較する。
比較、というのはそのままの意味で、つまりこの理想のビルドと現実のビルドには何のプラグインが足りなくて、逆に何が要らないのかを見るという意味。
例えば私の場合、CKBoxは要らないので理想のビルドには入れなかったんだけど、現実のビルドにはは言ってたので、これはアンインストール候補に入れる。
こういうのを一つ一つやっていて書き出す。
私の場合は以下の通り。
アンインストールするもの
- UploadAdapter
- CKBox
- CKFinder
- EasyImage
- PictureEditing
- PasteFromOffice
- CloudServices
- Autoformat
インストールするもの
- Alignment
- FontBackgroundColor, FontColor, FontSize
- Strikethrough,Underlin/ckeditor5-basic-styles
- SelectAll
- SimpleUploadAdapter
- DataFilter,GeneralHtmlSupport from ‘@ckeditor/ckeditor5-html-support’;
- ImageInsert
- language
メモし終わったら、アンインストールからやっていく。
アンインストールは簡単で、理想のビルドからimport文とclass Editor extends ClassicEditor {の終わりまで全部コピーして置き換えればおk。
こうすればツールバーも理想のままになる。
少し面倒なのがインストールで、
“npm install @ckeditor/ckeditor5-プラグイン名”
で一々インストールしなきゃいけない。
プラグイン名はimport文のfrom ‘@ckeditor/ckeditor5-xxxx’;のckeditor5-xxxxが一致するので、ここから取ってくる。
頑張って全部インストールする。
ビルドしてみる。
とりあえず、全部インストールし終わったらしっかり動くか一回確認する。
“npm run build”を実行。
実行し終わったらLaravelのbuildファイルをビルドしたものと交換。
ビルドしたフォルダは普通にckeditor5フォルダのルートにある。
理想通り動けばおk。
カスタムプラグインを作る
といっても、ここからはもう公式のドキュメントを見ながら頑張って作るしかない。
私の場合はだけど、ルートフォルダにmypluginフォルダを作って、そんなかに.jsファイルを作りそこに書いた。
適用するときはckeditor.tsファイルにちゃんとimportしないといけないので注意。
できたもの
最終的に、ドラック&ドロップがどうも上手く動かなくてツールバーからボタンを押して入れる方式に変わった。

将来的にはドラック&ドロップでやりたいんだけど、難しい。
しっかりしたものが出来たら配布とかしたい。
タグを押したらタグ検索するように
今、タグの機能としては”そこにあるだけ”状態。
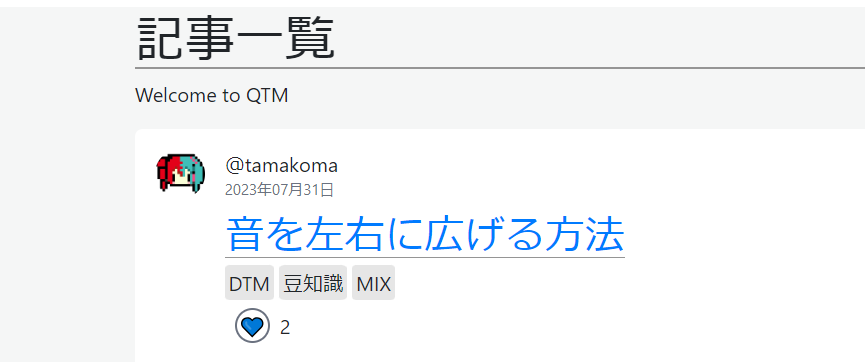
一応検索をかけるときに引っかかるようにはなってるんだけど、押して検索ぐらいは出来るようにしたいよね。
そんなに難しくはないと思うのでやっていく。
とりあえず、tagのコンポーネントを作成する。
“php artisan make:component tag-article”
すっごい単純だけど、以下のようなコードを入れて完了。
@props(["name"])
<a href="{{ route('article.index', ['keyword' => $name]) }}", style="text-decoration: none; color: inherit;">
<span class="hover:bg-gray-100">{{ $name }}</span>
</a>記事を書く・読むうえでもっと使いやすくする
下書き機能・自動保存機能の追加
記事を書く上で下書き・自動保存機能は絶対必要(最終的に自動保存機能は使わなかった)。
この機能はCKEditorの公式プラグインがあるみたいなので、公式ドキュメントを参考に追加する。
autosaveをnpmでインストールする。
“npm i @ckeditor/ckeditor5-autosave”
でインストール。iはinstallの省略形。
早速使おうと思ったんだけど、どういうシステムにするかを考えてなかった。
下書き・自動保存のシステムをどうするか
これ、結構甘く見てたんだけど、大事なところだし、難しいところかもしれない。
この下書き機能というのは、名ばかりで、本質的には記事の本体とも言える。
下書きという名の本体を”投稿”=”コピーしてデプロイ”した時にそれが外部から見れるという仕組みにするのが、恐らく素直な実装だしわかりやすいかなぁ。
Qiitaとかnoteを見ると”編集履歴”というのがある。因みに、zennには無い。
実装難易度は編集履歴のみで言えばそこまで難しくないと思うんだけど、容量の問題とか色々面倒そうだなぁ。
仕組みを考えてみる
- 新規投稿ボタンを押す
- Articleテーブルで一意となるArticle_IDの生成・同時にそのArticleIDを持つ下書きを下書きテーブルに作成
- 編集途中で「下書きを保存」ボタンを押すと既存の下書きを上書き。
- 編集途中で「閉じる」ボタンを押すと、新しく下書きテーブルに現在の下書きを保存。こうすることで、バージョン毎に保存、バージョンは日付で管理。
- 下書きを再編集する際は、好きなバージョンのものから選び、編集ページへ。
- “投稿”ボタンを押すと、Articleテーブルに下書きの内容を上書き保存する。
こんな感じで、いいんじゃないだろうか?
ここでちょっと気になるのが、検索速度の話。
全然規模が小さければ問題ないんだけど、例えばQiitaとかは総記事70万件(2022年時点)とかになっていて規模が大きい。これって、下書きをバージョン毎に保存したりしたら300万件くらいの量になると思うんだよね。
例えば、この300万件の下書きから特定のArticle_IDの下書きだけ全て取得したいとなったとき、全探索だと計算量がちょっと多いなぁと思って。
MySQLがどういう仕組みでどれくらいの速度で動いてくれるかはあんまり知らないんだけど、Pythonだったらちょっと厳しいくらいだよね300万件=10^6*3って。
色々調べたらMySQLのインデックスという話があったので、纏めてみる。
DBのインデックスとは
私も全然詳しくないので、間違いもあると思うけど、恐れず自分の解釈を説明していく。
あと、インデックスの仕組みは色々あるっぽいので、これがすべてではない。
例えば、以下のような記事の下書きを保存する「下書きテーブル」があるとする。
Article_IDはArticleテーブルのものと紐づいている感じ。
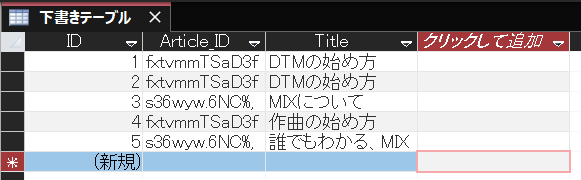
ここから、Article_IDがfxtvmmTSaD3fの下書きだけ取得したい時、今回は全部で5件のテーブルなので全探索で問題ないけど、これが数百万とかになると全データのArticle_IDを調べるのは計算時間が気になってくるよね。
そこで、「Article_IDがfxtvmmTSaD3fであるデータの位置(ID)を記したデータ」を別のところに保存しておく。
例えば、今回の場合はfxtvmmTSaD3f=[1,2,4]みたいな(実際のデータ構造は知らん)。
こうすることで、Article_IDがfxtvmmTSaD3fの下書きを取得したいときは、そのデータを参照して、ピンポイントで取得すれば必要な計算量はArticle_IDがfxtvmmTSaD3fのデータ数だけで良くなるよね。
ここで疑問なのが、Article_IDの種類が数百万あったらどちらにしろそのデータの位置を記したデータを見つけるのに時間がかかるんじゃない? というところ。
これはデータの構造を”いい感じ”に調整して二分探索できるようにするみたい。
マジで仮の二分探索だけど、Article_IDの頭文字のアルファベットで二分探索してみたりね。
そんな感じで高速にデータを取得するのがインデックスというものらしい。
デメリットとして、データを追加、削除するごとにインデックスのデータ構造も更新しなきゃいけなかったり、インデックス用のデータを別に保存するので容量が増えたりするというのがある。
下書きテーブルの作成
“php artisan make:migration create_drafts_table”
でマイグレーションファイル作る
内容は以下の通り(後にtitleとbodyをnullableにし、tagsカラムも追加・nullableしました)
public function up()
{
Schema::create('drafts', function (Blueprint $table) {
$table->id();
$table->unsignedBigInteger('article_id');
$table->string('title');
$table->longText('body');
$table->timestamps();
$table->foreign('article_id')->references('id')->on('articles')->onDelete('cascade');
});
}
public function down()
{
Schema::dropIfExists('drafts');
}仕様の実装
要件は以下の通り
- 新規投稿ボタンを押す
- Articleテーブルで一意となるArticle_IDの生成・同時にそのArticleIDを持つ下書きを下書きテーブルに作成
- 編集途中で「下書きを保存」ボタンを押すと既存の下書きを上書き。
- 編集途中で「閉じる」ボタンを押すと、新しく下書きテーブルに現在の下書きを保存。こうすることで、バージョン毎に保存、バージョンは日付で管理。
- 下書きを再編集する際は、好きなバージョンのものから選び、編集ページへ。
- “投稿”ボタンを押すと、Articleテーブルに下書きの内容を上書き保存する。
“php artisan make:model Draft -cr”
でモデルファイルとコントローラの作成。ここでマイグレーションファイルも同時に作ればよかったね。
上の要件を満たすために必要そうな修正・追加は
- 新規投稿ボタン押下時に新規下書きとArticleIDを生成する仕組み
- 下書き保存時に既存下書きに上書き保存する仕組み
- 閉じるボタンを押下時に新しい下書きを保存する仕組み
- 投稿ボタン押下時にArticleテーブルに作成する仕組み
- 投稿ボタン押下時、既にArticleがある場合、それを上書きする
- 下書き一覧view
- 下書きの各バージョンを閲覧できる仕組み
- 下書きから編集画面に飛ぶ仕組み
こんなもんか?
どうせリレーションを使うので、今のうちにリレーション設定をしておく。
// Articleモデル
class Article extends Model
{
public function drafts()
{
return $this->hasMany(Draft::class);
}
}
// Draftモデル
class Draft extends Model
{
public function article()
{
return $this->belongsTo(Article::class);
}
}あ、これタグとかどうしよう。
タグの存在を完全に忘れてた。
恐らく下書きテーブルに直接保存してしまう方法で問題ないと思うので、そうする。
Draftのマイグレーションファイルを新しく作る前に、タグの文字数制限を変更する。
“php artisan make:migration modify_name_on_table –table=tags”
タグの文字数制限を255/5→51-1(カンマ分)=50文字に変更する。
今までテーブルの設定は128文字だったんだけど、そもそも128文字も長いよね。
中身は以下の通り。(後にnullable)
public function up()
{
Schema::table('tags', function (Blueprint $table) {
//下書き保存の際、タグをString(255文字)で連結保存するので、最大5タグ*50文字+タグの間を区切る4つのカンマ=254文字。
$table->string('name', 50)->change();
});
}
public function down()
{
Schema::table('tags', function (Blueprint $table) {
$table->string('name', 128)->change();
});
}実行しようとしたら以下のようなエラーが出た。

“composer require doctrine/dbal”
でdoctrine/dbalというのをインストールしてあげないといけないみたい。
インストールしたら実行できた。
次に下書きテーブルの更新マイグレーションファイルを作る。
“php artisan make:migration modify_add_tags_drafttable –table=draft”
中身は以下の通り
public function up()
{
Schema::table('drafts', function (Blueprint $table) {
$table->string('tags')->after('title');
});
}
public function down()
{
Schema::table('drafts', function (Blueprint $table) {
$table->dropColumn('tags');
});
}これでどうにかなることを祈ろう。
仕様の実装(リベンジ)
こういうの作るの難しいな。でも、バックエンドやってます感はスゴイ。
とりあえず、要件は色々調整して以下の通り。
新規投稿時
- 新規投稿ボタンを押すと投稿画面へ。
- Articleテーブルで一意となるArticle_IDの生成・同時にそのArticleIDを持つ下書きを下書きテーブルに作成
- 編集途中で「下書きを保存」ボタンを押すと既存の下書きを上書き保存。
- 編集途中で「閉じる」ボタンを押すと、既存の下書きを上書きし、画面遷移。
- 下書きを再編集する際は、好きなバージョンのものから選び、編集ページへ。
- “投稿”ボタンを押すと、Articleテーブルに下書きの内容を上書き保存する。
この時も既存の下書きを上書き。
編集時
- 編集ボタンを押すことで編集画面へ。
- Articleがあれば記事、無ければ下書きを表示
- Articleがあれば、その内容の下書きを作成、無ければ下書きの内容を複製、新しい下書きを作成し、それに保存していく。これは、バージョン管理の為。
- 編集途中で「下書きを保存」ボタンを押すと新しい下書きを上書き保存。
- 編集途中で「閉じる」ボタンを押すと、新しい下書きに上書き保存し終了。
新規投稿時の、「Articleテーブルで一意となるArticle_IDを生成」というところが少し厄介。
一回new ArticleでArticleを生成してしまってもいいんだけど、下書きを投稿しないとそのArticleデータは無駄になってしまうし、作成された日付とかもちょっと面倒そうだよね。
だから、ちょっと色んなIDを比較してみる。
今回見るのはUUID,uniqid(),ULID
UUID(Universally Unique IDentifier)とはなにか
UUIDは”恐らく”世界で一意なIDのこと。
この”恐らく”っていうのは難しいところで、大体はぶつかんないけど、230京回UUIDを生成するともしかしたら衝突するかもね、くらい。ソースはこれ。
UUIDの例:a738e09a-c332-e3ff-781f-27604cab10ca
なぜ世界で一意になるのかというと、MACアドレスという機器についている一意のIDと時刻を使っているかららしい。あと、128bitの長さなので、
340澗=340282366920938463463374607431768211456通りのIDがあるっていうのも強い。
逆に言えば、128bit以上の容量を食ってしまうし、DBのインデックス的にちょっと非効率とかそういう問題はあるみたい。
うーん。
uniqid()とはなにか
PHPの標準機能にあるid生成機能。
ドキュメントはこちら。
これは、現在時刻をマイクロ秒単位で見てそこからIDを生成するというもの。
だから、マイクロ秒まで同じ時刻だと同じIDが生成されてしまうという欠点がある。(なんか、マイナンバーでそんな問題があった気がする)
長さは13文字と26文字の2種類。
uniqid(13文字)の例:6503ca7b11baf
ULIDとは何か
ULIDはUUIDをソート可能にしたバージョン。
同じ128bitらしいんだけど、最初の48bitをタイムスタンプにしているのでソートが可能なんだとか。
Laravelでは9.30からULIDに対応していて、9.31以上が安定版みたいなので9.31以上で使いたい感じ。
因みにLaravel公式ドキュメントはこちら。
また、個人的推しポイントに、IDの表示形式がある。
ULIDの例:01gd6r360bp37zj17nxb55yv40
こんな感じで、UUIDより少し短い。
UUIDって「a738e09a-c332-e3ff-781f-27604cab10ca」みたいな感じで長いし、途中でハイフン入るし、あんまり見た目が良くないのよね。
なので、URLにするならULIDのがいいかなぁという感じ。ソートできるし。
IDをBigIntからULIDに変更する(大工事)
これ、気軽に「ULIDにしよ〜」とか思ってたけど、結構大工事ですねこれ。
問題点は2つ
- 既にある記事のIDはULIDじゃないからエラーになる
- 他のテーブルのArticleIDもULIDに更新しなきゃいけない
うーん。正直、ちゃんとした記事は私が書いた記事1本だけなので、freshで消しちゃっていいか。
他のテーブルとかも色々調整しないとなぁ。
ArticleIDを使ってるテーブルはarticle_tagテーブル、likesテーブル、draftテーブルの3つくらいだった。
これ、一々マイグレーションファイル作ってもいいんだけど、ちょっと流石に面倒だしどちらにしろArticleDBの内容全て消すので一回freshしちゃう。
ついでに、何個の下書きが生成されたとか見られると過疎ってるのがバレるので、draftsのidもULIDにしちゃう。
超大幅に仕様調整した。
さぁ、動くかな?

そりゃあ、動きませんよね。
どうやら、ArticleテーブルにそんなArticleIDは無いのに連携しようとしているのがダメみたい。
うーん、Article_IDを外部制約ありとなしで2個作るとか考えたんだけど、下書きが複数出来たときの更新が複雑になったりで、ちょっとパス。
やっぱり一回中身のないArticleを作って、article_statusカラムで公開状況を管理するのがいいかなぁ。下書きを投稿しないとその中身のないArticleは意味がなくなっちゃうんだけど、しょうがないね。
下書き管理画面(記事管理画面)をどうするか
これは完全にnoteを参考にさせていただく。
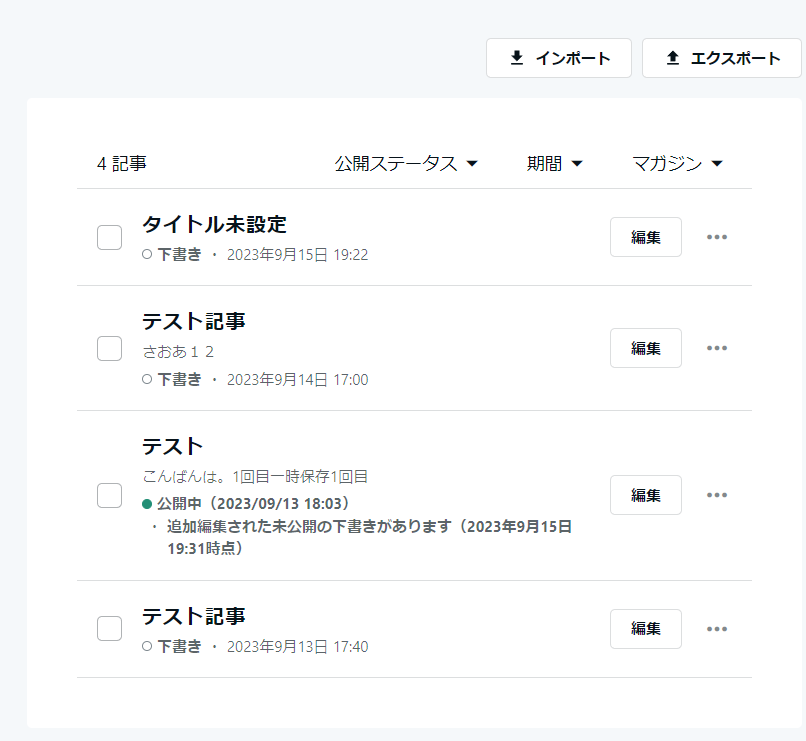
noteはこんな感じで、記事毎にデータを集めて管理している。
公開中の記事をクリックすると公開している記事に飛び、下書きのものは下書きの編集ページに飛ぶ。
しかも、ご丁寧に公開後に少し手を加えると”未公開の下書きがあります”って教えてくれるんだよね。
とりあえず、マジで色々やってどうにか実装。
もう、記事投稿システムの基盤から変えたので、結構大変だった。
下書きシステムを使うと
とりあえず、どんな内容なのかから。
ログインしているユーザーは「投稿する」ボタンを押すと、「新規投稿」か「記事の管理」かが選べる。
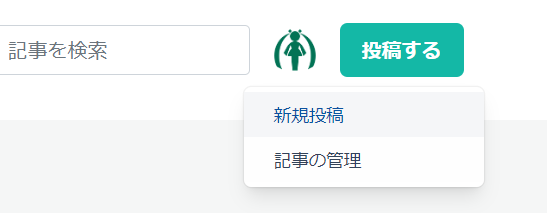
「新規投稿」を押すと、真っ新な記事の編集画面へ。
そこで、色々書き込む。
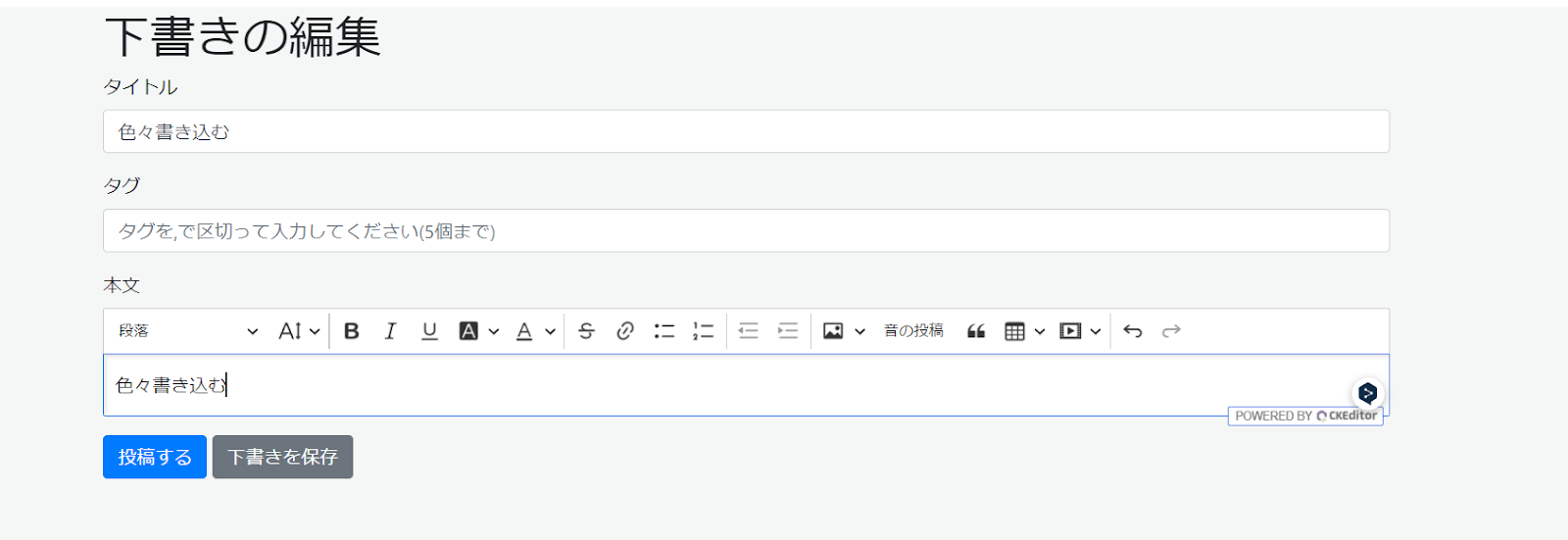
編集して、保存したいなと思ったら「下書きを保存」ボタンを押してもらう。
「下書きを保存」ボタンを押すと下書きを保存して同じ画面へ。
一回ここで、記事の管理画面に行ってみる。
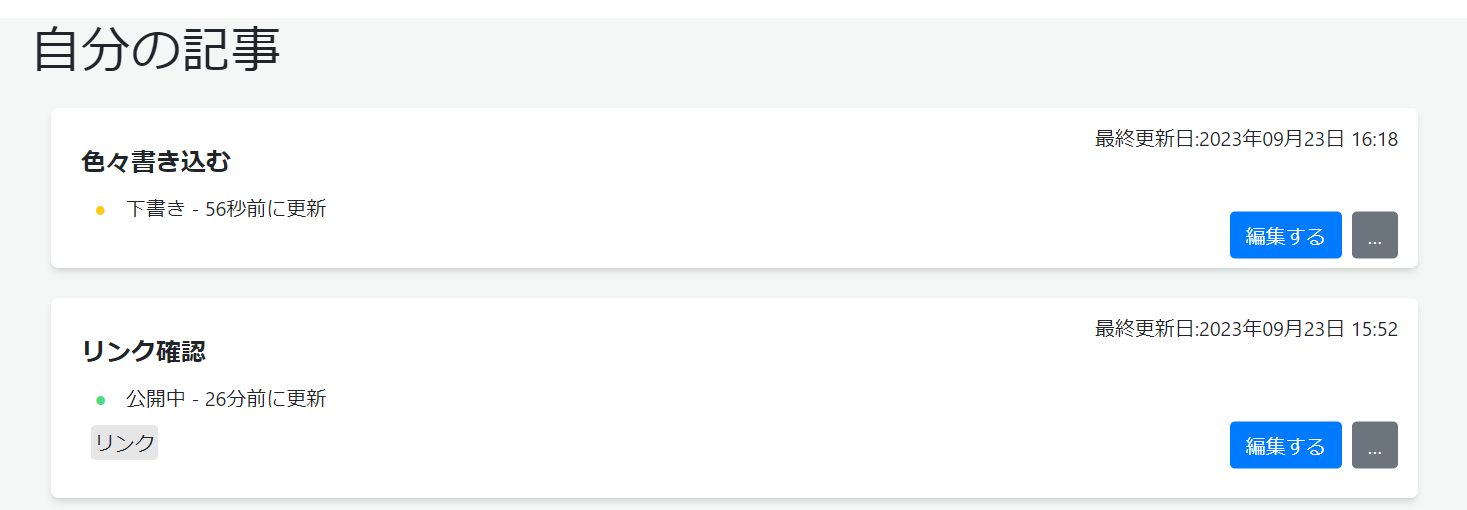
記事の管理画面では自分で作成した下書きとか、記事とかの状態が確認できる。
下書きを再編集するときや、記事の再編集・公開状態を変更するときはここから。
「編集する」ボタンからさっきの編集画面に戻り、「投稿する」ボタンを押せば投稿完了。
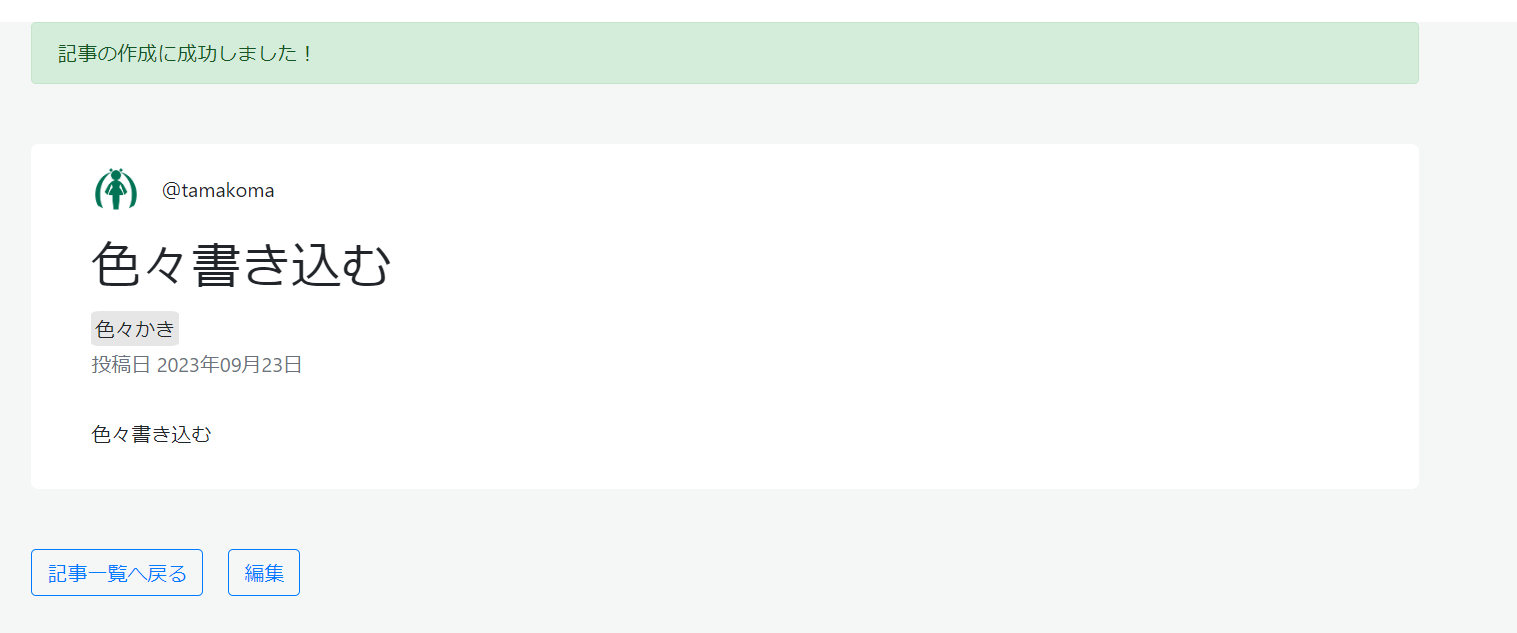
すっっごい単純なシステムそうだけど、結構難しかった。
私が作成した下書きシステムの仕組み
整理しきれていないので、将来の自分の理解の為にもメモしていく。
従来の記事投稿システム
今までの記事投稿システムっていうのは、
- 新規作成ボタンをクリック
- 記事の編集画面に遷移
- 色々編集する
- 投稿ボタンを押す
- Articleテーブルにここで初めて記事の作成、追加。
- 記事が公開される
という単純なシステムだった。
でも、これだと記事の編集を中断できないので、不便。
そこで、下書きシステムの実装。
下書きシステム
今まで記事は作成した瞬間公開されて、非公開とかいう概念が無かったんだけど、Articleのカラムにstatusカラムを追加して、[公開,非公開,投稿前]という3つの状態を保持するようにした。
そして、下書きテーブルを追加して、Articleテーブルと多対一の関係にする。
仕組み的には以下のようになっている
- 新規作成ボタンをクリック
- Articleをstatusが”投稿前”で記事の作成
- その記事IDを使い新規下書きの作成
- 下書きの編集画面に遷移
- 「下書きを保存」ボタンを押す
- $is_first_saveがTrueなら、新規下書きを作成しそこに内容を保存し、$is_first_saveをFalseに。
- $is_first_saveがFalseなら、既存の下書きに上書き保存。
- 「新規投稿」ボタンを押す
- $is_first_saveがTrueなら、新規下書きを作成しそこに内容を保存
- $is_first_saveがFalseなら何もしない
- Articleに下書きの内容を反映し、statusを”公開”に上書き保存。
という少しややこしい構造になっている。
$is_first_saveというフラグで新規セーブか否かを確認しているのは、何個も無駄に新しい下書きを保存しないようにする為。
メディアのリンクを埋め込めるようにしたい
現在の仕様でYouTubeとSoundCloudのリンクを貼り付けて記事を見てみる。
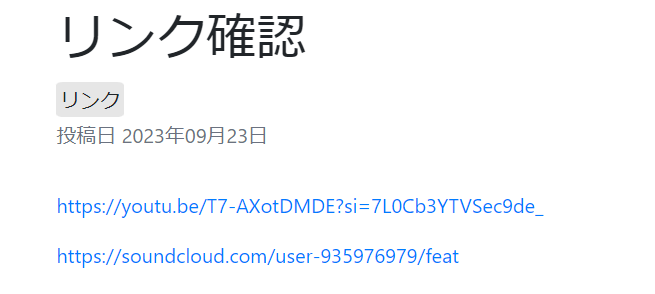
うーん。流石に殺風景。
次に、WordPressに同じリンクを入れてみる。
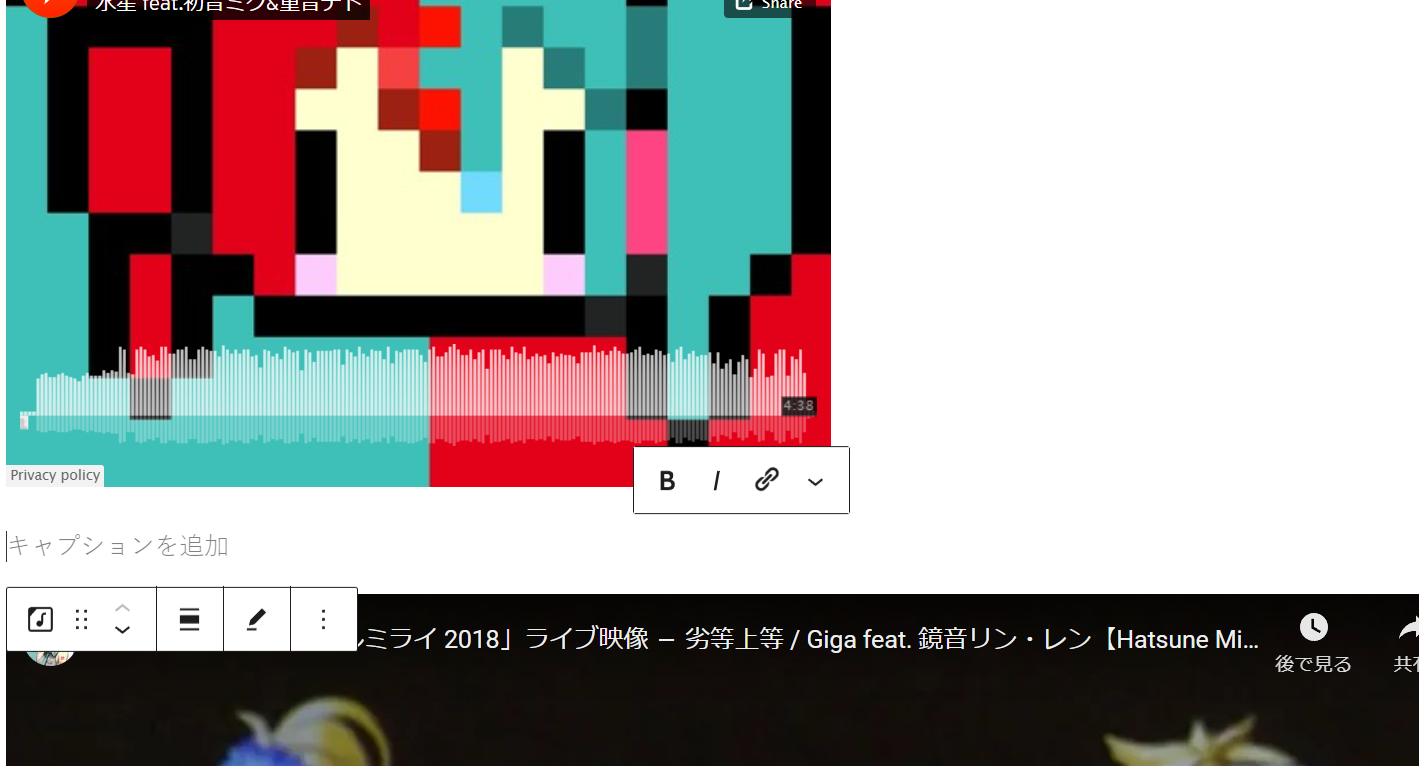
デカすぎて1画面に収まらないんだけど、こんな感じで埋め込むことができる。
まあ、こっちの方がいいよね。
これはoEmbedという仕組みらしく、普通はIFrameとか言うタグで一々色々指定してHTMLを作らなきゃいけないんだけど、oEmbedを使うとサイトが用意してくれているAPIを経由して既に成型されたIFrameを取得できるよというものらしい。
だから、このoEmbedタグを付けて、APIの処理を書いちゃえばいいんだけど、HTMLPurifierがサニタイズしちゃうんだよね。
編集画面だと、しっかり表示されるけど、
記事公開画面だと何も出てこない。
だから、このoEmbedタグを許可したい。
色々調べたんだけど、HTMLPurifierがメジャーじゃないのかマジで情報が無い。
だから、もうCKEditorのエスケープ処理に全て任せて、HTMLPurifierは削除してしまおうかとも考えたんだけど、CKEditorを通さないPostリクエストとか送られるとエスケープ処理を通過されちゃうんだよね。
だから、出来る事としては
- CKEditorを頑張って弄り、oEmbedタグじゃなくiFrameタグにする
- HTMLPurifierを頑張って弄ってoEmbedタグを許可する
- HTMLPurifier以外のサニタイズ処理を探す
のどれかな気がする。
うーん、色々調べたんだけど、どちらにしろHTMLPurifierでoEmbedタグは許可したいし、これからのことも考えてHTMLPurifierは使えるようになりたい。
ちょっと調べて見た感じ、私にはHTMLの基礎が理解できてないと思ったので、HTMLとかそこらへんの基礎を復習。
HTMLとは
まさかHTMLについてやるなんて。
昔学んだと思うんだけど、もう忘れてて何となくでしか理解していなかったので。
これ、どこからしっかり理解するのがいいんだろう。基礎の基礎からとかになるとhttpとかの話になる気がするので、自分の気になるところだけ。
ソースはとほほ様。
何も見ずに説明は出来ないっていう要素を挙げてみる。
HTMLの個人的に知りたいこと
- HTMLってどこが作ってどこが管理してるの?
- oEmbedタグって非公式のタグなの?
- カスタムタグってなんなの?
- HTMLってどう処理されているの?
- HTML,CSS,JavaScriptの関係を知りたい
Q.HTMLってどこが作ってどこが管理してるの?
Q.HTMLってどこが作ってどこが管理してるの?
A.1989年にスイスのCERN(欧州原子核研究機構)が作ってて、2019年まではW3Cが、それ以降はWHATWGが管理している。
この”管理”というのは少し語弊があるかもしれない。正確にはHTMLの標準を勝手に決めて、宣言してるみたいな感じ。iSOみたいな標準化をしてる。
最近ではWHATWGという団体が宣言した標準化が多くの企業に採用されてるので、実質管理してる状態になってるみたいな感じ。
詳しい歴史はこちらを。
Q.oEmbedタグって非公式のタグなの?
Q.oEmbedタグって非公式のタグなの?
A.Yes
そもそもoEmbedは規格・プロトコルのこと。つまり、HTTPみたいな感じ。
「あんたのサービスを埋め込ませてくれ」というリクエストがあったら、oEmbedの規格・ルールでレスポンスしようというのがoEmbed。
それを、あまり意識しなくてもCKEditorでは、CKEditor側で<oembed>というカスタムのタグを使うことで気軽に出来るようになってる。
ここは想像だけど、CKEditorのシステムは恐らく以下のようになっている。
- <oembed>タグがあったら、そのURL取得し、URLからサービス提供元にoEmbedプロトコルでリクエストを送る。
- サービス提供元からレスポンスを受け取ったら、HTMLを構築
- <oembed>タグがあったところにHTMLを代入
みたいな。
ここで、ちょっと疑問があって、カスタムタグってなんなの? というところ。
カスタムタグってなんなの?
カスタムタグはjavascirptで定義できるらしい。
ここら辺はJavaScriptを勉強しないといけないっぽいけど、JavaSciriptはプログラミング言語なので、結構どんなタグでも追加できるっぽい。
デメリットは、もし同じタグ名のタグが追加されてしまうと重複してしまいバグってしまうとか、そういうとこらしい。
いや、そもそもHTMLで定義したタグ? とか独自で定義したタグ? とかよくわからん。→そもそも、HTMLってどこでどう定義されて、どう処理されているの?
HTMLはどう処理されているのか
例えば、PythonであればPythonを管理している団体があって、そこがPythonのインストーラーを配布しているわけだけど、HTMLってなんなの?
A.現在はWHATWGが規定したルールが様々なブラウザで採用されており、そのルールに合わせたレンダリングエンジンを各ブラウザが開発・運用をしている。つまり、ブラウザが処理をしている。
なるほど、ブラウザ自体がHTMLを処理するソフトウェアで、HTMLのルールはWHATWGが制定しているから、それに合わせたレンダリングエンジンを各ブラウザ(Googleやfirefoxなど)が作ってるのか。
今まではW3Cという団体のルールが各ブラウザで採用されてたんだけど、色々不満があってChrome,safari,firefoxらへんがWHATWGのルールを採用し始めたらしい。そこで、ずっとW3C派だったMicrosoftが折れてWHATWGのルール採用へ→実質WHATWGがHTMLの標準化へ。みたいな。
ここら辺もとほほさん。
HTML,CSS,JavaScriptの関係を知りたい。なぜこの3つが主にWebで使われてるの?
そもそも、こやつらはどんな関係で、なぜこの3つが主にWebで使われてるの?
ここらへんはこちらのzenn記事が分かりやすいかも。
超端的に言ってしまえば、ブラウザが標準でHTML,CSS,JavaScriptに対応してるから、この3つが使われている。
いままでこの3つが使われてきたから、今も使われてるって感じ。
CSSはW3Cが管理していて、JavaScriptはTC39というところが管理しているみたい。
それぞれで標準化を宣言して、ブラウザ側がそれに合わせたレンダリングエンジン・JavaScriptエンジンを開発・運用しているということ。
HTMLの文法やらを少し復習
正直ここら辺も怪しいので。
タグ→<html>とか<li>みたいなやつ。大文字小文字は関係ない。
ブロック要素→親要素いっぱいまで広がる要素。こちらで命令しないと必ず自動改行される。つまり、横並びにブロック要素が並ぶことは自然には無い。
インライン要素→要素の大きさは要素の中身に比例する。インライン要素どうし並ぶことができる。
要素に関してはこちらの記事が分かりやすい。
属性→タグの中で指定できる変数的な物。クラスでいうプロパティ的な。代入・指定する値のことを属性値という。例:<a href=””>のhrefが属性。
HTMLPurifierを弄ってみる
少しは理解できたので、弄ってみよう。
……といっても、マジで英語すぎるよ公式ドキュメント。
頑張って理解していくしかないね。
私がやりたいのは
- oembedタグの許可
<oembed url=”https://media-url”></oembed>
CKEditorでは上のような構造になっているので、url属性のURLを制限したい。(youtubeのみとか) - そもそもリンクの許可を少し弄りたい。
これ、色々弄ってて思ったんだけど、oembedタグを許可する必要は無いのでは?
oembedタグが勝手にiframeに置き換わるから、iframeを許可する設定をする必要があるのでは?
実際に、編集画面の方をデベロッパーツールで見てみると
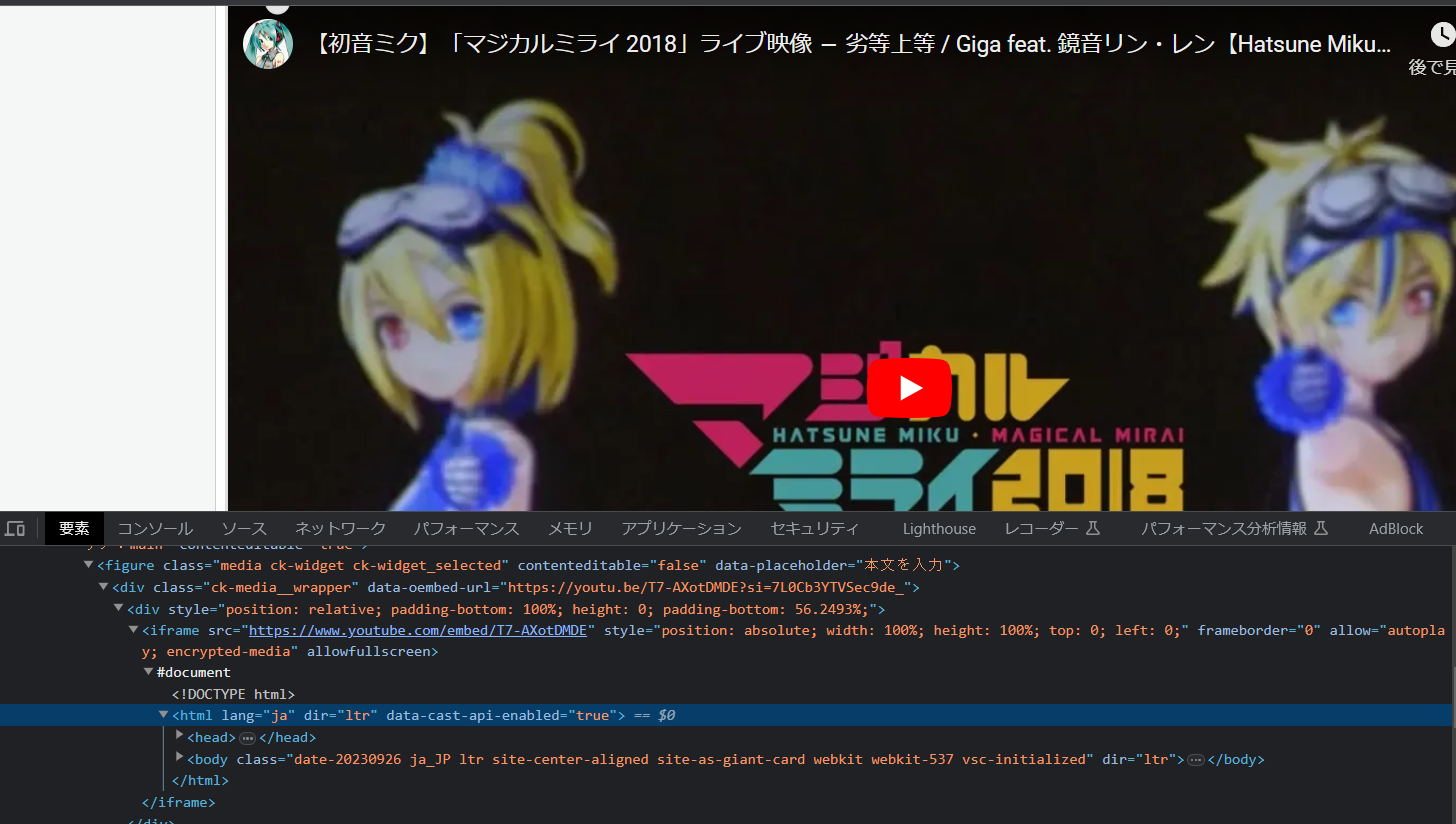
小っちゃくて分かり難いかもなんだけど、
<iframe src=”https://www.youtube.com/embed/T7-AXotDMDE” style=”position: absolute; width: 100%; height: 100%; top: 0; left: 0;” frameborder=”0″ allow=”autoplay; encrypted-media” allowfullscreen=””></iframe>
みたいな感じで。iframeタグになってるんだよね。
なので、一回iframeタグを許可する設定を模索する。
いや、訂正。
サニタイズなしで見てみたらちゃんとoembedだった。

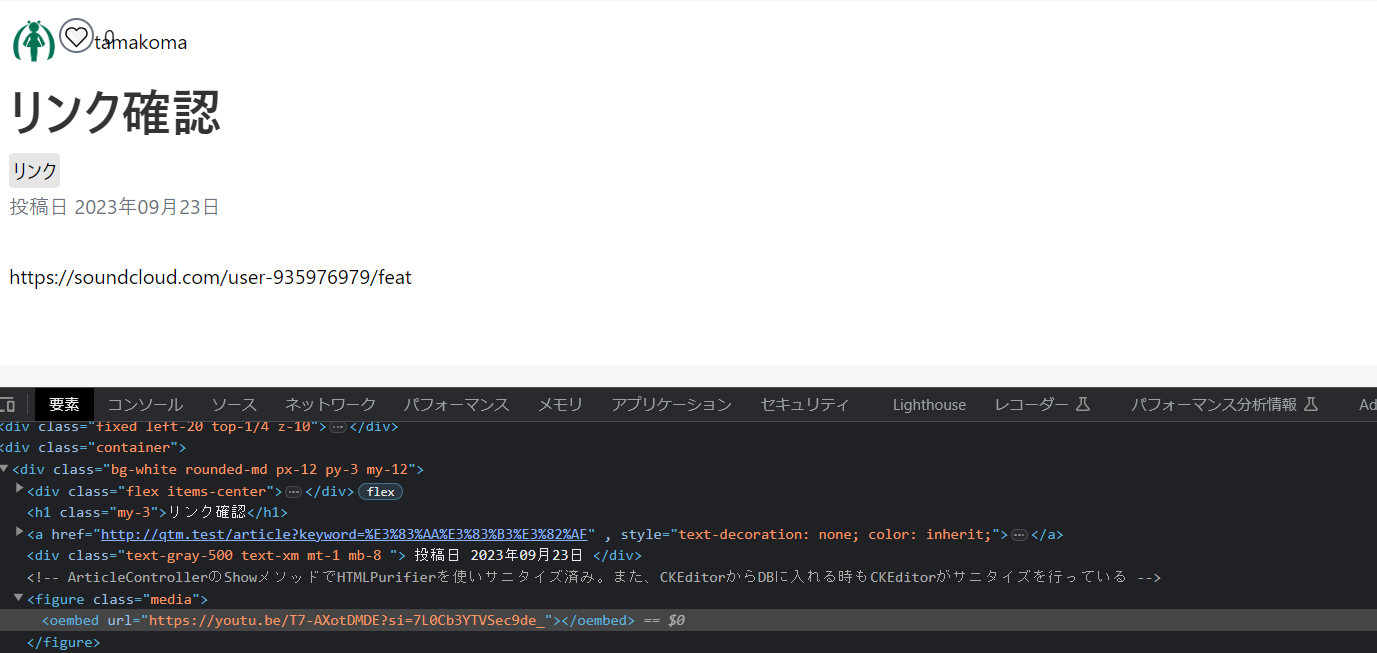
これ、当たり前っちゃ当たり前だけど、oEmbedの設定を何もしてないから、何も表示されないのか。
ちょっとそこら辺の設定を弄って、しっかりoEmbed処理が出来るようになってからサニタイズを弄る。
YouTubeのoEmbed処理を書く
とりあえず、実装したいのはYouTube。次点でSoundCloud。
とにかく、YouTubeに対応できないと意味が無いので、そこからやる。
JavaScriptはマジで分からないので、ChatGPTに以下のAPI処理をしてもらうコードを出力してもらった。
<script>
document.addEventListener('DOMContentLoaded', (event) => {
// ページ上のすべてのoembedタグを取得
document.querySelectorAll('oembed[url]').forEach(element => {
// oembedタグのurl属性からURLを取得
const url = element.getAttribute('url');
// YouTubeのoEmbedエンドポイントにリクエストを送信
fetch(`https://www.youtube.com/oembed?url=${encodeURIComponent(url)}&format=json`)
.then(response => {
// レスポンスがOKでない場合、エラーをスロー
if (!response.ok) {
throw new Error('Network response was not ok ' + response.statusText);
}
return response.json();
})
.then(data => {
// レスポンスから得られたiframeコードを元のoembedタグの位置に挿入
element.outerHTML = data.html;
})
.catch(error => {
console.error('There has been a problem with your fetch operation:', error);
});
});
});
</script>一応これで開いてみると……
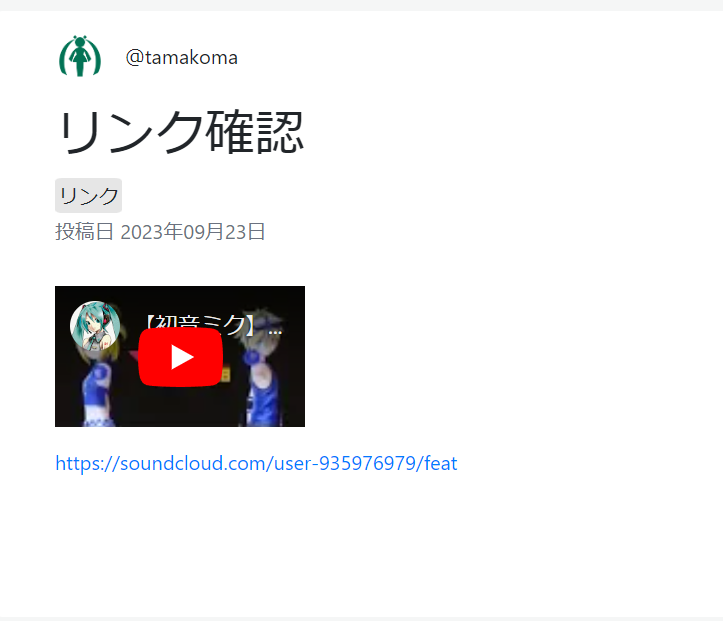
小さいながらも、いい感じに動いてはくれている。
このコードを理解する。
- document.addEventListener(‘DOMContentLoaded’, (event) => {
documentというのがHTMLを表すものらしい。
addEventListenerというのが、イベント処理をするもの。
DOMContentLoaderがそのイベント処理を開始する条件みたいなもので、このDOMContentLoadedは全てのHTMLが読み込まれてから処理を開始するというもの。遅延処理ってやつ? - document.querySelectorAll(‘oembed[url]’).forEach(element => {
querySelectorAllは文字探索的なもの。
oembed[url]がその文字探索の条件で、oembedタグのurl属性を持つものを取得して、forEachで回してる感じ。 - const url = element.getAttribute(‘url’);
これは、url属性の値を取得しているだけだと思う。 - fetch(`https://www.youtube.com/oembed?url=${encodeURIComponent(url)}&format=json`)
このfetchというのは、データを引っ張ってくる関数。こちらが分かりやすい。
今回はリクエストを送って取得してるけど、別にローカルのファイルから引っ張ってくることもできるみたい。
「https://www.youtube.com/oembed」がYouTubeのoEmbedAPIのエンドポイント。
URLにはクエリパラメータという、変数を渡せる機能がある。引数的な。
その、クエリパラメータの始まりを「?」で示している。
残りのurl=${encodeURIComponent(url)}&format=json`)がその、引数を渡している感じ。 - 非同期処理
この、fetchは非同期処理・Promiseとかちょっとそういう感じの事をやってて、何が起こってるのか分かり難い。詳しくは以下のYouTubeがおすすめ。
小学生でもわかるasync/await/Promise入門【JavaScript講座】
端的に言えば、fetchは非同期処理なんだけど、1個目のthen→2個目のthenみたいな順序はPromiseによって守られている。
そんで、Promiseの結果をthenに渡しているので、いきなり宣言していないdataとかいう変数が表れている。
CKEditorでSoundCloudのoEmbedに対応してもらう
とりあえず、何となくoEmbed処理の理解は出来たので、CKEditor側にSoundCloudの対応処理も頑張ってもらう。
もう一度CKEditorの公式ドキュメントを見てもらいたい。
Also, the media embed feature does not support asynchronous preview providers yet. Therefore, to still allow embedding tweets or Instagram photos, we chose to:
Show a placeholder of the embedded media in the editor (see e.g. how a tweet is presented in the demo above).
Produce a semantic tag in the data output from the editor. This output makes it possible to later use proxy services to display the content of these media on your website.
The above limitations can be overcome with the help of proxy services like Iframely or Embedly, which is explained in the configuration guide below.
つまり、編集画面では<iframe>タグで表示するけど、表示画面では<oembed url=””>で表示するよということ。
これが意味することは、編集画面と表示画面でそれぞれ処理を書かなきゃいけないということ。
うーん……面倒! と思ったら、どうやらCKEditorの設定で対応プロバイダーを追加できるみたい。詳しくはこちら。
コードは以下のような感じ
mediaEmbed: {
extraProviders: [
{
name: 'soundcloud',
url: /^https:\/\/soundcloud\.com\/.+/,
html: match => {
const embedUrl = `https://w.soundcloud.com/player/?url=${match[0]}&color=%23ff5500&auto_play=false&hide_related=false&show_comments=true&show_user=true&show_reposts=false&show_teaser=true`;
return (
`<iframe width="100%" height="166" scrolling="no" frameborder="no" allow="autoplay" src="${embedUrl}"></iframe>`
);
}
}
]
}これは、正規表現でhttps://souncloud.com/ + なにか任意の文字と一致する文字ということ。
embedUrlは、soundcloudの埋め込みができるurlを取得してきてる。
returnでは、編集画面で表示するhtmlを返している。
結果編集画面ではこんな感じで表示される。

悪くないね。
view画面では、oembedの対応をしていないので、何も表示されない。
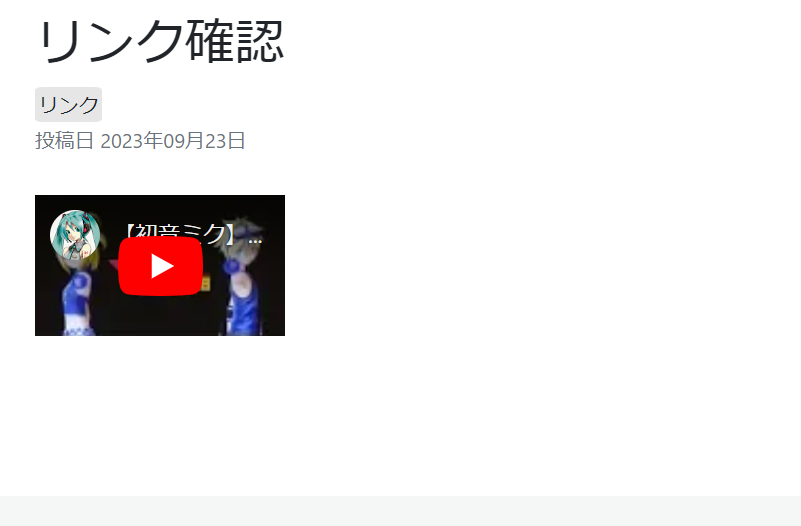
YouTubeとSoundCloudでそれぞれoEmbed対応させる
……といってもjavascriptで条件分岐書いてやるだけっちゃだけだと思う。
SoundCloudのoEmbedについてはこちらの公式サイトを。
最終的なコードがこれ
document.addEventListener('DOMContentLoaded', (event) => {
// ページ上のすべてのoembedタグを取得
document.querySelectorAll('oembed[url]').forEach(element => {
// oembedタグのurl属性からURLを取得
const url = element.getAttribute('url');
let oEmbedUrl;
// URLがYouTubeまたはSoundCloudのURLであるかどうかを確認
if (url.includes('youtube.com') || url.includes('youtu.be')) {
oEmbedUrl = `https://www.youtube.com/oembed?url=${encodeURIComponent(url)}&format=json`;
} else if (url.includes('soundcloud.com')) {
oEmbedUrl = `https://soundcloud.com/oembed?url=${encodeURIComponent(url)}&format=json`;
} else {
console.error('Unsupported URL:', url);
return;
}
// 対応するoEmbedエンドポイントにリクエストを送信
fetch(oEmbedUrl)
.then(response => {
// レスポンスがOKでない場合、エラーをスロー
if (!response.ok) {
throw new Error('レスポンスエラー:' + response.statusText);
}
return response.json();
})
.then(data => {
// レスポンスから得られたiframeコードを元のoembedタグの位置に挿入
element.outerHTML = data.html;
})
.catch(error => {
console.error('fetchでエラーが発生しました:', error);
});
});
});見た目が以下みたいな感じ。

うん、いいけどSoundCloudちょっと大きいし、YouTubeはちょっと小さいな。
最後のthenを更新して以下みたいにしてみた。
.then(data => {
// レスポンスから得られたiframeコードを元のoembedタグの位置に挿入
let iframeHTML = data.html;
// YouTubeおよびSoundCloudの埋め込みの大きさを調整
if (url.includes('youtube.com') || url.includes('youtu.be')) {
iframeHTML = iframeHTML.replace('width="200"', 'width="400"').replace('height="113"', 'height="226"');
} else if (url.includes('soundcloud.com')) {
iframeHTML = iframeHTML.replace('height="400"', 'height="200"');
}
element.outerHTML = iframeHTML;
})結果はこんな感じ。

SoundCloudはちょっと無理やりサイズ調整した感もあるけど、いったん勘弁してもらう。
HTMLPurifierを頑張ってoEmbed対応してもらう
めっちゃ忘れてた。そういえばHTMLPurifier切ってるんだった。
頑張るかぁ。
こちらの公式ドキュメントを参考に進めていくけど…本当に情報と英語力が無い。
色々弄ってたら解決策が分かったぞ!
これ、HTMLPurifierの公式ドキュメント見ても意味あんまない。
私が使っているHTMLPurifierはLaravel向きに最適化されたこれだった。
というか、audioタグを許可した時と同じ方法で良かった。完全に忘れてたよ。
やったことは
config\purifier.phpの’custom_definition’ => [に
['oembed', 'Inline', 'Empty', 'Common',[
'url' => 'URI',
]],を足して、figureを修正して
['figure', 'Block', 'Optional: (figcaption, Flow) | (Flow, figcaption) | Flow', 'Common',[
'class' => 'Text'
]],こんな感じにして、’HTML.Allowed’にoembed[url],figure[class]を足すだけ!
結果!
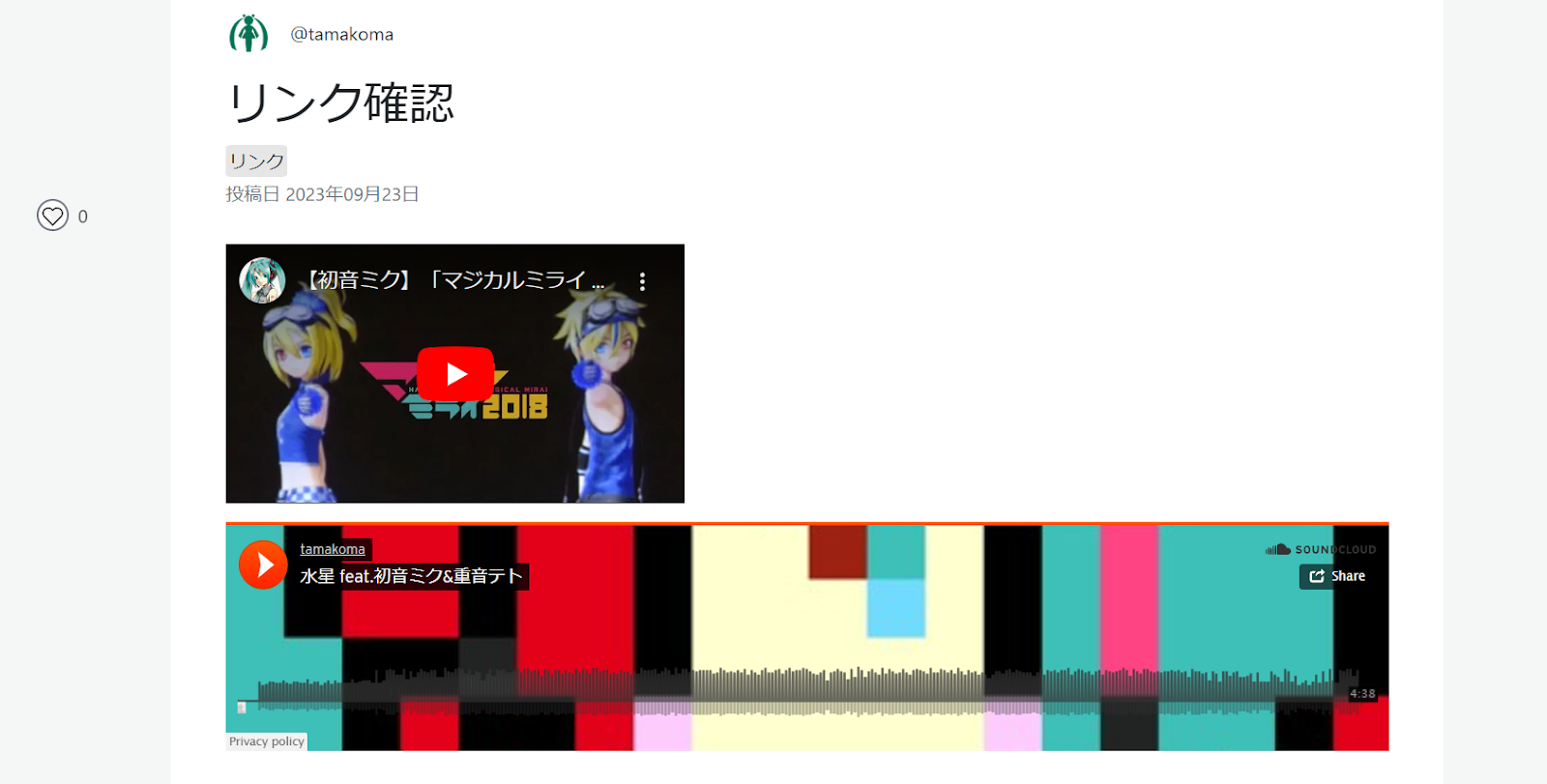
ようやく実装できた。
マジで埋め込みだけで1週間くらいかかったのでは。
下書きとoEmbedに時間を掛けすぎて次に何がしたかったか忘れちゃった。
おわり
とりあえず、まだまだ改善したいところはあるんだけど、ちょっとフロントエンドというか、JavaScriptとかも関わってきそうだし、めっちゃ長くなったのでこんなもんで。
おやすみなさい。

