2024年1月6日~2024年2月3日
あけましておめでとうございます。
今年も引き続きやっていく。
- 残りの流れ&タスク
- TelescopeでLaravelを見える化する
- クエリを改善する
残りの流れ&タスク
- テスト
- DUSKテスト
- 通常テストでRequest1個までに修正
- デプロイ環境で手動テスト
- N+1の確認
- OWASP
- CKEditorの項目を確認(とりあえず最低限だけ実装)
- 減らすのは大変だけど、増やすのは容易
- zenn作者様の記事を参考に改善
- サービスの名前・アイコン・メールやらやる
- ドメイン
- アイコン
- googleアカウント
- 商標登録
- ドメイン登録
- デプロイして、メールサーバーとかの設定
- 利用規約・プライバシーポリシー
- 後から追加しにくい・変更しにくい実装は無いか?
- 簡易リリース
- SEOを考える
- title
- メタタグ
- OGPの設定
- X(Twitter)は別
- rel=”noopenner noreferrer”
参考にする文献
- 個人開発にてWebサイトやWebサービスを作るときにだいたい使うもの【準備・開発・運用】 #備忘録 – Qiita
- 詳しい色々な話
- 【個人開発】わが子の可愛さあまりフルスタックエンジニア化した男の話
- 人に早く見せた方がいい話
- 個人サービスを公開するまでに必ずやるべきこと
- 詳しい色々な話
TelescopeでLaravelを見える化する
LaravelにはTelescopeというデバッグツールがある。
Telescopeの日本語ドキュメント、GitHub。
とりあえず、使えるようにする。
Telescopeのインストール
composer require laravel/telescope –dev
ローカル環境のみで利用したいので、–devを付けてダウンロード。
その後installコマンド
php artisan telescope:install
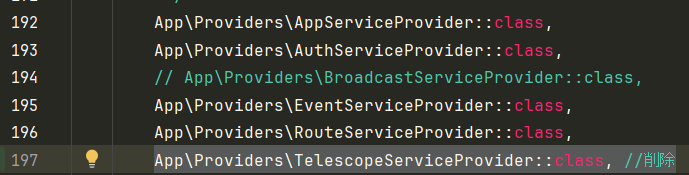
installコマンドを打ったら
config/app.phpにあるTelescopeServiceProviderを削除する。
代わりにApp\Providers\AppServiceProviderのregister()メソッドにlocalを条件に追加。
public function register()
{
if ($this->app->environment('local')) {
$this->app->register(\Laravel\Telescope\TelescopeServiceProvider::class);
$this->app->register(TelescopeServiceProvider::class);
}
}こうすると、envのAPP_ENVがlocalの時だけTelescopeが動くようになる。
更に、composer.jsonのdont-discoverにtelescopeを追加して、自動検出を切る必要もあるみたい。
"extra": {
"laravel": {
"dont-discover": [
"laravel/telescope"
]
}
},最後に
php artisan migrate
すればおk。
以上の設定で、local環境のみTelescopeが動くようになった。
「自分のサイトアドレス/telescope」で見れる。
データの刈り込み設定をしておく
前、1カ月ごとにユーザーの利用可能データ量をリセットするというscheduleを追加したんだけど、それと同じようにTelescopeもscheduleを利用してデータをリセットした方が良い。
Telescopeはアクセス全てを記録しDBに保存するので、すぐにDBが圧迫されてしまう。
だから、データを削除する。
Laravel側の設定は簡単なんだけど、cronというLaravelとは別のスケジューラ―ツールを利用するので、メモ。
まず「app\Console\Kernel.php」に
$schedule->command(‘telescope:prune’)->daily();
を追加する。
これは「vendor\laravel\telescope\src\Console\PruneCommand.php」に定義されているコマンドで、24時間過ぎたデータを削除するというもの。
でも、この設定だけではダメで「php artisan schedule:run」というコマンドを毎分実行してやる必要がある。
そこで、本番環境ではcronというスケジューラを使う。
※ローカルなら「php artisan schedule:run」でもいいみたい。ソース。
cron
今回は本番環境を想定してcronを使ってみる。
日本語ドキュメントはこちら。
また、cronに関してはこちらがわかりやすかった。
私の利用しているAlmaLinuxにはcronが既にインストールされているらしいので、稼働されているか見てみる。
sudo systemctl status crond
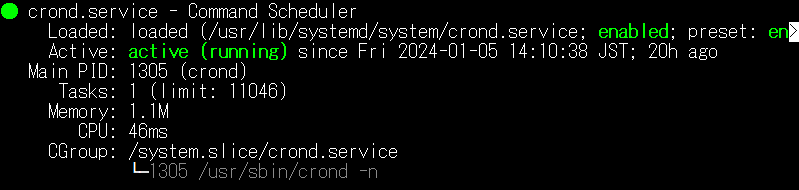
元気に動いてるね。
cronのデーモンはユーザー毎に存在するcrontabに記述された物を元に動くようで、crontabは「crontab [オプション]」で色々弄れるみたい。
「crontab -l」で現在のcrontabが閲覧できるみたいなので、見てみる。
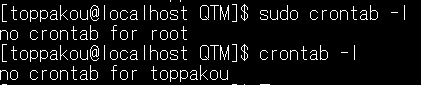
つまり、何も定義されてないんだねこれ。
「crontab -e」でcrontabの編集が出来るみたいなので、編集画面を開いて、
「* * * * * cd [プロジェクトの場所] && php artisan schedule:run >> /dev/null 2>&1」を記述する。
これ、viを起動してるみたいなので、viの操作でおk。
「* * * * * cd [プロジェクトの場所] && php artisan schedule:run >> /dev/null 2>&1」とは
「* * * * * cd [プロジェクトの場所] && php artisan schedule:run >> /dev/null 2>&1」がよくわからないので、理解する。
最初の「* * * * *」が「分,時,日,月,曜日」を意味していて、アスタリスクだと全ての値を意味する。
つまり、「* * * * *」は毎分実行するということになる。
「cd [プロジェクトの場所] && php artisan schedule:run」の&&は、「左のコマンド後、右のコマンドを実行する」ということ。
「npm install && npm run dev」みたいに使える。
次に「>> /dev/null 2>&1」だけど、これが私にはちょっと曲者。
仕組みを理解せずに簡潔に言えば、「このコマンドによって出力される標準出力と標準エラー出力を廃棄する」ということ。
「>> /dev/null 2>&1」を理解する
この「>> /dev/null 2>&1」理解するには
- UNIXは全てをファイルとして理解できる(everything-is-a-file)
- ファイルディスクリプタ
- リダイレクト
- 出力の廃棄
この4つを理解する必要があるのかなと思った。
しかも、しっかり理解しようとすると結構沼で、「UNIXの構造とは」みたいな話になっちゃいそうなので、ある程度妥協しながら理解したい。
「UNIXは全てをファイルとして理解できる」をちょっとだけ理解する
ここをしっかり理解しようとすると沼だったので、本当に浅く。
UNIXでは「すべてをファイルとして扱えるようにする」という設計思想がある。
これは、すべてをファイルとして扱えるようにすることで、シンプルかつ汎用性を高くするというのが目的みたい。
そのため、標準入力、標準出力、標準エラー出力もファイルとして扱えるようになっている。これは、実際にファイルなわけではなく、仮想的にファイルとして扱えるということらしい。
とりあえず、これだけ理解していれば「>> /dev/null 2>&1」の理解には問題ないと思う。
ファイルディスクリプタ(FD)も少し理解する
ファイルディスクリプタは「開いているファイルにアクセスするための識別番号」と思って貰って問題ないのではと思う。
この識別番号は自然数の最小値が自動で割り当てられるみたい。
例えばファイルAを使う時、既にファイルディスクリプタの番号が7まで利用されていたら、そのファイルAには8が適用されて、そのファイルAを開いている間は8を利用してファイルAにアクセスできるという感じ。
ここでさっきのUNIXは全てをファイルとして理解できるがでてくる。
標準入力、標準出力、標準エラー出力もファイルとして扱われており、ファイルディスクリプタの番号がそれぞれ固定で0,1,2と振られている。
つまり、[0=>標準入力, 1=>標準出力, 2=>標準エラー出力]みたいな定義。
「>> /dev/null 2>&1」の1とか2の番号はそういう意味だったんだね。
リダイレクト
「>」や「>>」はファイルへのリダイレクトを指す。
何をリダイレクトするかっていうと、ファイルディスクリプタ(FD)の参照先をリダイレクト(変更)する。
「>」は上書きを意味していて、「>>」は追記を意味する。
使い方は「コマンド [n]> ファイル名」のようになっていて、nにリダイレクトしたいFDの番号を入れ、右側にリダイレクト先のファイル名を書く。
nの初期値は1(標準出力)になっている。
例えば、「cat text.txt > text2.txt」というコマンドは以下のような処理がされている。
- 「cat text.txt」により、text.txtが標準出力ファイル(FD1)に出力される
- 「> text2.txt」により、FD1の出力がtext2.txtにリダイレクトされる
結果、text.txtは標準出力ファイルを介してtext2.txtに出力されるという感じ。
じゃあ、「2>&1」は何なんだというところなんだけど、ChatGPTが面白い説明をしてくれていたので、引用したい。
ChatGPT曰く「 & は、続く数字がファイルではなくファイルディスクリプタを指していることを示しています」とのこと。
確かにその解釈で理解できるなぁと思ったので、引用させていただいた。
つまり、「2>&1」は標準エラー出力の参照先(出力先)を標準出力にしているという解釈。
出力の廃棄
最後は本当に単純で「/dev/null 」への出力は全て廃棄、削除されるという知識。
削除猶予のないゴミ箱みたいな。
「* * * * * cd [プロジェクトの場所] && php artisan schedule:run >> /dev/null 2>&1」の処理を追う
最後にまとめとして処理を追ってみる
- 「* * * * *」で毎分、以降のコマンドが実行される
- 「cd [プロジェクトの場所] 」でLaravelプロジェクトへ移動
- 「 php artisan schedule:run」でartisanコマンドを実行。
scheduleに登録されたコマンドが指定された時間だったらLaravelがそのコマンドを各自実行。 - コマンドにより出力されるものは何も指定していないので、標準出力(FD1)へ
- 「>> /dev/null」により、標準出力(FD1)は全て/dev/nullにリダイレクトされ、削除されるように
- 「2>&1」により、標準エラー出力(FD2)の出力先は標準出力(FD1)へ。
つまり、全て削除される。
こう分割すると、理解できる。
「* * * * * cd [プロジェクトの場所] && php artisan schedule:run >> /dev/null 2>&1」で問題ないのか
今回の場合はローカル環境での実行なので、全ての標準エラー出力は削除してしまっても問題ないと思う。
しかし、本番環境でのエラーは認識したいので、「2>&1」を付けずに何か通知するシステムを作った方がいいのかなと思うなどした。
とりあえず今回は、以下のようにそのままcronを設定してみた。

クエリを改善する
Telescopeが使えるようになったので、早速Telescopeでクエリを見てみる。
例えば、記事の一覧画面にアクセスして
Telescopeを見てみると

/articleにアクセスしたログが残っている。
このログのクエリを見てみると
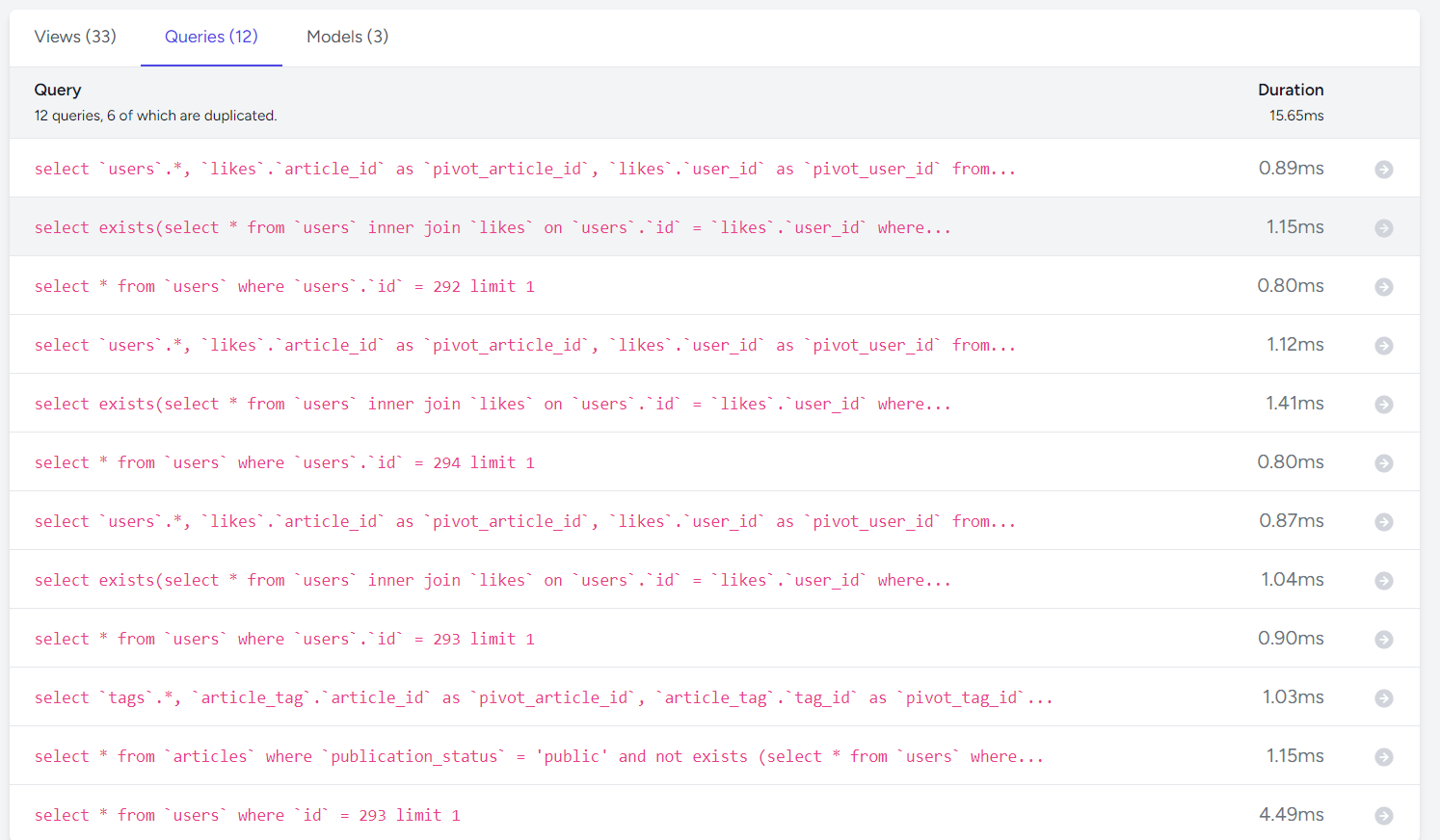
「12 queries, 6 of which are duplicated.」とある通り、12個中6個重複したクエリを発行しており、N+1起きまくり。
パッと見る感じ、articlesに付随するユーザー情報といいね情報の部分でN+1が起きている。
詳細に見ると
- ユーザーが記事をいいねしているかのクエリ
- 記事のいいね数を数えるクエリ
- 記事投稿者を取得するクエリ
を記事毎に発行しているので、かなり無駄になっている。
一回withでユーザー情報といいね情報を取得するようにコードを変えてみる。
この状態でのDurationは15.65msらしいので、どれくらい変わるかを見たい。
クエリをwithでイエーガーロードして、
$articles = $query
->with("tags");から以下に変えた。
$articles = $query
->with("tags")
->with("user")
->withCount("likedUsers")
->withExists("likedUsers");withは知ってるけど、withCountとかwithExistsはドキュメントをしっかり見ないとわかんないよね。
Telescopeを見てみると、
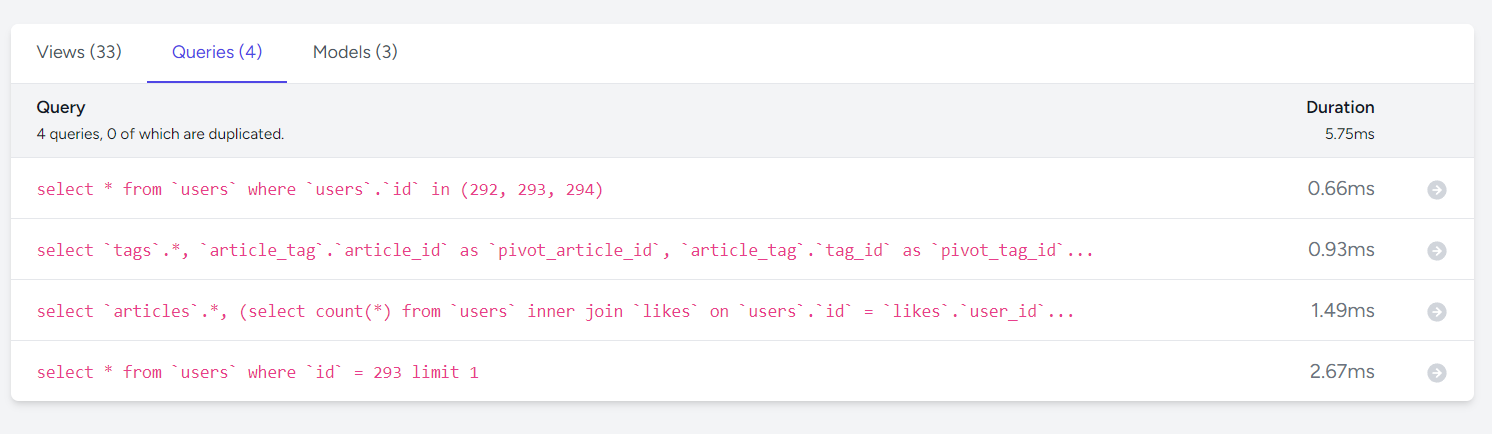
クエリの発行は合計4個で、Durationは5.75ms。
とりあえず、今の状況であればこの方法が良さそう。
レスポンスも見てみる
クエリだけでなく、レスポンスの内容も見ることが出来る。
以下はさっきの記事一覧画面のレスポンスの一部
{
"view": "/media/sf_Share/QTM/resources/views/article/index.blade.php",
"data": {
"articles": {
"class": "Illuminate\\Pagination\\CursorPaginator",
"properties": {
"data": [
{
"id": "01HKFG9F1VVTDH4N2P5D8T0GNA",
"user_id": 293,
"title": "音量・音圧・ラウドネスの違い",
"body": "<p>執筆中</p>",
"publication_status": "public",
"ban_at": null,
"created_at": "2024-01-06T13:45:37.000000Z",
"updated_at": "2024-01-06T13:45:37.000000Z",
"liked_users_count": 1,
"liked_users_exists": true,
"tags": [
{
"id": 4,
"name": "音量",
"created_at": "2024-01-06T13:45:37.000000Z",
"updated_at": "2024-01-06T13:45:37.000000Z",
"pivot": {
"article_id": "01HKFG9F1VVTDH4N2P5D8T0GNA",
"tag_id": 4,
"created_at": "2024-01-06T13:45:37.000000Z",
"updated_at": "2024-01-06T13:45:37.000000Z"
}
},
うん。おおよそ問題ない。というか、Telescopeめっちゃ便利。
おおよその問題はないんだけど、1つだけ問題があって、articleの取得時に必要のないbodyも取得してしまっている。
何も指定せずにArticleを取得しているので、当然と言えば当然。
しかし、bodyはかなりの長さになる可能性があるカラムなので、記事一覧時点では取得してほしくないかなぁ。
これの簡単な解決は、Select句による指定しかないっぽい。
public function scopeBodyExclude($query)
public function scopeBodyExclude($query)
{
return $query->select("id", "user_id", "title", "publication_status", "ban_at", "created_at", "updated_at");
}こんな感じで取得したいカラムを全列挙する。
SQLに特定のカラムを除外する句は無いみたいなので、しょうがないね。
これを適用すると
{
"view": "/media/sf_Share/QTM/resources/views/article/index.blade.php",
"data": {
"articles": {
"class": "Illuminate\\Pagination\\CursorPaginator",
"properties": {
"data": [
{
"id": "01HKFG9F1VVTDH4N2P5D8T0GNA",
"user_id": 293,
"title": "音量・音圧・ラウドネスの違い",
"publication_status": "public",
"ban_at": null,
"created_at": "2024-01-06T13:45:37.000000Z",
"updated_at": "2024-01-06T13:45:37.000000Z",
"liked_users_count": 1,
"liked_users_exists": true,
"tags": [
{
"id": 4,
"name": "音量",
"created_at": "2024-01-06T13:45:37.000000Z",
"updated_at": "2024-01-06T13:45:37.000000Z",
"pivot": {
"article_id": "01HKFG9F1VVTDH4N2P5D8T0GNA",
"tag_id": 4,
"created_at": "2024-01-06T13:45:37.000000Z",
"updated_at": "2024-01-06T13:45:37.000000Z"
}
},おk、bodyを取得しなくなった。
こんな感じで、色んなページの詳細情報を見える化してN+1とか色んな問題を改善していく。
ユーザーがいいねした記事をいいねした順で取得する
Telescopeでクエリの発行数を見ていたら、「ユーザーがいいねした記事」ページでかなりのクエリが発行されていた。
修正しようと思ったんだけど、「ユーザーがいいねした記事をいいねした順で取得」というのが案外難しかった。
そもそも、私がSQLを殆ど知らないのがかなり問題。
元のコード
$likedArticles = $user->likes()
->whereHas("article", function ($query) {
$query
->publicAndNotBanned();
})
->with('article.tags')
->orderBy("id", "desc"); // いいねした順に取得元のコードはこんな感じ。
whereHasという、リレーション関係があるモデルを条件に使い絞り込むというのがあるんだけど、その絞り込み時に取得するArticleを使うという、副作用が本命みたいなゴリ押し方法。
この方法だと、そもそもArticleとLikeに関係するデータがイエーガーロードできていないので、クエリ数が増える。
第一改善案
$likes = $user->likes()
->whereHas('article', function ($query) {
$query
->publicAndNotBanned()
->with(["tags", "user"])
->withCount("likedUsers")
->withExists("likedUsers");
})
->orderBy('id', "desc") // いいねした順に取得安易にこんな感じにすればいいのでは、と思った。
しかし、これだとクエリの重複は減らないし、Like関連のデータが消えていた。

なんでだろうと思ったんだけど、whereHas内のwithとかはwhereHas内で適用されるけど、結果取得時にwithを取得することは無いみたい。
だから、with関連が全て消えてた。
第二改善案
いやいや、そもそもlikes()じゃなく、多対多のリレーションを指定しているはずなので、likedArticles()でArticleを直接取得すればいいじゃんと思って以下みたいにしてみた。
$likedArticles = $user->likedArticles()
->publicAndNotBanned()
->with(["tags", "user"])
->withCount("likedUsers")
->withExists("likedUsers")
->orderBy('likes.created_at', 'desc')
->select("articles.id", "articles.user_id", "articles.title", "articles.publication_status", "articles.ban_at", "articles.created_at", "articles.updated_at", "likes.created_at")
->paginate(config("const.pagination.perPage"));こっちなら必要のないLikeテーブルを取得する必要もないし、綺麗に解決したぁ。と思ってTelescopeを見てみると。
何故か記事のbodyを取得していた。
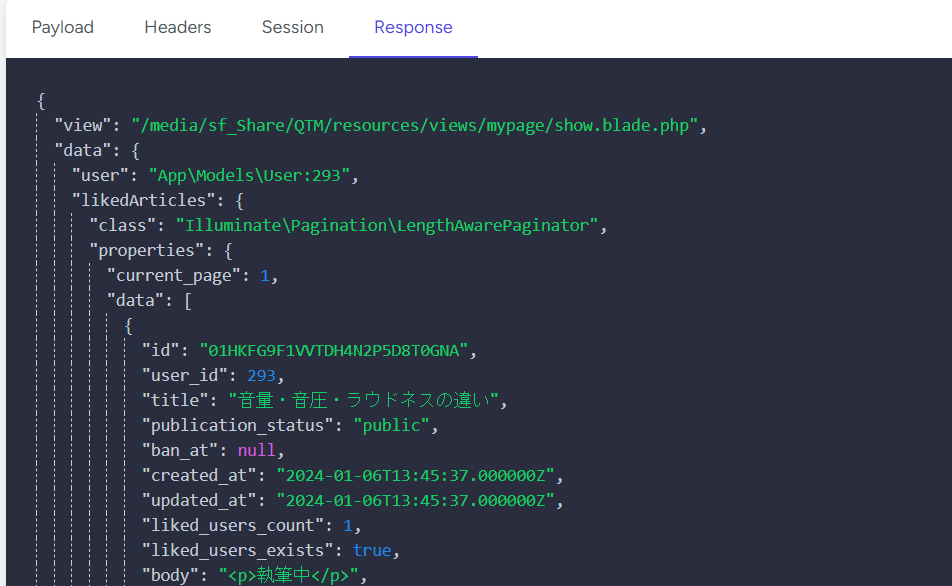
生成されたクエリを見てみると
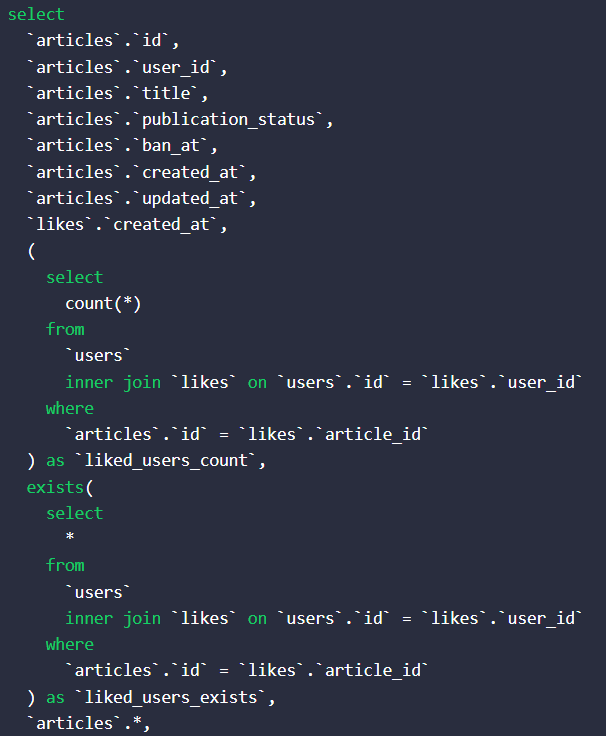
画像の一番下に「`articles`.*,」がある。
これはソースコードを見た訳じゃないので憶測ではあるんだけど、リレーションを使って取得するとき絶対全てのカラムを取得するようになっているみたい。
だから、どうしてもarticleのbodyを取得しちゃう。
難しい。
第三改善案
likedArticles()を使う方法は根本的に難しそうなので、likes()から取得する方法に切り替える。
最終的に以下のようなコードになった。
$likedArticles = $user->likes()
->whereHas("article", function ($query) {
$query->publicAndNotBanned();
})
->with([
'article' => function ($query) {
$query->with(['tags', 'user'])
->bodyExclude()
->withCount('likedUsers')
->withExists('likedUsers');
}
])
->orderBy("id", "desc")
->paginate(config("const.pagination.perPage"));with内で上記のようにすれば、Articleに対するクエリになるのでそこでwithとか色々やる作戦。
注意点は、whereHasで「先に取得するLikeとArticleの条件」を付けておかないと、条件に合わないものもnullとして取得しちゃう。
つまり、
$likedArticles = $user->likes()
->with([
'article' => function ($query) {
$query->with(['tags', 'user'])
->publicAndNotBanned()
->bodyExclude()
->withCount('likedUsers')
->withExists('likedUsers');
}
])
->orderBy("id", "desc")
->paginate(config("const.pagination.perPage"));とすると、ユーザーがいいねした全てのデータから記事を取得し、その上でpublicAndNotBanned()に合わないものは記事をnullとして取得しちゃう。
予測していないnullはエラーに繋がるし、無駄な取得が増えるので避けたいところ。
詳しくはこちらを。
一応これで、重複クエリは無しで不必要なbodyを取得しないようになった。

参考元のサイトには、「whereHasでなくwhereInで取得する方がExist句を発行しないので良い」とあるんだけど、理解が追いつかないのでとりあえずここまでに留めておく。
結論
今のところ私が出せる最善策は
$likedArticles = $user->likes()
->whereHas("article", function ($query) {
$query->publicAndNotBanned();
})
->with([
'article' => function ($query) {
$query->bodyExclude()
->with(['tags', 'user'])
->withCount('likedUsers')
->withExists('likedUsers');
}
])みたいに、withとwhereHasを駆使してデータを取得する方法っぽい。
withで取得するテーブルのクエリに更に条件を付けれるのは知らなかったので、良い収穫になった。
SEO対策
SEO対策の今のところの結論
この文章はある程度後の部分を書いてから書いている。
- 知識が無い私が色々考慮するとキリが無い
- なので、とりあえずtitle,noindex,nofollowらへんだけ付けちゃって、後から徐々に改善が良さそう
SEOをGoogle公式ドキュメントで学ぶ
Webサイトを運営する上でSEO対策は必須。
ネットの不確かな情報で悩んでも仕方がないので、Googleの公式ドキュメントを参考にSEOを学ぶ。
SEOで1番大事な事
ユーザーに質の高いコンテンツを提供しているか?に記されている通り、SEOで最も優先すべきことはユーザーに質の高いコンテンツを提供すること。だから、変にSEO対策するよりはユーザーにいい記事とかを作ってもらう仕組みを頑張った方がいいかもしれない。
私がやれそうなこと
公式ドキュメントを見た感じ、私がやれそうなのは以下の通り。
- ページタイトルと見出しを適切につけてあげる事
- 誤字脱字チェックを自動化すること
- 引用元を簡単に付けれるようにする(記事の質を上げる)
- 誰が著者なのかを明示的にする
- 画像ファイルの名前を分かりやすくする
- 画像ファイルは一般的な拡張子だけを採用(JPEG、GIF、PNG、BMP、WebP )
- 検索結果に表示しなくていいページにnoindexを
- 信頼できないリンクにnofollowを
SEOのGoogleドキュメントは30分もあれば読めるのでおすすめ。
Zennを立ち上げた人の記事を参考に、SEO対策を最低限やる
Zennを立ち上げたcatnoseさんという方がいるんだけど、この方が「ユーザー投稿型サイトのSEO対策」という私の需要にドハマりする記事を執筆されていた。
そんな素敵な記事を参考にしつつ最低限、基本的な所をSEO対策をやっていく。
やったことは以下の通り
- headタグに入るものを軽く学ぶ
- レイアウト(テンプレート)を整える
- titleを動的に変える
- カスタム404を作る
- 必要のないページにはnoindexを付ける
- 重複するページは纏める
- ユーザーが張るURLにnofollow,noopener,noreferrerを付ける
headタグに入るものを軽く学ぶ
私は一応WordPressを使って個人ブログをやってるけど、SEO対策とかが普通に面倒だったのでmetaタグとかそこらへんをよく知らない。
mdnの「ヘッド部には何が入る? HTML のメタデータ」によると、headタグに入るのは直接ページにはレンダリングされない情報らしい。
言われてみればtitleや<meta charset=”utf-8″>などのレンダリングされない情報が入っている。HTMLの内部情報という認識でいいのか。
QiitaとかZennのheadタグ内を見ると、headタグ内だけで数百行とある。
しかし、いろいろ調べて見た感じ普遍的に大事なのは以下の通り。
- <meta charset=”utf-8″>
- 入れないと文字化けする可能性あり。
- クローラーも正常に読み取ってくれなくなる可能性がある。
- <meta name=”description” content=”内容”>
- SEOの評価対象では無いが、Google等の検索結果の概要文になる。
- Zennでは、個人が一々概要を書くのは難しいので記事閲覧ページには付けていないらしい。
- Qiitaでは記事本文の最初の数文字を拾ってるっぽい。
- 長すぎると良くない。
- <title>タイトル</title>
- Googleの検索結果やブックマークなど、多用される情報。
- SEOに直接影響してくる。
- Zennの記事閲覧ページでは、記事のタイトルをそのまま<title>にしている。
- Qiitaでは、「<title>記事のタイトル #一番最初のタグ – Qiita」のような形になっている。
- 長すぎると良くない。
- <meta name=’viewport’ content=’内容’>
- ページの表示領域を指定するタグ
- width=100とかにすると以下の画像みたいに、激狭になったりする。
- 基本「width=device-width, initial-scale=1」を付けておけば良いみたい。
width=device-widthが横幅をデバイスに合わせるというもの。
initial-scale=1が初期表示倍率を1倍にしますというもの。
とりあえずこの4つが最低限<head>内に欲しいタグ
また、状況によって欲しいのが以下のタグ
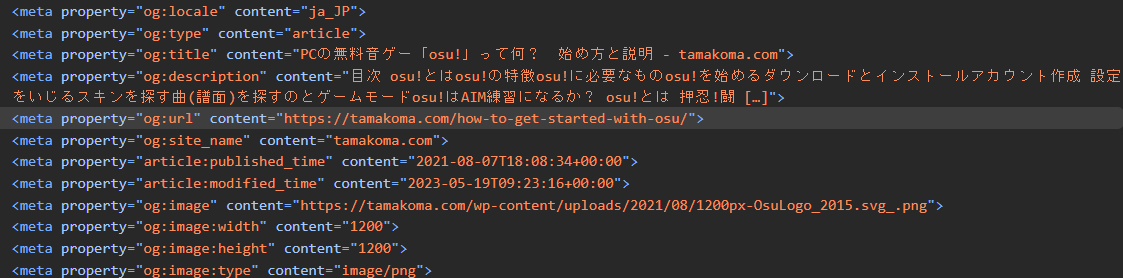
- OGPタグ
- オープングラフプロトコルの略
- <meta property=”og:title” content=”The Rock” />のように、og:がついてるのがそう
- これを付けると、FacebookやLINEなどのSNSでリンクを張った時、以下の画像のようにog:に設定した情報を参照してくれる。
- twitter:cardタグ
- X(Twitter)はOGPとは別にtwitter:cardタグがある。
- 設定方法はOGPと同じような感じで、Twitterに投稿するときの情報をここから参照してくれる。
- <meta content=”noindex” name=”robots”>
- noindexは、そのページを検索結果に出さないようにしてくれる。
- 重要でないページはnoindexを付けた方がクローラーのリソース負担を減らせるということらしい。
- 例えば、活発でないユーザーのマイページやアカウント設定ページなど。
- <meta content=”nofollow” name=”robots”>
- nofollowをheadタグ内に付けると、そのページ内の全てのリンクをクローラーが巡回しないようになる。
- noindexを付けるならnofollow。
- aタグのrelに<a href=”~” rel=”nofollow”>に付けてもよい。
- クローラーはリンクを参照(follow)することで評価の受け渡しをしているらしい。その為、信頼できないリンクがfollow出来てしまうと自身のサイトにも悪影響があるので、そういう場合にnofollowを付ける。
だいたいこんな感じではないだろうか。
レイアウトを整える
今私は初期からある<x-app-layout>みたいなコンポーネント型レイアウトと、@extendsで使う標準レイアウトの2種類が混合している。
混合してると訳わかんないし、コンポーネント型のレイアウトより@extendsみたいな普通のレイアウトの方が土台のレイアウトを作るなら使い勝手が良かったのでこちらに統一する。
titleを動的に変えてSEO対策
SEO対策とか言っちゃってるけど、titleはユーザーのレスポンスに関わるのでSEO対策云々じゃなく設定すべきだよね。
私はとりあえずレイアウトのhead部分のtitleを以下みたいにした。
<title>{{ $title ?? config(“app.name”) }}</title>
こうして、コントローラ側で$titleを渡してあげるとそのタイトルになるという寸法。
もし、何も渡さなくてもconfig(“app.name”)は’name’ => env(‘APP_NAME’, ‘Laravel’),=envに設定したAPP_NAMEになる。
カスタム404を作る
404のページがいま初期ページでかなり味気ないのでカスタムする。
SEO的にも良いらしいし。
カスタム404の作り方の日本語ドキュメントはこちら。
カスタム404とか、4xxや5xx系のエラーページをカスタムしたい時は、
php artisan vendor:publish –tag=laravel-errors
でエラーページ部分のリソースを公開する。

すると、resources/views/errosにエラーページをvendorから自動的にコピーしてくれるので、これをカスタマイズすればおk。
どうやら、テンプレートはlayout.blade.phpとminimal.blade.phpの2つがあるみたい。
ChatGPTに聞いてみた感じ、
- layoutはナビゲーションバーとかフッターとかも付けるような使い方を
- minimalはそういうのが無い単純な1ページを表示する
みたいな使い分けだそう。
エラーページもナビバーとかフッターは付いていた方がいいと思うので、layout.blade.phpをカスタムしてそれを使っていく方針にする。
とりあえず、以下みたいに作ってみた。
もし、エラーを確認したかったら以下みたいにルートに直書きでおk
Route::get('/test-error', function () {
abort(403);
});noindexとnofollowを付ける
重要度が低いものにnoindexを、ユーザーがリンクを貼れてしまうページや、無意味なリンクにnofollowを付ける。
パッと思いつくnoindexを付けるものは
- 下書きの記事ページ
- 限定公開の記事ページ
- 記事の編集ページ
- 401,403,404
とかかなぁ。
ログインが必要な画面にnoindexとnofollowを付ける意味
Zenn作者様の記事を見ると、ログインユーザー向けのページ(ダッシュボードやアカウント設定など)にnoindexを付けると記述されてる。
実際にZennのアカウント設定画面を覗くと、noindexとnofollowが付いている。

じゃあ、他のサイトはどうなのかというと、Qiita、SoundCloud、Youtubeはアカウント設定ページなどに少なくとも付いていないと思われる。
noindexとnofollowってレスポンスのヘッダーにも付けられるんだけど、そこもにも無かった。
また、google検索で「site:URL」のように検索することで、google検索にURLがインデックスされているかを見れるんだけど、noindexがついてなくても人気のないページ、またQiitaならアカウント設定ページはインデックスされてなかった。
Qiitaのアカウント設定ページがnoindex付けていないのにインデックスされていない理由が、マジでわからん。robots.txtにも無いので、何か私の知らない方法でインデックスを避けているんだと思う。ログインしてないとそもそもクローラーがクロールできないとかある?
とりあえず、noindexを以下のページに付けてみる
- 記事の編集ページ
編集ページは検索結果に出ても意味が無いので付ける。
プライベートなものだしね。
また、nofollowも付ける。意味があるのかわからないけど、ユーザーが書き込める箇所ではあるので。 - アカウント設定ページ
ログインしないと見れないページなので付ける。
恐らく付けなくてもクローラーはクロールできないんだけど、明示的にする意味で。 - 下書き一覧ページ
アカウント設定ページと同じ理由。 - 401
認証エラーのページ。アカウント設定ページと同じ理由で付ける。
今回私のサイトでは401エラーを利用していないので実際に出てくる場面は無いと思われる。 - 403
forbiddenページ。アクセス禁止になるようなページをインデックスされてもという感じ。今回認証エラーになると403になるようにしているので付ける。 - 404
存在しないページ。存在しないならnoindex付けていいよね。
逆に419,429,500,503に何故付けないかって話なんだけど、特定のページにおいてこれらのエラーが一時的な可能性が高いので付けていない。
重複するページにcanonicalを付ける
canonical(正規の)を付けて重複するページのSEO評価を一つに纏める。
私の場合、article.indexで検索ができるようになっていて
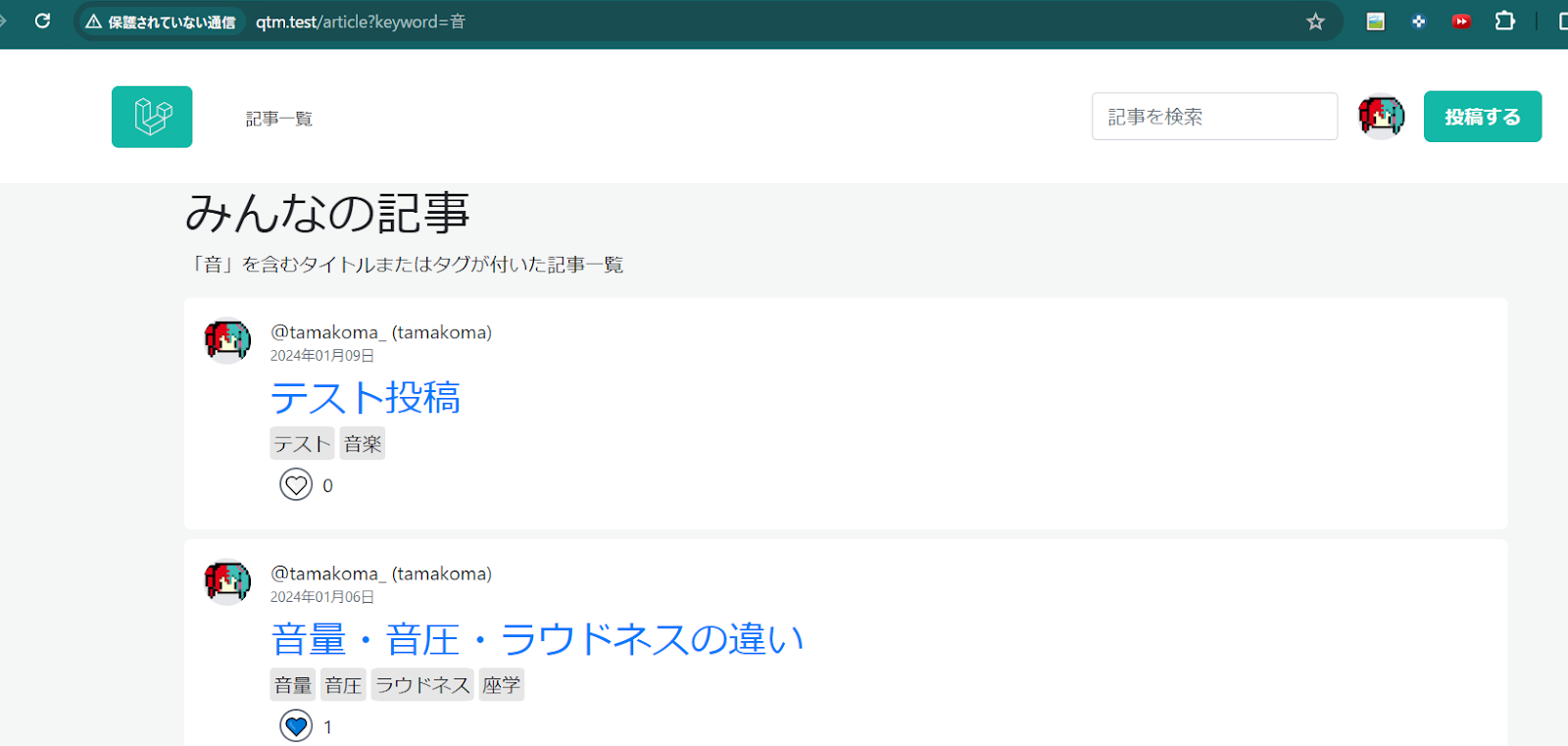
記事インデックスの「/article」と検索した際の「/article?keyword={検索ワード}」が重複するページになるのかな。
これ、QiitaとかZennを見てみると検索専用のページを設けているっぽい。
そっちの方が楽そうなので、検索専用の「article/search」を作る。
また、タグは
<link rel=”canonical” href=”{{ route(“article.search”) }}“>
みたいな感じで付ければおk。
何故検索ページにnoindex,nofollowを付けるか
Qiita、Zenn、SoundCloud、Noteの全て、検索ページにnoindexとnofollowが付いている。
この理由がわからない。
検索ページでは質が担保できないからnoindexというのは分かるんだけど、nofollowは付けても良くないか?
でも、上に挙げたページは全部nofollowが付いてるんだよね。
因みに、ニコニコ動画はnoindex,followだった。
うーん。色々考えたけど、検索ページはarticle/searchだけindex,followにして、他はnoindex,followにする。
わざわざ、indexやfollowと書くのは明示的にする為。
followは普通につけて良くないか? と思ったので付ける。
検索ページにnoindexを付けないパターン
検索ページにnoindexを付ける理由は、「検索結果ページの質を担保できない」から。
であれば、検索結果ページの質を担保出来ればnoindexを付けなくても良いのだと思う。
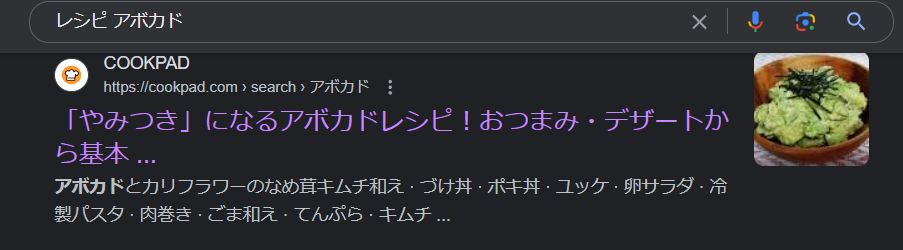
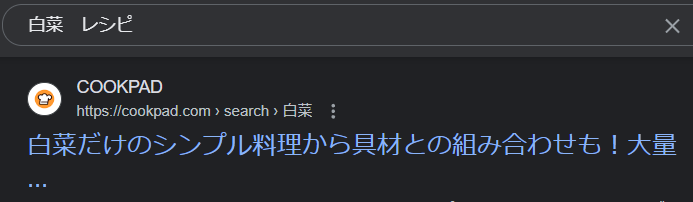
なので恐らくクックパッドではnoindexが付けられていない
証拠に、以下の画像のように「レシピ アボカド」で調べるとクックパッドの検索ページが出てくる。
また、クックパッドでは検索ボリュームが大きい検索結果には個別でタイトルを付けてるっぽい。
検索ボリュームが少ない検索ワードは以下のように「みんなの~」で始まるんだけど、
アボカドもそうだし、他の人気ワードはオーダーメイドのタイトルがついている。
では、どうやって検索ページの質を担保しているかなんだけど、検索アルゴリズムを工夫してるっぽい? 普通の部分一致で「あ」と調べると「あ」が入っているページ全てがヒットするんだけど、クックパッドでは「あ」が独立しているものだけがヒットする。
だから、恐らくなんだけどタイトルと説明の文章をある程度のブロックで分解して、その部分と一致しているかを見てるんじゃないかなぁと思う。
つまり、寧ろ検索ページをインデックスさせる戦略もある。
検索ページにnoindex,followは意味が薄いかもしれない
理由は「SEO屋は誤解していた!? noindex,followは長期的にはnoindex,nofollowと同じ。」と「重複コンテンツ対策にはrel=canonicalを推奨、noindexタグではシグナルがすべて失われる」を参照。
つまり、noindex,followを付けたページはいずれクローラーがクロールしなくなるので長期的にはnoindex,nofollowと同義になるらしい。また、重複コンテンツはnoindexを付けずにcanonicalだけを付けるのが良い……かもしれない。
で、あれば。検索ページ全部index,followで、canonicalを付けるのがいいのかなぁ。とりあえずそれでやってみて、ダメそうなら変えよう。
ペジネーションの2ページ目以降にnoindexは必要か
検索ページと同じく、考慮が必要そうだよね。
「ページネーションしたページはnoindexにすべき? rel=“prev/next”とnoindexは併用可能?」によると、ページネーションの「次」や「戻る」ボタンにnext/prevが付いていればgoogleが察して1つの評価にしてくれる。
「Google、ページネーション問題を解決するrel=“next”タグとrel=“prev”タグをサポート開始」にもある通り、ページネーションの為設定なので、信頼は出来る。
CSRFをしっかり理解したい
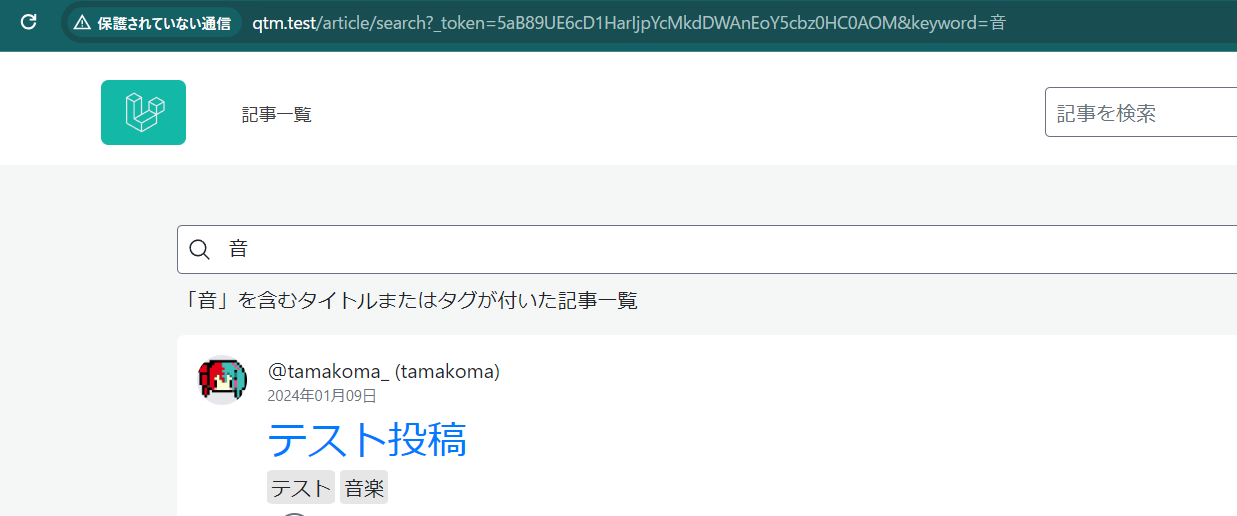
一応こんな感じで検索ページは出来た。
しかし、恐らく昔の私が検索窓のテンプレに@csrfを付けていたのでURLがスゴイことになっている。
今の私であればGETリクエストには@csrf付けなくていいっていうのは知識でだけ知ってるんだけど、そもそもCSRF攻撃とかを理解できていないので、そこら辺を理解したい。
セッションとCokkieを理解する
CSRFを理解するにはこの2つを理解する必要があると思ったのでこちらから。
Cokkie
- HTTPリクエストのヘッダーに付ける情報のこと
- Webサーバーが発行し、ブラウザがユーザーのPCに保存する
私の環境(Windows10のChrome)であれば、「C:\Users\{user_name}\AppData\Local\Google\Chrome\User Data\Default\Network」に保存されていた。 - 基本、リクエストに付けるCookie情報は、そのサーバーで発行された情報のみ。他のサーバーからの情報は送らない。
セッション
- 一意のIDに対する情報を一定期間Webサーバーで保管すること
- 一意のIDを保持するユーザーがブラウザを閉じるか、有効期限になるまで保管する
これらの使い方的には、
- ユーザーがログインする
- サーバーがログイン成功のレスポンスと同時に、一意のセッションIDを発行しブラウザに送信
- ユーザーはそれ以降Cookieに発行されたセッションIDをリクエストに付加し、ステートフルな接続をする
こんな感じになってるから、1回ログインするとセッションIDの有効期限が来るまでログイン状態が保たれるんだね。
CSRFは何をしているか
IPAの資料「安全なウェブサイトの作り方 – 1.6 CSRF」
私の理解した手順的には以下の通り
- ユーザーが正規のサイトにログインする
- ここでセッションIDが生成され、そのブラウザでは以降そのIDをCookieに付加してWebサーバーにリクエストを送るようになる。
- ユーザーがその状態で悪意のあるサイトにアクセスする
- 悪意のあるサイトで、正規サイトに対するPOSTリクエストをするようユーザーのブラウザに指示される
- ユーザーのブラウザのCookieにはセッションIDが付加されているので、正規のサイトに対するPOSTリクエストが通る
という感じ。
ここで大事なのは
- 悪意のあるサイトは、Cookieを直接見たり、セッションIDを盗んでいるわけではない
- 意図しないPOSTリクエストが通ってしまうのが悪いのであって、検索窓などのGETリクエストが通るぐらいでは恐らく被害はない
また、Laravelではどのような対策が取られているかなんだけど、「LaravelのCSRF対策の処理を実際のコードから見てみる」によると、
- フォーム生成時にWebサーバー側で暗号を生成
- アクセスしたユーザーのセッションに暗号をセット
- 生成したフォームにも暗号をセット
- フォーム送信時にユーザーのセッションの暗号と照合し、合ってたらおk
みたいな処理をしている。
なるほど、CSRFの仕組みはわかったけど、悪意のあるブラウザにアクセスするだけで任意のサイトにリクエストを送れるとしたら、DDOSとかできちゃいそうと思ったりした。
UGC(User Generated Contents)コンテンツとは
Google関連を色々見てたらGooglePlayに関する記事で、UGCコンテンツというのが出てきたので。
リンク先の物は2024/01/31に発効されるもの、また、GooglePlayのポリシーなので注意。
GooglePlayポリシーなのでWebサイトに直接関係はないんだけど、参考にすると私のWebサイトには以下がまだ足りなさそう
- ユーザー報告機能
- 記事報告機能
また、ユーザーブロック機能もあると良いね!って感じ。
aタグのrel属性を弄る
次に、一番大事と言っても過言ではないリンク対策をしていく。
そもそも、aタグのrel属性って何なの? ってところなんだけど、ページとリンク先の関係(relation)を表すもの。MDN曰く、結構ある。
nofollowを付ける
Googleのドキュメントの「リンク先に注意する」にある通り、リンクはリンク先に自分のページの評価を渡すことに繋がる。
つまり、ユーザー投稿型サイトの場合ほっとくと評価が欲しいスパムだらけになるみたい。
また、それ以外にも有料リンクを張られるとサイトの評価が下がったり、「リンク先と同じジャンルのサイト」と評価されちゃったりするらしい。なので、ユーザーが投稿できるaタグにはnofollowを付ける。
nofollowとは、クローラーに「このリンクはクロール(評価)しないでね!」とヒントを与えるもの。
nofollowは命令ではない
私は完全に認識間違いを起こしていたんだけど、nofollowは命令ではない。
「進化する nofollow – リンクの性質を識別する新しい方法」にもある通り、nofollowはヒントとして扱われ、場合によりクロール・評価をするみたい。
ugc属性もあるよ
前述のリンクは2019年のGoogleブログなんだけど、その時にugc属性とsponsored属性というのが追加された。
今のところはnofollowと違いは無く、主にGoogleが運用している属性なんだけど私のサイトはどう考えてもUGC(User Generated Contents)なので、使っていこうと思う。
Google以外のクローラーのことも考えて、「nofollow,ugc」みたいな感じで使う。
新規登録・ログインボタンにnofollowを付ける
様々なWebページを見てると、新規登録・ログインボタンにnofollowが付いていることに気づいた。
理由は定かではないのだけど、恐らく以下の意味がある
- ナビバーとかで頻繁に出る割には、価値が薄い
- nofollowを付けても、他のリンクから辿れるから問題ない
- そこまでインデックスしてほしいわけではない
とりあえず、どのサイト見ても新規登録とログインページリンクにnofollowが付いているので、真似する。ダメだったら外せば良い。
ユーザーが張れるリンクにnofollowとugcを付ける
やることとしては、DBからHTMLを取り出すときにaタグがあればそこのrel属性にnofollowとugcを付ければおk。
どうやってやるの? ってところなんだけど、PHPにはDOMを弄る機能があるらしいので、それで頑張ってみる。
DOMDocumentとの闘い
闘いに超絶貢献してくれた参考文献
- PHP の DOMDocument にまつわる 警告 や 文字化け や 数値文字参照 の話
- PHPでDOMを使ってHTMLをロードしてセーブするのが何気に難しかった件
- DOMDocument::loadHTML(): Tag article invalid in Entity #1
- How to saveHTML of DOMDocument without HTML wrapper?
PHPにはDOM操作ができるDOMDocumentというクラスがある。
これ使えばめっちゃ簡単に弄れるじゃん! と2日前まで思っていた。
DOMDocumentにはかなりの数の落とし穴がある。
一応、簡単に考えられる落とし穴を回避した私のコードは以下の通り。
public function addNoFollow($html) {
$dom = new \DOMDocument();
// HTMLを読み込む
$dom->loadHTML('<?xml encoding="UTF-8"><section>' . $html . '</section>', LIBXML_NOERROR | LIBXML_HTML_NOIMPLIED);
// すべてのaタグを取得
$links = $dom->getElementsByTagName('a');
foreach ($links as $link) {
// 既存のrel属性を保持しながらnofollowとugcを追加
$rel = $link->getAttribute('rel');
if (!empty($rel)) {
$rel .= ' ';
}
$rel .= 'nofollow ugc';
$link->setAttribute('rel', $rel);
}
// 変更後のHTMLを取得
$newHtml = $dom->saveHTML($dom->documentElement);
return $newHtml;
}注意点として、私が加工する$htmlは完全なHTMLではなく、<html>や<body>タグのない一部分のHTML。そのため、完全なHTMLを加工する場合は違うアプローチになるかもしれない。
このコードで大事なのはHTMLを読み込む部分と、加工後のHTMLを取得する部分。
全部理解していく。
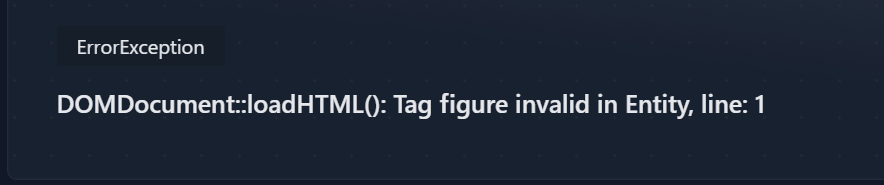
loadHTMLはHTML5を想定していない
そもそも、このDOMDocumentはHTML5を想定していないらしく、HTML読み込み時にHTML5のタグがあると「HTMLの文法がおかしいですよ」とエラーを大量に吐く。
だから、このエラーをどうにかしたいんだけど、こちらのissueを参考にして解決した。
今回はこのエラー回避に「LIBXML_NOERROR」を使っている。
これはlibxmlで定義されている定数で、libxmlで発生するエラーを非表示にするというもの。
loadHTMLの第二引数(option)に渡せばおk。
また、
@$dom->loadHTML(‘<?xml encoding=”UTF-8″>’ . $html);
のように、@を付けることで重大でないエラー以外をスルーする方法もあるんだけど、これだとその行(式)のほぼ全てのエラーを非表示にしてしまうのであまり良くないみたい。
エンコードの調整
次に
‘<?xml encoding=”UTF-8″>’ . $html
これは、DOMDocumentに「UTF-8でエンコードしてますよ」と教えてあげている。
これを付けないと
<p>執筆中</p>
が
<p>執ç†ä¸</p>
みたいな感じで、文字化けする。
これは、DOMDocumentがISO-8859-1という文字コードとして文字をエンコードするから。
じゃあ、どうやってUTF-8であることを知らせるかなんだけど、DOMDocumentはHTMLではなく、XMLとして引数を処理している。
その為、文頭に「<?xml encoding=”UTF-8″>」を付けてあげることでHTMLをXMLとして処理させ、かつUTF-8で書いているということを知らせている。
加工後のHTMLを取得する
該当する部分は
$newHtml = $dom->saveHTML($dom->documentElement);
の一行。
これ、saveHTML()のみで取得すると日本語を数値文字参照として出力してしまい、
<p>執筆中</p>
が
<p>執筆中</p>
のようにまた文字化ける。
しかし、
saveHTML($dom->documentElement)
のようにすることで、何故かUTF-8で出力してくれる。
ドキュメントとかに理由は書いていないので、理由はソースコードを読まないとわからない。
また、「$dom->documentElement」で取得することで、不要な<!DOCTYPE>を取得しなくなるので、良い。
逆に欲しい人は違う方法じゃないとダメかも。
自動的に<html>と<body>が付くのを拒否
$dom->loadHTML(‘<?xml encoding=”UTF-8″>’ . $html, LIBXML_NOERROR | LIBXML_HTML_NOIMPLIED);
のように、LIBXML_HTML_NOIMPLIEDをオプションに付けてあげると、自動で<html>と<body>が付くのを拒否できる。
具体的には、
<html><body><p>執筆中</p><p>おもち</p></body></html>
が
<p>執筆中</p>
になる……
<body>と<html>タグも消えたけど、なぜか「<p>おもち</p>」も消えた。
ルートタグを付ける
どうやら、LIBXMLを使う時はルートタグが必要みたい。
つまり、
<p>執筆中</p>
<p>おもち</p>
のようなHTMLの場合、一番最初にある執筆中についている<p>タグがルートタグとなり、そのルートタグの終わりまでを処理する。
そのため、「<p>執筆中</p>」だけが出力されていたという訳。
だから、
<div>
<p>執筆中</p>
<p>おもち</p>
</div>
みたいに、1番最初の行から1番最後の行までを囲むタグを追加してあげればいい。
今回、私はこのようにsectionタグを付けた。
$dom->loadHTML(‘<?xml encoding=”UTF-8″><section>’ . $html . ‘</section>’, LIBXML_NOERROR | LIBXML_HTML_NOIMPLIED);
もしダメそうなら後で変更する。
そんな感じで、全てのaタグのrel属性にnofollowとugcを付けることに成功した。

しかし、HTMLがしっかり処理されるかかなり不安ではあるので、色んなパターンのテストをしておくとよいと思う。
ユーザーが張れるリンクは別タブで開くようにする
記事内のリンクは別タブで開かないと不便だし、離脱に繋がるので別タブで開くようにする。
方法はさっきのコードを以下のように改変する
public function addNoFollow($html) {
$dom = new \DOMDocument();
// HTMLを読み込む
$dom->loadHTML('<?xml encoding="UTF-8"><section>' . $html . '</section>', LIBXML_NOERROR | LIBXML_HTML_NOIMPLIED);
// すべてのaタグを取得
$links = $dom->getElementsByTagName('a');
foreach ($links as $link) {
// 既存のrel属性を保持しながらnofollowを追加
$rel = $link->getAttribute('rel');
if (!empty($rel)) {
$rel .= ' ';
}
$link->setAttribute("target", "_blank");
$rel .= 'nofollow ugc noopener noreferrer';
$link->setAttribute('rel', $rel);
}
// 変更後のHTMLを取得
$newHtml = $dom->saveHTML($dom->documentElement);
return $newHtml;
}
target属性の_blankは、新しい無題のタブを開き、そこに表示するという意味。
rel属性のnoopnerはリンクを開いた時にWindow.openerから情報を取られないようにするもの。
noreferrerはリファラーヘッダという、どこからアクセスしてきたかの情報を載せないようにするもの。184みたいな。
また、古いIEとかはnoopnerに対応しておらず、noreferrerがnoopnerのような役割をするみたい。
DOMDocumentの処理速度
一応、DOMDocumentを使ってaタグに任意の属性を付けれるようになったんだけど、DOMDocumentの処理速度がわからないのでちょっと計ってみようと思う。
同じURLを3073行分、つまりURLを3000個強を処理させてみる。

処理速度的には以下みたいな感じ。
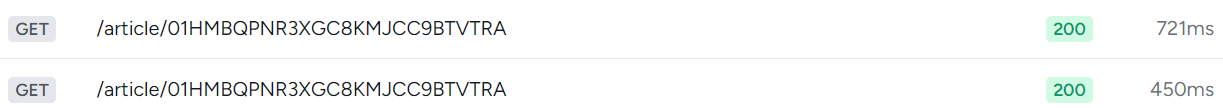
上がaタグの処理ありで、下が処理なし。
まあ、早くはないけど思ったよりは遅くない、支障はないくらい。
そもそも、3000個もURLを載せるとCKEditorが重くなっていたので、実用面でのボトルネックはCKEditorになりそう。
ユーザー・記事の報告機能を作ろうとする
2024年1月31日から発効されるGooglePlayのUGC(ユーザー生成コンテンツ)ポリシーによると、以下のように記述されている。
SNS アプリや Blogger アプリなど、一般公開されている UGC にアクセスできるアプリは、ユーザーやコンテンツについて報告し、ユーザーをブロックするアプリ内機能を実装しなければなりません。
https://support.google.com/googleplay/android-developer/answer/13998184
ユーザー生成コンテンツを含むアプリでは、知的財産の侵害や匿名の嫌がらせなど、特定の問題が生じることがあります。悪用を防ぐため、ユーザー生成コンテンツやソーシャルネットワーキングサービスを含むアプリは以下を備えている必要があります。
https://developer.apple.com/jp/app-store/review/guidelines/#user-generated-content
- 不適切な内容がアプリに投稿されることを防ぐ手段
- ユーザーが不適切なコンテンツを報告し、それに対して迅速に対応することができる仕組み
- 不適切な言動を行うユーザーをブロックする機能
- ユーザーがすみやかに連絡できる、デベロッパの連絡先情報
とある。
つまり、どちらもユーザーとコンテンツの報告機能かつブロック機能が必須ということ。
別にスマホアプリにするつもりは無いんだけど、実装はした方が良いよね。
この”ブロック”は、ユーザーがユーザーをブロックすることではなく、運営がユーザーをブロック(BAN)するという意味みたい。だから、X(Twitter)からブロック機能を無くすことは可能。
記事とユーザーのBAN機能は既にあるので、報告機能を作れば良いという感じ。
実装を考える
見た目はよくある感じで、コンテンツやユーザーの近くにある「…」から報告ボタンを押せるようにすれば良いとは思う。
でも、実装がちょっと悩ましいところではある。
他のサイトを見た感じ
- Qiita:ログインしなくても報告可
- Zenn:報告にはログイン必須
- Note:報告にはログイン必須
となっていて、Qiitaはログインしなくても記事・ユーザー共に報告可能だった。
ログインしなくても報告可能の方がユーザー的に簡単なので、嬉しいんだけどスパム対策とかが面倒そう。
管理画面は必要か
一番最初、laravel-adminという管理画面を簡単に作れるパッケージを入れていたんだけど、もう更新が来ていないことと、Githubのアラートボットからアラートが来たことを理由にアンインストールしたんだよね。
ユーザーからの報告を管理画面で管理できると、かなり管理が楽になると思うんだけど以下の要素で億劫になっている
- 今から管理画面を探し追加すること
- 管理画面をユーザーからの報告を受け取れるようにさらに改修すること
- 不正アクセス対策もする必要があること
laravel-adminを使う選択肢は無いのか?
改めて見直すと、laravel-adminには2023年3月にCVSS7.2とかなり高めの脆弱性が発見されている。
詳しくは「laravel-admin has Arbitrary File Upload vulnerability」を参照。
なんか、任意のファイルをアップロードできるという脆弱性を使い、好きなPHPを実行できてしまうらしい。
だいぶまずい脆弱性だし、ホームページ・GitHub共に更新が来てないのでlaravel-adminは流石に無しかなぁ。
なんなら、ホームページは繋がらなくなっているので、よほどのことが無い限り無しなのでは。
他の管理ライブラリ
一応、laravel-admin以外にどんな管理画面キットがあるのか調べてみる
- Laravel Nova
- Laravelの開発チームが開発している
- Vueを利用しているっぽい
- 有料
- 年サブスク79$+初回費用99$で、初年178$
- お金の面に目をつぶれば信頼できるのでこれを使いたい
- Backpack for Laravel
- BootstrapとjQueryという最低限の技術スタック
- 無料版・有料版がある
- 日本語にも対応してるっぽい
- Filament
- TALL環境を採用
- Tailwind
- Alpine.js
- Laravel
- Livewire
- 基本無料で、プラグインなどでお金を取ってる?
- 日本語対応してる
- TALL環境を採用
- Voyager
- Vueを利用
- 無料
- 簡単な利用に向いてそう
- 更新があまり来ていない?
- ドキュメントが1年前
- Laravel9までにしか対応してない
- GitHubの更新が2023年11月と更新頻度が低い?
- 日本語情報少ない
- Laravel AdminLTE
- AdminLTEをLaravel特化にしたもの
- Bootstrapを利用
- 日本語対応
- 無料
本当に色々あるねこれ。
ちょっと面白そうなので管理画面の実装もしたいなぁ。
無料のものだとVueを使わないFilamentかBackpackかなぁという感じ。
恐らく、管理画面も作り始めると学習コスト+時間コストがえぐいのよね。
でも、ゆっくりでも確実に進めていくべきだと思うし、後々役に立ちそうなので管理画面の実装を頑張ってみる。
Filamentで管理画面を実装しようとして、諦める
ユーザーからの報告管理とか記事管理をする上で、管理画面があった方がいいなと思ったので、管理画面を実装する。できなかった。
Laravel9→Laravel10にする
これは、Filamentの最新版FIlament3を利用する為。
FIlament3ではLivewire3が使われているから、Laravel10が必須だそうで。
どちらにしろどこかのタイミングでLaravel10にしようと思っていたので、ここで10にする。
9→10へのアップグレード日本語ドキュメントはこちら。
まず、今の環境でテストが全部通るか確認する。
Composerが2.20以上、PHPが8.1.0以上必要
Composerが2.20以上、PHPが8.1.0以上必要なので、確認する。

Composerの依存パッケージを変更する
composer.jsonの依存パッケージを変更する
- laravel/frameworkを^10.0
- laravel/sanctumを^3.2(2.xから3.xにする場合はアップグレードガイドを)
- doctrine/dbalを^3.0
- spatie/laravel-ignitionを^2.0
- laravel/passportを^11.0(アップグレードガイド)
に変更する。
私の場合、「laravel/framework, laravel/sanctum, spatie/laravel-ignition」の3つが該当してた。
PHPUnit10を利用したい場合
PHPUnit10にするとテストが早いらしいので、設定する。
まず、phpunit.xmlの<coverage>にあるprocessUncoveredFiles=”true”を削除する。
次に、composer.jsonを更新する
- nunomaduro/collisionを^7.0
- phpunit/phpunitを^10.0
最低安定度
composer.jsonの”minimum-stability”をstableにする。
“minimum-stability”: “stable”,
私の場合はなってた。
アップグレード
私の場合はこの変更で問題なさそうだけど、ドキュメントを見て自分の影響する部分を更に更新する。
最後に
composer update
でアップグレード
無事アップグレードできたみたい。
テストスピードはなんならちょっと遅くなった?
Livewire3をインストールする
Livewire3をインストールする。
※最終的にアンインストールした。
composer require livewire/livewire
を実行すれば良い
Alpine.jsの重複と闘い、逃走する
ここでまさかの致命的な仕様が。
このLivewire3、既にBreezeなどでAlpine.jsが入っていると2回Alpine.jsをロードしてしまいバグるみたい。
私は、BreezeでAlpine.jsが入っていたので、「resources/js/app.js」内のAlpineの実行とLivewireの実行が被ってしまいバグる。
じゃあ、「resources/js/app.js」内のAlpineの実行を止めればいいんじゃない? って思うんだけど、Livewire内のAlpineは常にロードされるわけではなく「Livewireの中にAlpineが内包されており、Livewireを使うページでのみAlpineが読み込まれる」という仕様になっている為、Livewireが使われていないviewでは@livewireScriptsでAlpineを呼び出す必要がある。
つまり、現在Alpineを利用しているViewを全て探し出し、@livewireScriptsを付けなきゃいけないということ。
めっっちゃ面倒!!!
しかも、これ@livewireScriptsがview内に二個あるとそれはそれでバグる。
これのなにが面倒かというと、コンポーネントの中に@livewireScriptsを入れると、そのコンポーネントが2個あった時@livewireScriptsの重複を起こす。
マジでどうするべきかこれ。
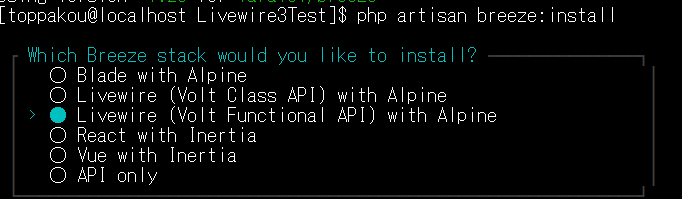
どうやらBreezeにはLivewire用のインストール選択肢もあるみたいなので、新しいLaravelプロジェクトを立ち上げてそっちで試してみる。
Breezeインストール時に以下のように聞かれるので、Livewireのどちらかを選ぶ。
うーん。だいぶ変わるなぁこれ。
一部分しか変わらないならその部分だけ持ってこようかと思ったんだけど、そうでもなさそう。
ここで私の取れる選択肢は
- FIlamentを使う為に
- Laravelプロジェクトを1から作り直し、Breezeを入れなおす
- 1日以上かかりそう
- レイアウトに「@livewireScripts」を付けちゃう
- その場しのぎにしかならないので、後の負債になりそう
- Laravelプロジェクトを1から作り直し、Breezeを入れなおす
- FIlamentを使わない
- Backpackを使う
- Laravel AdminLTEを使う
- 管理画面をそもそも実装しない
ちょっとFilamentは諦めて、Laravel AdminLTEを使う方針に方向転換する。
Livewire3をアンインストールする
既にBreezeが入っているプロジェクトにLivewire3を追加するのはちょっと厳しいことがわかったので、Laravel AdminLTE使う方針に切り変える。
その為、Livewire3をアンインストールする。
composer remove livewire/livewire
でアンインストール。
gitのコミットを遡ってもいいんだけど、vendorに残っちゃうのが少し気になるのでこちらでアンインストールした。
結果、Laravelを10にアップグレードしただけだった。
Laravel-AdminLTEで管理画面を実装する
Laravel-AdminLTEを使う理由は
- 使用技術がBootstrapだけなので依存関係が弱いこと
- 現在も更新が来ていること
- Wikiがしっかりしてそうなこと
とりあえずインストール
とりあえずWikiに従ってインストールする。
composer require jeroennoten/laravel-adminlte
でパッケージを入れて、
php artisan adminlte:install
でインストールする。
インストールされるのは、以下のように主にconfig、言語フォルダ、vendorの3つ。
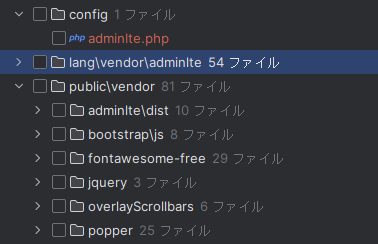
これ見た感じ、Bootstrap以外にもjQueryも使ってるんだね。
コマンド一覧を見ると「php artisan adminlte:status」でインストール状況を見れるみたい。
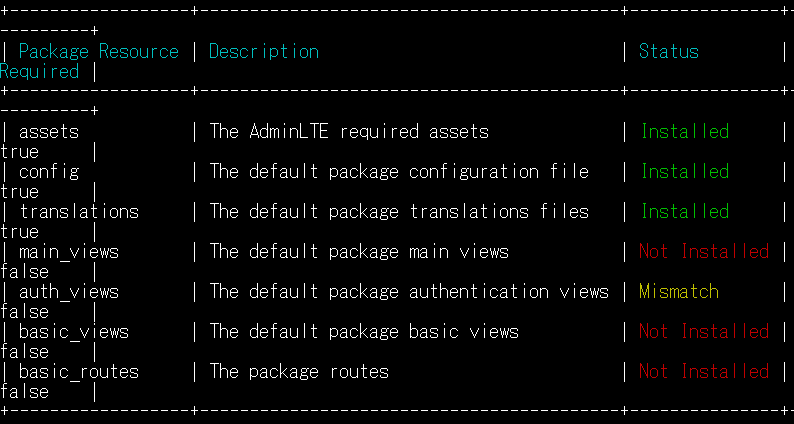
auth_viewの部分は、私は既にBreezeでauth_viewがあるのでMismatchになってる。
使い方
AdminLTEはよくも悪くも「管理画面のView」を実装しやすくしてくれるものみたい。
なので、AdminLTEを使い管理画面を自作する場合は、「Usage」にある通り、
@extends('adminlte::page')
@section('title', 'Dashboard')
@section('content_header')
<h1>Dashboard</h1>
@stop
@section('content')
<p>Welcome to this beautiful admin panel.</p>
@stop
@section('css')
<link rel="stylesheet" href="/css/admin_custom.css">
@stop
@section('js')
<script> console.log('Hi!'); </script>
@stopのようなコードを打ち自作していく。
ちなみに、このviewを表示してみると

こんな感じで、簡単な管理画面が表示される。
リンク先はまだ何も実装してないので、全部404。
テンプレートを使う
といっても、一から構成していくのも面倒なので既にあるテンプレートを覗いてみる。
php artisan adminlte:install –only=basic_views –only=basic_routes –only=main_views
でインストールする。
- basic_view
これが「テンプレートの使用方法の参考として使用できる非常に基本的なビュー」とのこと。
「resources/views/home.blade.php」に保存される。 - basic_routes
これは「基本的なホーム ビューのルート定義」とのこと。
「routes/web.php」に挿入される。 - main_views
こちらはテンプレートのレイアウトの中身を弄る時に、公開するときに使う。
「resources/views/vendor/adminlte/」に公開される。
テンプレートにnofollowとnoindexは付けるべきだよね。
basic_viewで実装されるのが
@extends('adminlte::page')
@section('title', 'AdminLTE')
@section('content_header')
<h1 class="m-0 text-dark">Dashboard</h1>
@stop
@section('content')
<div class="row">
<div class="col-12">
<div class="card">
<div class="card-body">
<p class="mb-0">You are logged in!</p>
</div>
</div>
</div>
</div>
@stop
で、
basic_routesで実装されるのが
Auth::routes(); // laravel/uiの認証ルーティングを全て実装する一行
Route::get('/home', function() {
return view('home');
})->name('home')->middleware('auth');こんな感じ。
今の状態だと”auth”のミドルウェアが付いているだけなので、ユーザーであれば誰でもアクセス可能になっている。
これだと良くないので、恐らく管理者ユーザーを作ってその人だけがログインできるようにすればいいのかな。
管理者アカウントの管理
結構悩むのが、管理者アカウントの管理について。
単純な方法だとusersテーブルにisAdminやroleカラムを付ければよくて、複雑な方法は管理者用のテーブルを作る方法。
- usesテーブルにロールを追加する場合
- マスアサインメント等の怖さ
- なんらかの攻撃でユーザーのロールが変えられてしまう可能性
- 一般ユーザーがadmin関連のコントローラを経由するのがもう怖い
- 総括して、ユーザーと管理者を一緒に管理するの怖すぎる
- 管理者用のテーブル作成の場合
- 認証管理や学ぶこと、やることが多い
- やることが多いだけ、セキュリティホールができちゃうのが怖い
色々調べて見ると、どうやらLaravelの認証機能の助けを借りればある程度楽に作れるみたいなので、管理者用のテーブルを作成する方針に。
認証を学び管理画面の準備
学ぶ前に、私が混乱したことを。
学ぶ際にややこしいこと
認証関連で調べると「AuthenticatesUsers.php」の話が出てくることがある。しかし、Breeze認証に「AuthenticatesUsers.php」は存在しない。
これは、Laravel7まではLaravel/uiを使った認証が主流で、Laravel/uiには「AuthenticatesUsers.php」があったのでそれを踏まえた説明が多いという感じ。
しかし、Laravel8からBreezeとJetstreamを使った認識が実装され、そちらが主流になったという過程がある。
その上で、少なくともLaravel10のBreezeには「AuthenticatesUsers.php」が無いので「言ってることが違うなぁ」と混乱したという感じ。
その為、BreezeならBreezeの認証を学ぶ必要があるし、とりあえず必要な部分だけ学ぶのが良いと思う。
実装
実装といっても、ここで無責任に変な情報を残すと怖いので、学ぶのに使った参考資料を残す。
- 日本語ドキュメント : 認証
- 本 : PHPフレームワークLaravel Webアプリケーション開発
- 個人ブログ : 【Laravel】 Breezeの認証周りを完全に理解する
- 個人ブログ : Laravelのマルチログインを図解しながら実装
実装内容はセキュリティに関わるので、更に参考にした参考元を
主に上の2つを参考に実装し、更に色々自分なりに実装した。
可能なら汎用的な内容をまとめて残したいけど、どこを伝えてよくてどこを伝えちゃダメか、そもそもこの実装で問題無いかが曖昧なので今はやめておく。
結果何日かかけて実装した。
管理画面を作る
目的を忘れかけていたが、AdiminLTEを入れたのはユーザーからの報告を管理する為なので、その部分だけでも作る。
とりあえず、報告は運営からのレスポンスの無い、一方通行システムで問題ないと思うので以下のようにする
- ユーザーはユーザーと記事を報告できる
- 報告したらDBに保存
- その一覧を管理画面から見れる
最初はユーザーに対する報告と記事に対する報告を別にしようかと思ったんだけど、どうやらNoteもQiitaも共通の報告システムにしているっぽい?
ポリモーフィックリレーションを理解する
ポリモーフィックリレーションの日本語ドキュメント
憶測でしかないんだけど、QiitaもNoteもポリモーフィックリレーションで通報システムを1つに纏めていると思われる。
この、ポリモーフィック(polymorphic)は多型という意味で、つまり一つのリレーションで複数のモデルに属することを表している。
今回の場合、reportsテーブルはusersテーブルとarticlesテーブルという複数のモデルに対し属したい。
その場合、具体的にはreportsテーブルを以下のように定義する
- reports
- id – integer
- reason – string
- reportable_id – integer
- reportable_type – string
reasonは報告理由をユーザーに書いてもらうところ。
大事なのはreportable_idとreportable_typeで、それぞれ
reportable_idはreportsが属すモデルのIDを示し、
reportable_typeはどのモデルに属するかのモデル名を示す。
つまり、記事に対する報告なら、reportable_idに対象のarticle_idを保存し、reportable_typeにモデル名であるArticleが入る。
ポリモーフィックリレーションにも一対一、一対多、多対多があるが概念は普通のリレーションと同じ。
reportsテーブルであれば、一つの通報が一つの記事・ユーザーに紐づき、記事・ユーザーが複数の通報に紐づくので、一対多のリレーションになる。
ポリモーフィックリレーションは、1つのカラムに複数のモデルのIDを入れるので、モデルの型は一致している必要があるみたい。
ポリモーフィックリレーションでモデルの型が一致していない場合
私の作ろうとしている報告機能は、ユーザーと記事に対して報告できるようにしたいと考えている。
しかし、ユーザーIDはBIGINTなのに対し、記事IDはULIDなので型が一致しておらずreportable_idに両方のモデルのIDを入れるということができない。
IDを統一してしまえば終いなんだけど、かなり面倒なのでポリモーフィックリレーションを諦めて、reportsテーブルにそれぞれuser_idとarticle_idを追加し、個別に一対多の関係を持たせることにする。
少しゴリ押し感はあるけど、関係を追加したければその関係を増やしたいIDを増やすだけなので意外と問題は無さそう。
ポリモーフィックリレーションを諦め、ユーザー、記事の通報を纏める
reportsテーブルはとりあえず以下のようにしてみる
- reports
- id()
- unsignedBigInteger(‘reporter_id’)
- 報告者のユーザーID
- foreignId(‘user_id’)->nullable()->constrained()
- 被報告者のユーザーID
- foreignUlid(‘article_id’)->nullable()->constrained()
- 被報告記事の記事ID
- text(‘details’)->nullable()
- 報告理由(任意)
- enum(‘category’, [‘spam’, ‘guideline’, ‘copyright’])
- スパム、ガイドライン違反、著作権違反で分ける
- text(‘admin_comment’)->nullable()
- 管理者が管理する為に残すコメント
- dataTime(‘processed_at’)->nullable()
- 2038年問題的にdataTimeを使う
- 報告を処理した場合日付を入れ、処理済みと判断
- dateTime(‘created_at’)->nullable()
- dateTime(‘updated_at’)->nullable()
これならreportsテーブルにカラムを増やすことで新たな通報対象を追加できるので、悪くは無いかなという感じ。
とりあえず簡単に、コントローラ、ポリシー、リクエスト、ビュー、ルートを作りユーザーと記事に対し報告できるように。
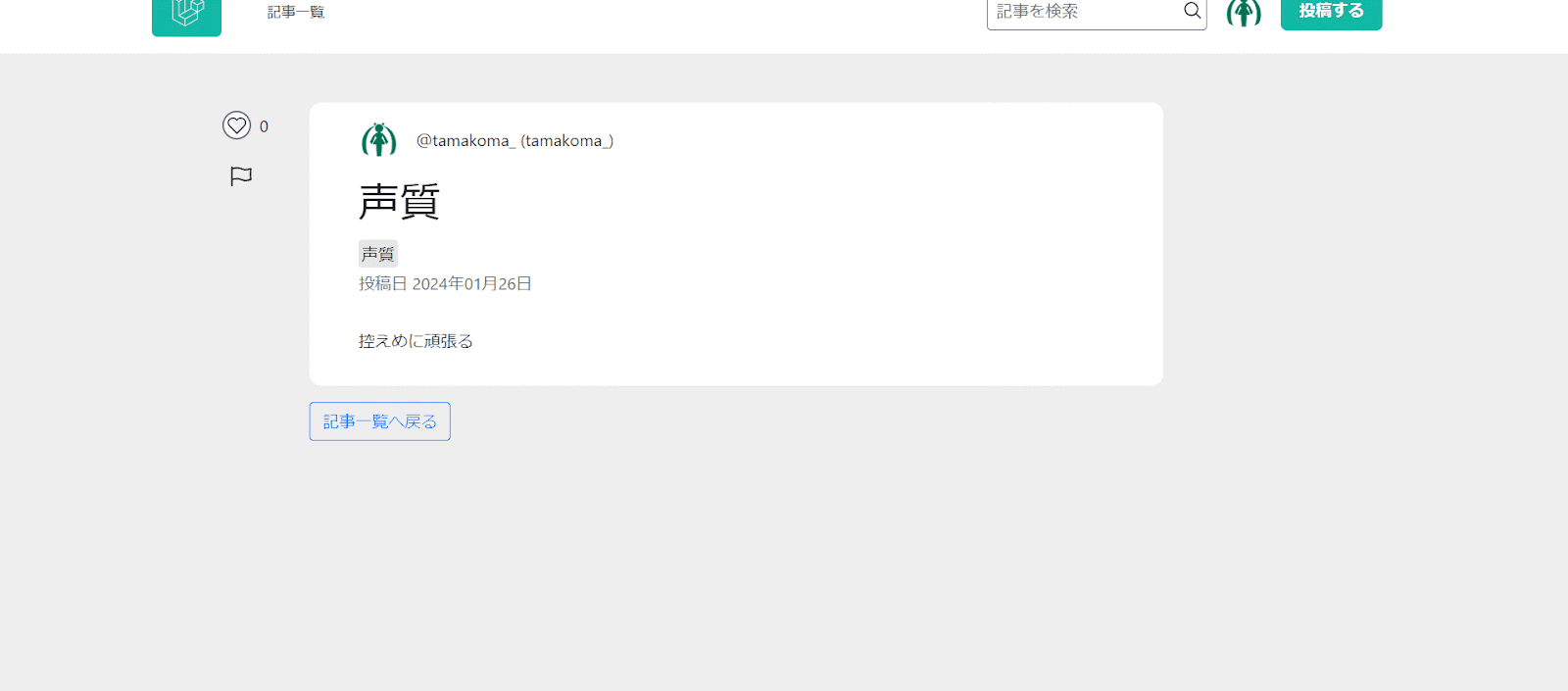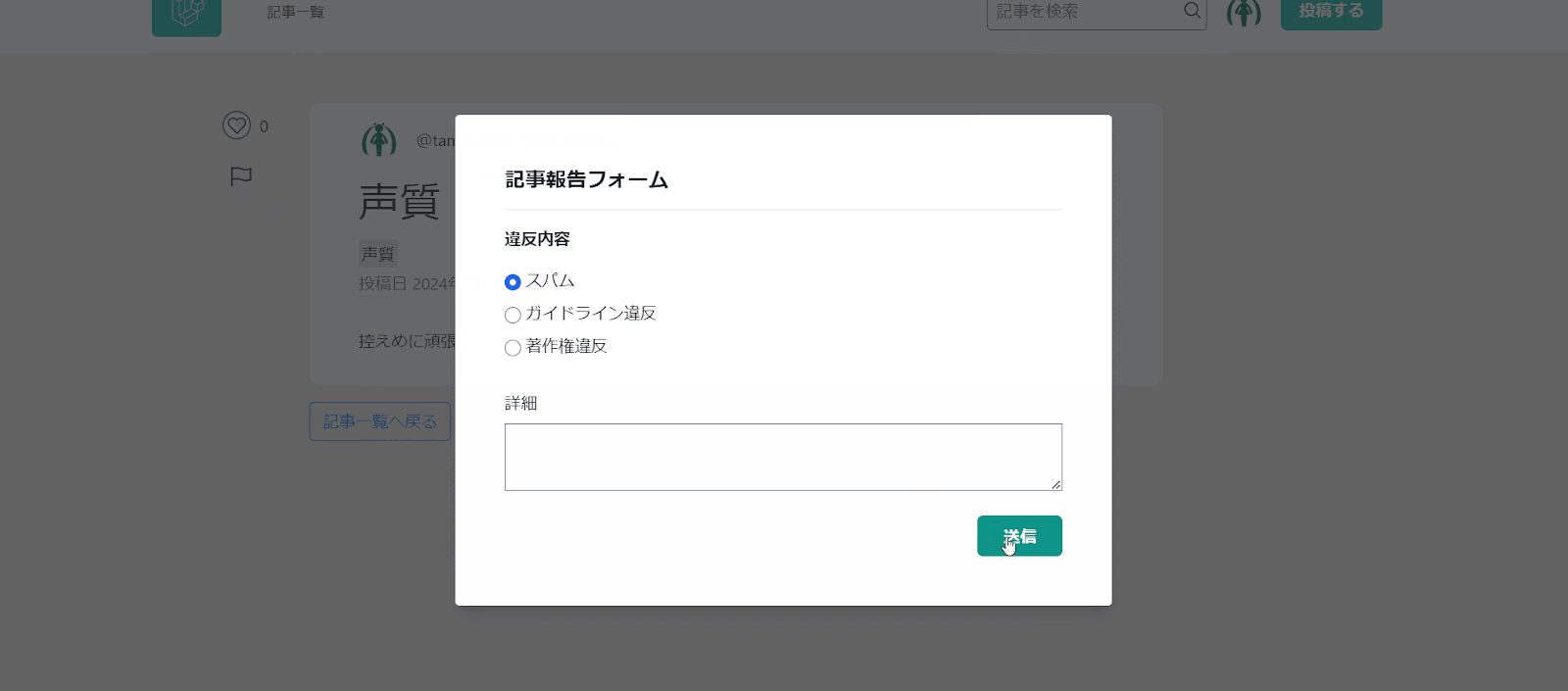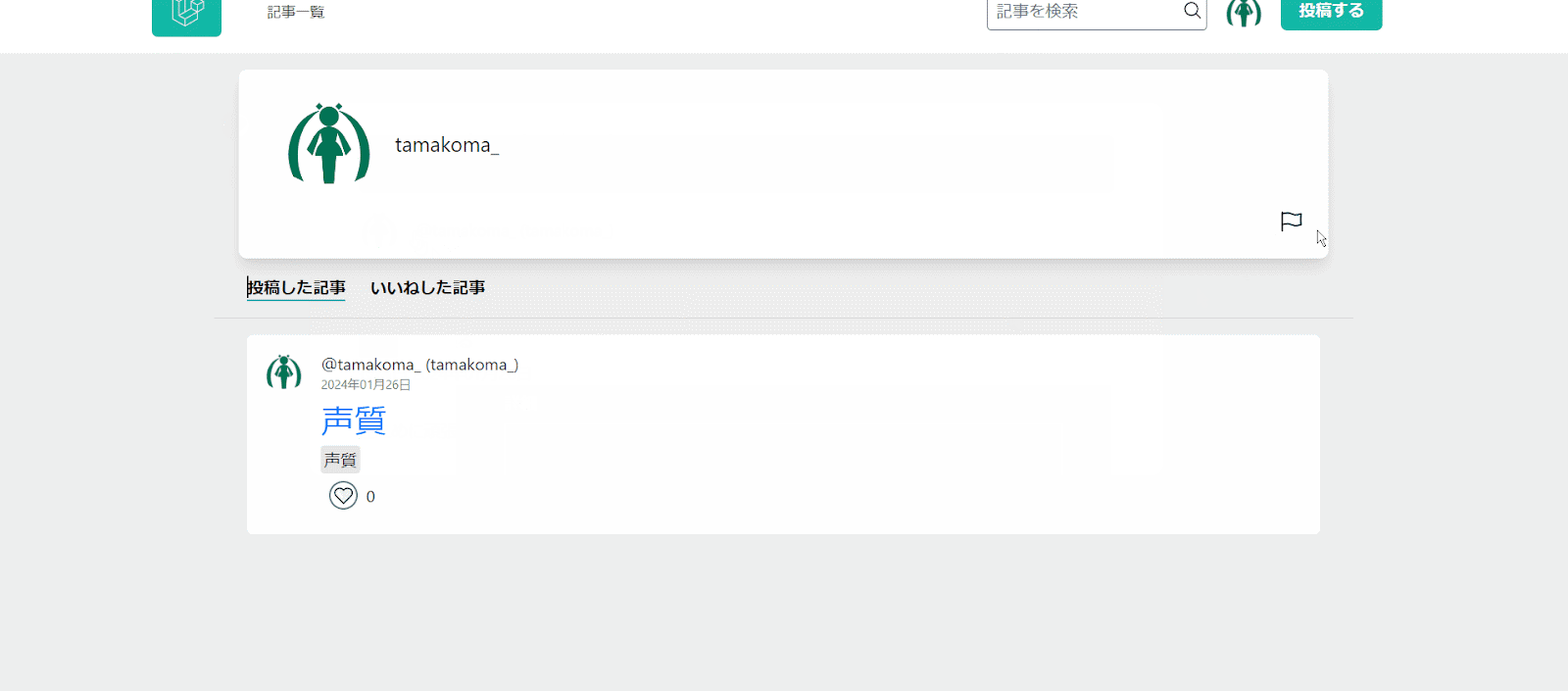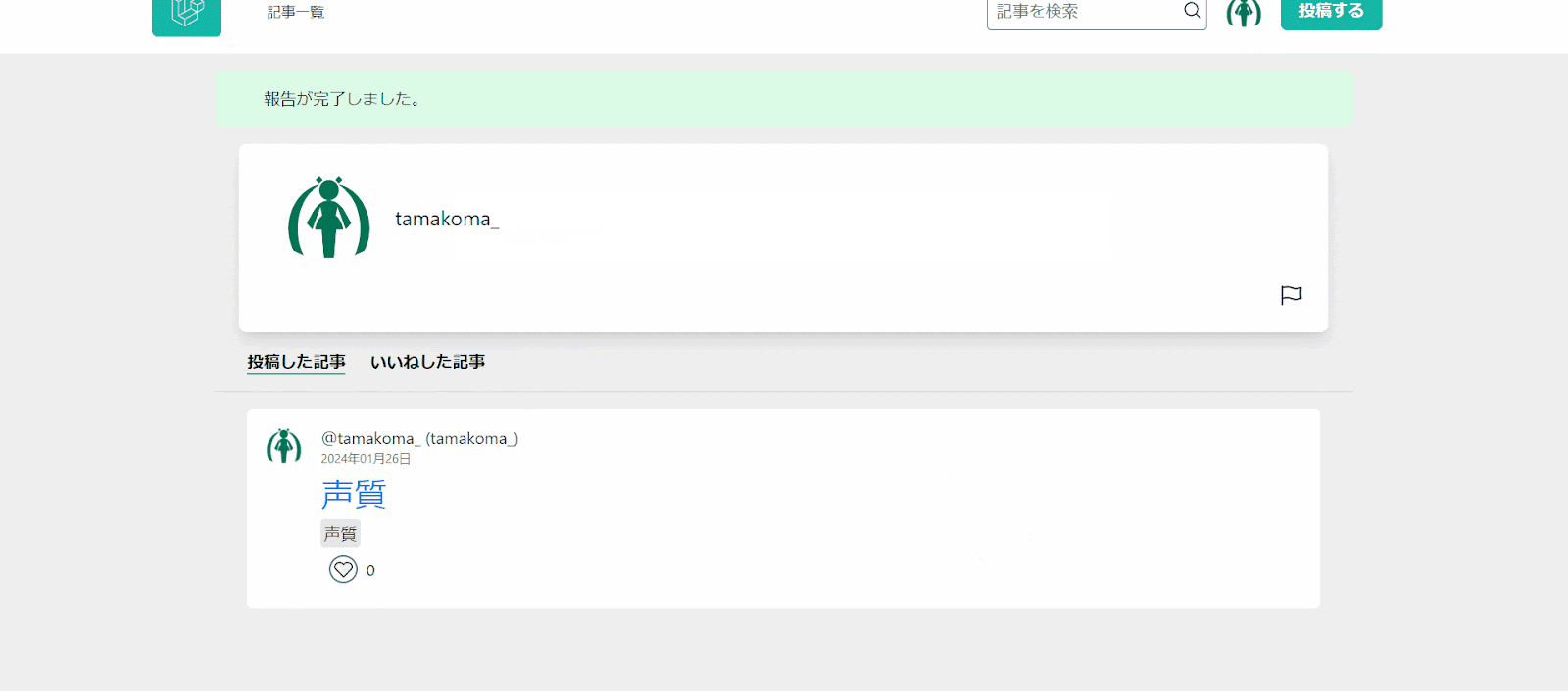
これでDBに報告が溜まるので、その一覧を管理画面で見えるようにして、任意のアクションが出来るようにできればひとまず完成。
ユーザーからの報告を管理する画面を作る
どうやらAdminLTEを使っているなら「Datatables」というプラグインを使うと良い感じにテーブル管理ができそう。
AdminLTEの「Datatable」についてはこちらを。
Datatableの雑感
Datatableはまたそれ単体で独立したライブラリなので、その概念を少し学ぶ必要がある。
本当に雑にだけど、最低限の使い方を残しておく
Dtatableを有効化するには「config/adminlte.php」の
'plugins' => [
'Datatables' => [
'active' => false,にあるactiveをtrueにすればおk。
AdminLTEのBladeViewでDatatableを使うには、以下のようなAdminLTEで定義されたコンポーネントを使う。
<x-adminlte-datatable id="table1" :config="$config" :heads="$heads">
@foreach ($data as $row)
<tr>
@foreach ($row as $cell)
<td>{{ $cell }}</td>
@endforeach
</tr>
@endforeach
</x-adminlte-datatable>コンポーネントに付ける属性は最低以下の3つ。他にもいろいろある。
- id
テーブルを識別するID - config
DatatableのOptionsを指定する配列。
どのようなテーブルにするかの定義みたいな。 - head
テーブル列のヘッダーを配列で定義する場所
そして、定義したコンポーネント内に上例のようにテーブルを作成することでDatatableを扱える。
configとheadに指定する配列なんだけど、以下のように定義できる
$heads = [
'ID',
'Name',
// さらに配列で細かい指定もできる
[
'label' => 'birthday',
'width' => 40 // widthで横幅パーセントを指定できる
]
];
$config = [
'order' => [
// 初期表示時、0番目の列を基準に降順ソート
[0, 'dec']
],
];headの方はあまり細かい指定はできないんだけど、configの方はorder以外にも滅茶苦茶オプションがあるので迷っちゃいそう。
また、この配列をどこに定義するのかというZenn記事もあった。Laravel-AdminLTEでは@phpを使いブレードの中に定義していたし、コントローラに定義してブレードに渡したり、configに定義する等いろいろありそうな感じ。
最後に例として、以下のようなビューを表示してみる
以下の例では、headとconfigを@phpでBlade内に定義してるし、表示データも定義している。
@extends('adminlte::page')
@section('title', 'Datatables')
@section('content_header')
<h1>合成音声DB</h1>
@stop
@php
$heads = [
'ID',
'Name',
// さらに配列で細かい指定もできる
[
'label' => 'birthday',
'width' => 40 // widthで横幅パーセントを指定できる
]
];
$config = [
'order' => [
// 初期表示時、0番目の列を基準に降順ソート
[0, 'dec']
],
];
$data = [
[1, '初音ミク', '8/31'],
[401, '重音テト', '4/1'],
[9, '<script>alert("不正なスクリプトです")</script>', '{!! $cell !!}だと危ないと思う']
];
@endphp
@section('content')
<x-adminlte-datatable id="table1" :config="$config" :heads="$heads">
@foreach ($data as $row)
<tr>
@foreach ($row as $cell)
<td>{{ $cell }}</td>
@endforeach
</tr>
@endforeach
</x-adminlte-datatable>
@stop
@section('css')
@stop
@section('js')
@stopこれをviewで見てみると
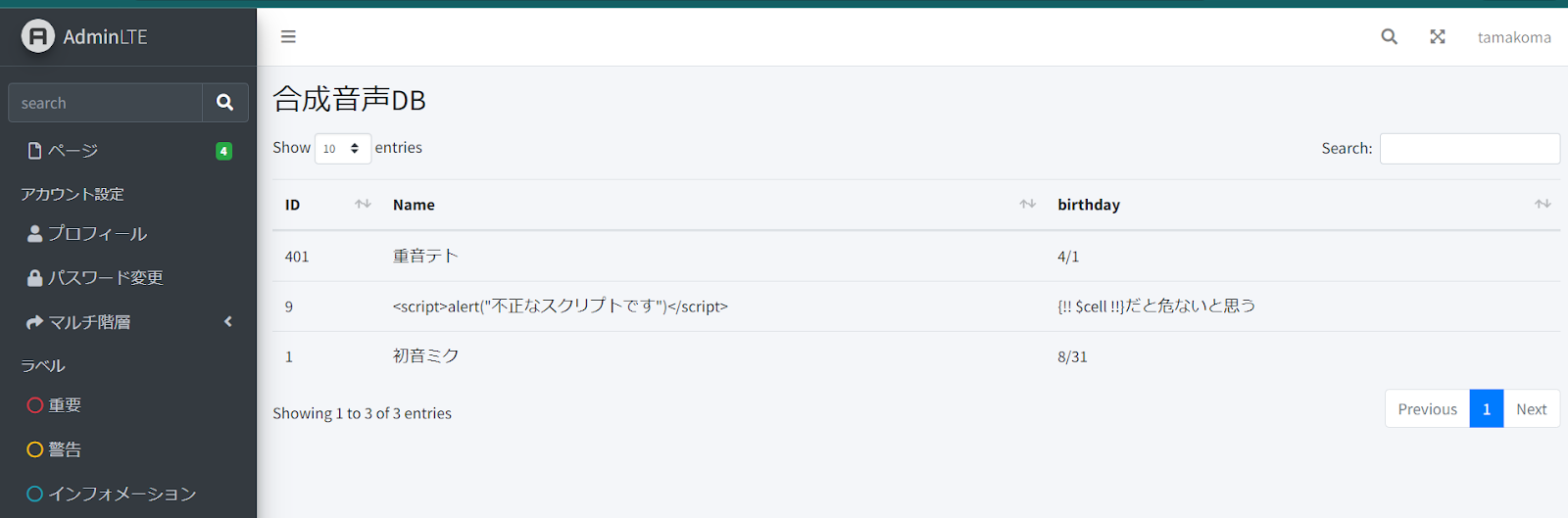
こんな感じで、0番目(ID)を降順にした状態で表示できた。
注意点として、AdminLTEのWikiにある例では「<td>{{ $cell }}</td>」を「<td>{!! $cell !!}</td>」のようにエスケープ処理を外していたんだけど、普通にXSSされるので{{}}で表示推奨。
実際に報告一覧ページを作ってみる
公式ドキュメントによると、5万レコードぐらいにならないならブラウザ処理で問題ないとあるので、今回は処理していないレポートを全部読み込みブラウザ処理に任せる。
結構突貫ではあるけど、以下みたいにしてみた。
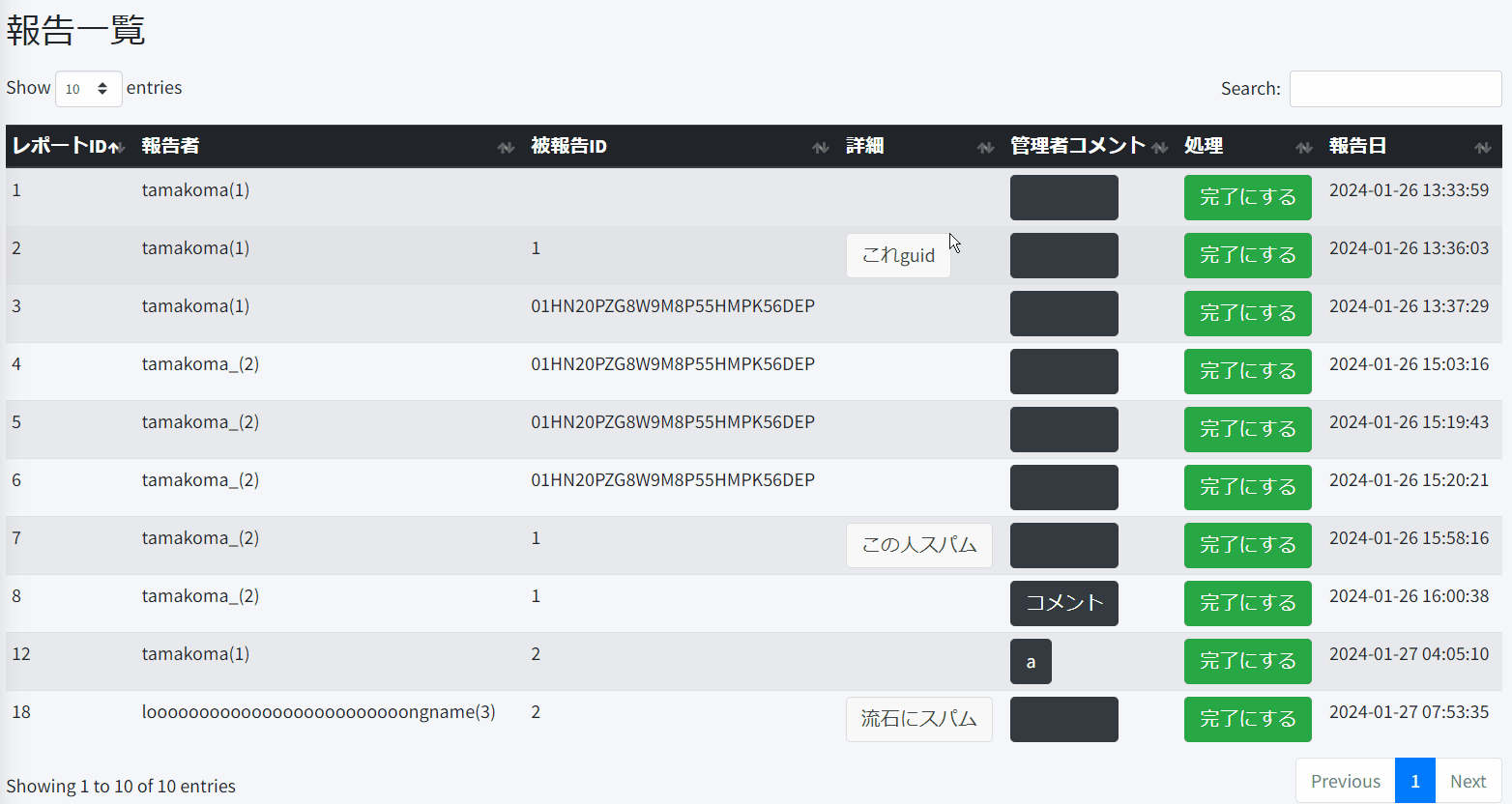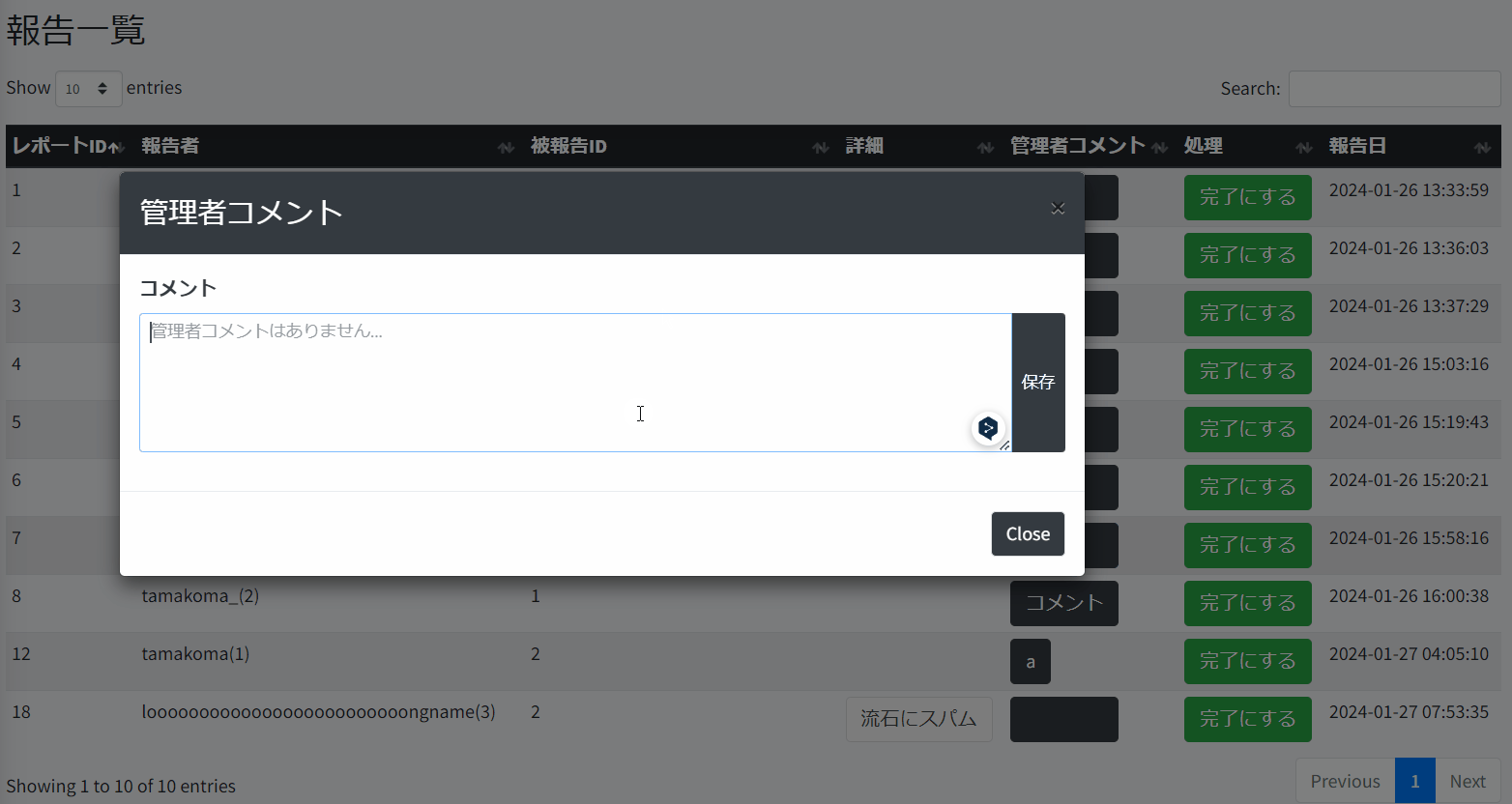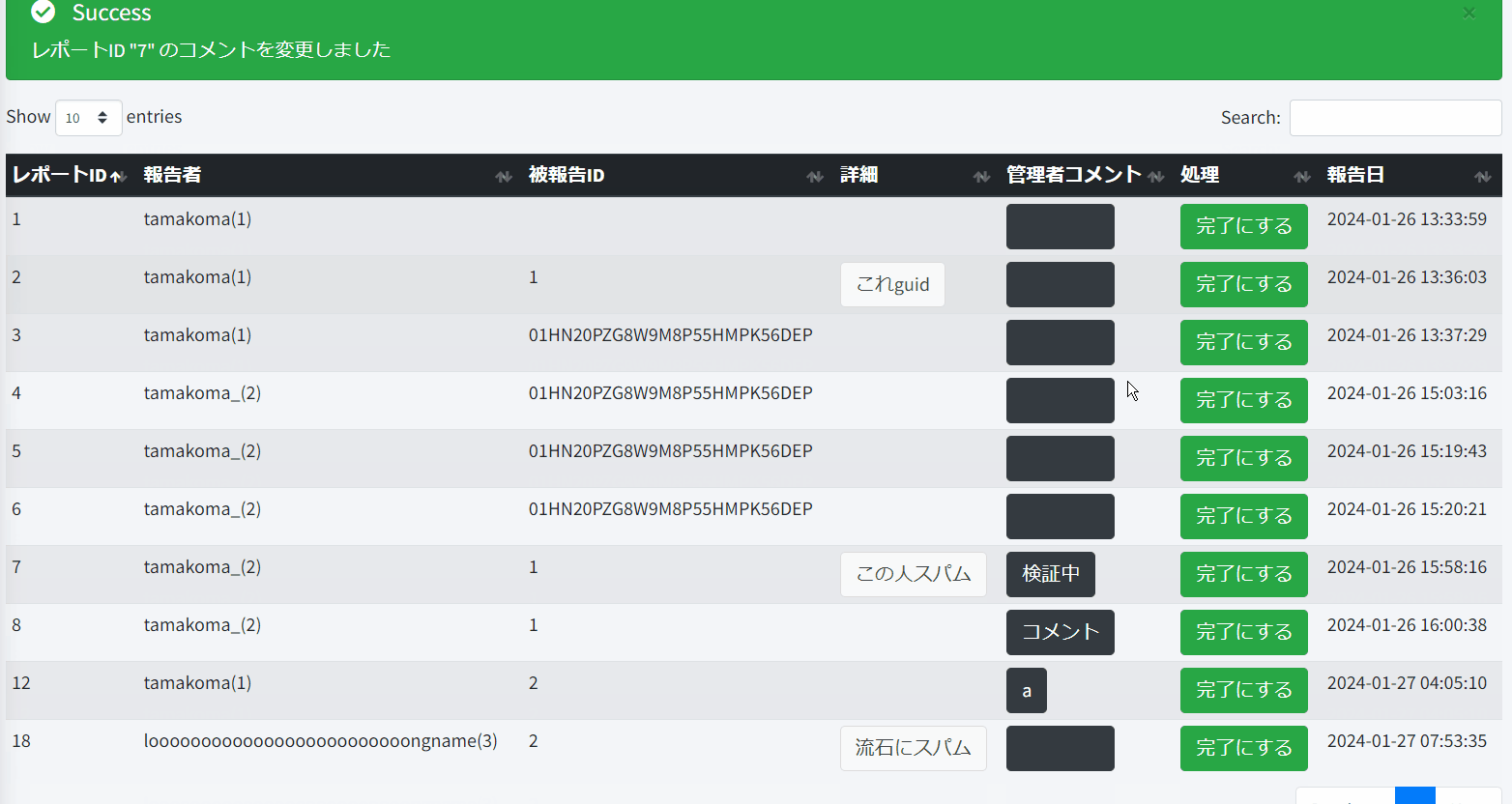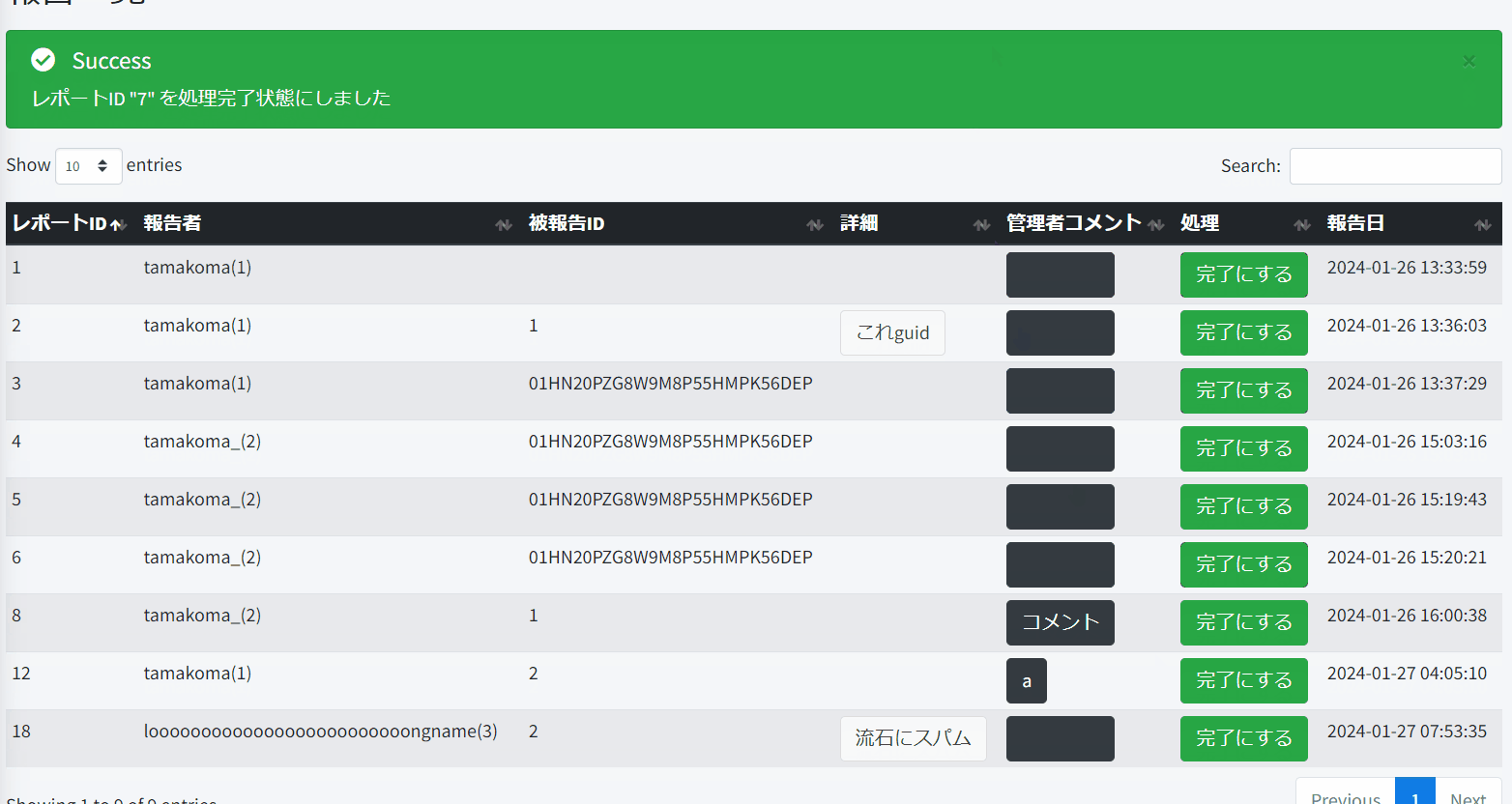
処理するときのボタンが多すぎだったり、記事とユーザーの区別がIDの型というツッコミどころはあるけど、使えなくはないのでとりあえずこれで実装。
BAN方法
このまま本当はユーザー・記事一覧を作ってそこから詳細の閲覧とかBANとかできるようにしたい。
しかし、さらに時間がかかりそうなのでここは簡易的にコマンドからBANできるようにする。
これで十分っちゃ十分だね。

ミスる可能性もあるのでBAN解除のコマンドも作り、最低限完成。
Laravelの表示が遅い理由を探る
つい先日、新しいノートPCが届き開発環境を新しくした。
といっても具体的に変わったことはwindows10→windows11くらいだと思う。
新しい環境で開発をしたいんだけど、
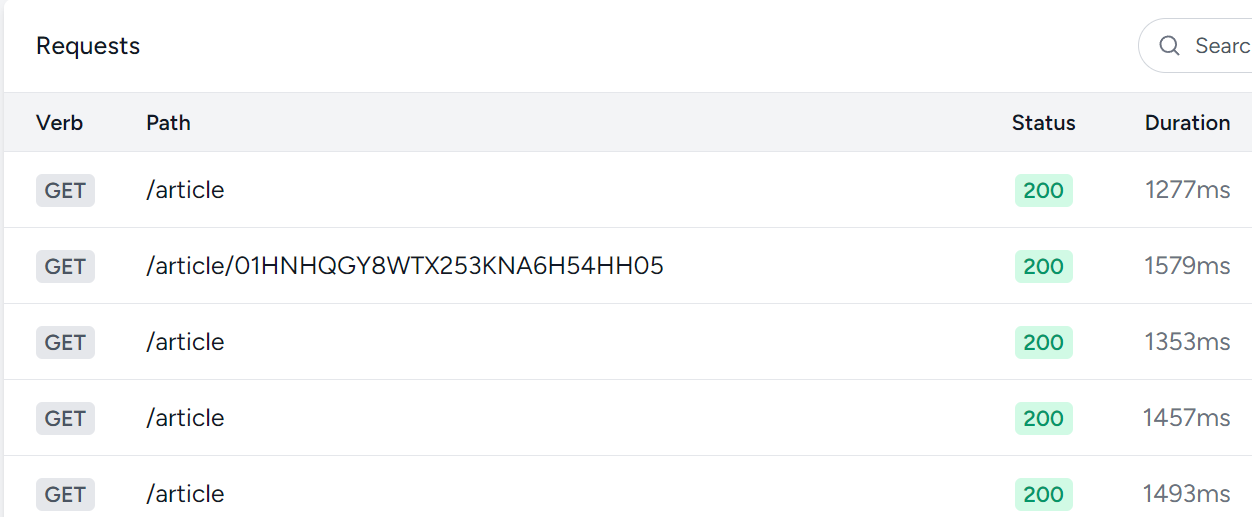
うーん。なぜかページの表示にだいたい1秒以上かかってしまう。前の環境では300msくらい。
新しいノートPCは前のPCよりグレードが低いのでそのせいな可能性もなくは無いんだけど、CPUやメモリの性能は殆ど変わってないはず。
1500msは流石に遅すぎるし、本番環境でもこういう調査はありそうなので、今のうちに慣れておく。
ボトルネックを探す
といっても、探し方がわからないので思いつくところからいろいろ調べながらやる。
Laravelの中身は前の環境からほとんど弄ってないので、Laravelシステムじゃなく他の部分がボトルネックになってるんだと思うんだけどどうだろうか。
デベロッパーツール
ブラウザのせいなのかもしれないので、デベロッパーツールを見てみる。
デベロッパーツールのネットワークタブでレスポンスまでをみてみると、殆どサーバーからのレスポンス待ちなのがわかる。
つまり、ブラウザのせいではなさそう。

Apacheでレスポンスタイムを測る
どうやらApacheにはレスポンスタイムを測る設定があるみたい。
LogFormatディレクティブでログに何を残すか、CustomLogディレクティブでログの保存場所と、どのLogFormatを使って残すかを定義する。
とりあえず以下のようにした。
<VirtualHost *:80>
LogFormat "%h %l %u %t \"%r\" %>s %b %D" QTM
CustomLog logs/access_log QTM
……
</VirtualHost>%DがApacheのレスポンスタイムをマイクロ秒で示すというもので、QTMというLogFormatの名前を付けている。それを、すぐ下のCustomLogで使っているという感じ。
sudo systemctl restart httpd
で再起動もしとく
Apacheのログをfオプションの常時表示で見てみると
sudo tail -f /etc/httpd/logs/access_log
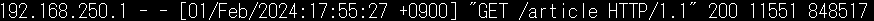
と、848517マイクロ秒≒848msだとわかる。
この時のデベロッパーツールを見ると、

ほぼイコールだね。
そうか、Apacheで測るのはレスポンスがブラウザに届くまでの時間なのか。てっきりApacheでレスポンスを生成するまでの時間かと思っていた。
だとすればデベロッパーツールで見てるのとあんまり変わんないなぁ。
ちなみに、なぜか「sudo systemctl restart httpd」を複数回したらレスポンスまでの時間が半分になった。confの設定を戻してもレスポンスまでの時間は変わらないので理由は不明。なんだこれ。
しかし、800msでもちょっと遅いのでもう少し調べる。
sysstatでサーバーのリソースを調べる
普段Windowsを触っていて動作が重くなったときにまずどこを見るか?
そう、タスクマネージャーである。
それと同様にVMのリソースも見てみる。
どうやらsysstat(System Statistics)というシステムの統計を見れるツールがあるらしいので、これを使う。
sudo dnf install sysstat
でインストール。
インストールしたら
sudo systemctl enable sysstat
sudo systemctl start sysstat
で使えるように
初期状態だと10分ごとにログが「/var/log/sa」に保存もされるみたい。
そして、sarと打つとそのログのCPUのみを参照して表示してくれる。

sar [x秒間隔] [n回]
とやると、コマンドを打ち込んでからx秒間隔にn回、現時点の情報を表示してくれる。これで取得した情報はログに残るわけじゃなさそう。
sar -urd 1 5 –human
とやると、1秒ごとに計5回、CPU、メモリ、ディスクの情報を人間がわかりやすい単位で表示してくれる。
5秒間ブラウザからアクセスしつづけ測ってみた。
5秒間の中で一番CPUの消費が激しいのが以下
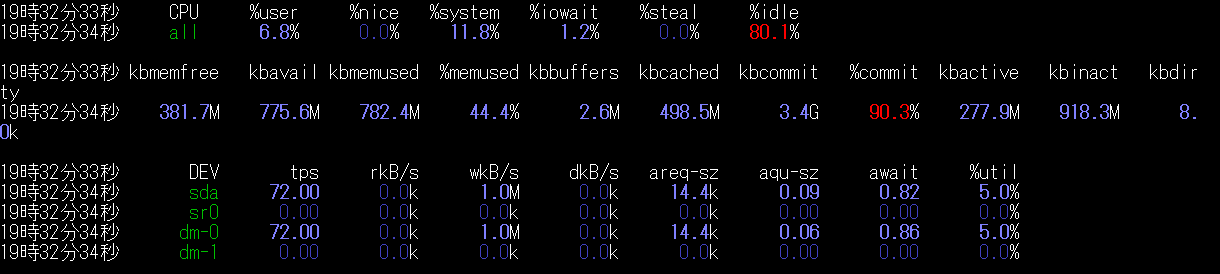
数字が大きいものは赤く表示されるので、この画像で見るべきはCPUの$idleとメモリの%commit。
CPUの%idleは使ってないCPUを示すので、まだまだ余裕がある感じ。
メモリの%commitは90%も使っていて、ここがボトルネック!? と思っちゃうよね。しかし、kbmemfreeを見ればわかる通り381.7Mの余裕があるので別に余裕がないわけではないみたい。
%commitの説明はこちらがわかりやすい。簡潔に言えば%commitはアプリケーションから要求された総メモリ量で、実際に使う総メモリ量ではないみたいなので%が高いからやばいわけではない。
一応VMのメモリを2048MB→4096MBにして速度を測ってみる。

うん、見事に変わらないのでメモリがボトルネックになってるわけではなさそう。
microtimeを使ってLaravel内の処理時間を測る
Laravelのどの部分が時間食ってるのかをmicrotimeを使って見えるようにする。
実はindex.phpの一番初めにdefine(‘LARAVEL_START’, microtime(true));が定義されている。
そのため、好きなところでmicrotime(true) – LARAVEL_STARTを出力すればそこまでの経過時間を取得できるはず。
今回は
error_log(“グローバルミドルウェアの処理終了”.microtime(true) – LARAVEL_START.”\n”,3,”/media/sf_Share/QTM/storage/logs/laravel.log”);
のようにしてみた。
error_logを使う理由は、Laravelを読み込む前にもログを出力したいから。
試しにグローバルミドルウェアの最後とコントローラの始まりと終わりの経過時間を出力してみる。

グローバルミドルウェアの処理が終わった時点で約1秒が経過している。つまり、初期設定時に何か問題がありそう。
これ、Laravelの中身を可視化するのに結構面白いので、もっと細かく入れてみる。

うん、単純に全体的に遅い。でも、やっぱり特にグローバルミドルウェアの完了までが遅いなぁという感じ。
グローバルミドルウェアの処理を計測してみる。

Debugミドルウェアを作りDebugミドルウェアを一番最初の処理にしたけど、グローバルミドルウェアの処理自体はそこまで時間かかってなさそう。
サービスプロバイダを見てみる。
日本語ドキュメントによると「bootメソッドは、他の全サービスプロバイダが登録し終えてから呼び出されます」とのことなので、Appサービスプロバイダのregisterを始まりに、bootを終わりにしてみた。
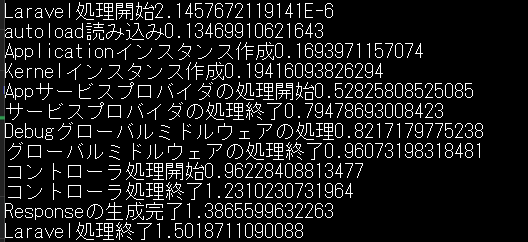
Appサービスプロバイダの前にIlluminateで定義されたサービスプロバイダが大量にあるので、それを考えると妥当な時間な感じがするなぁ。
つまり、どこかが突出して遅いのではなく、普通に全部遅い。
というかなんで800msから1500msに戻ったのかもわからないのよね。
VM自体になにかしら問題があって処理速度が遅くなってるのかなぁ。
旧VMの環境と比較する
VMはエクスポートすることでそのまま持ってこれるので、旧PCのVMを新PCに持ってくる。
エクスポートは「仮想アプライアンスのエクスポート」から行い、新PCでインポートを行う。
ネットや共有フォルダの設定を行えばとりあえず起動はするはず。
これで遅かったら新PC依存の問題だよね。
2個にVMを起動して比較してみた。
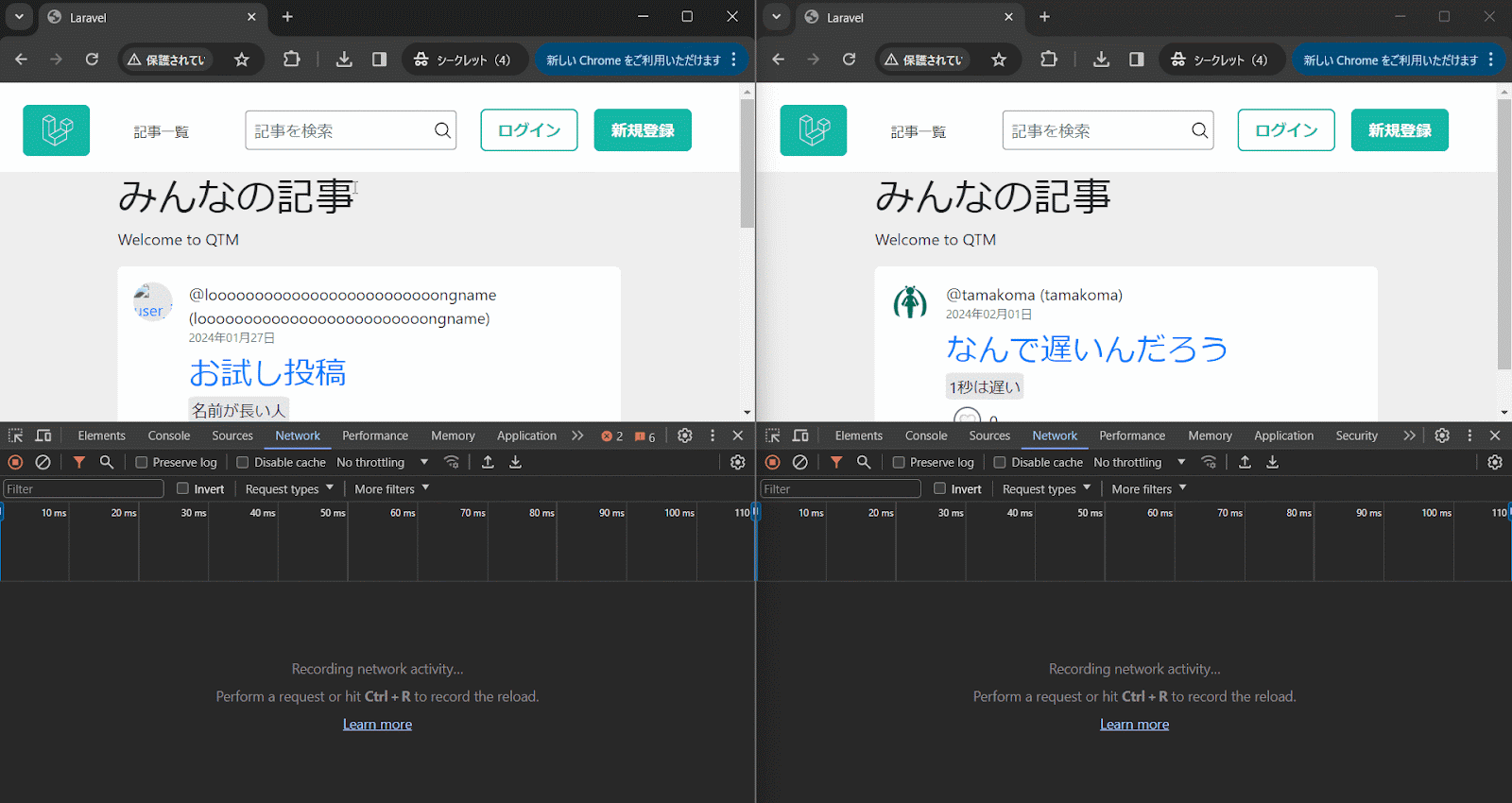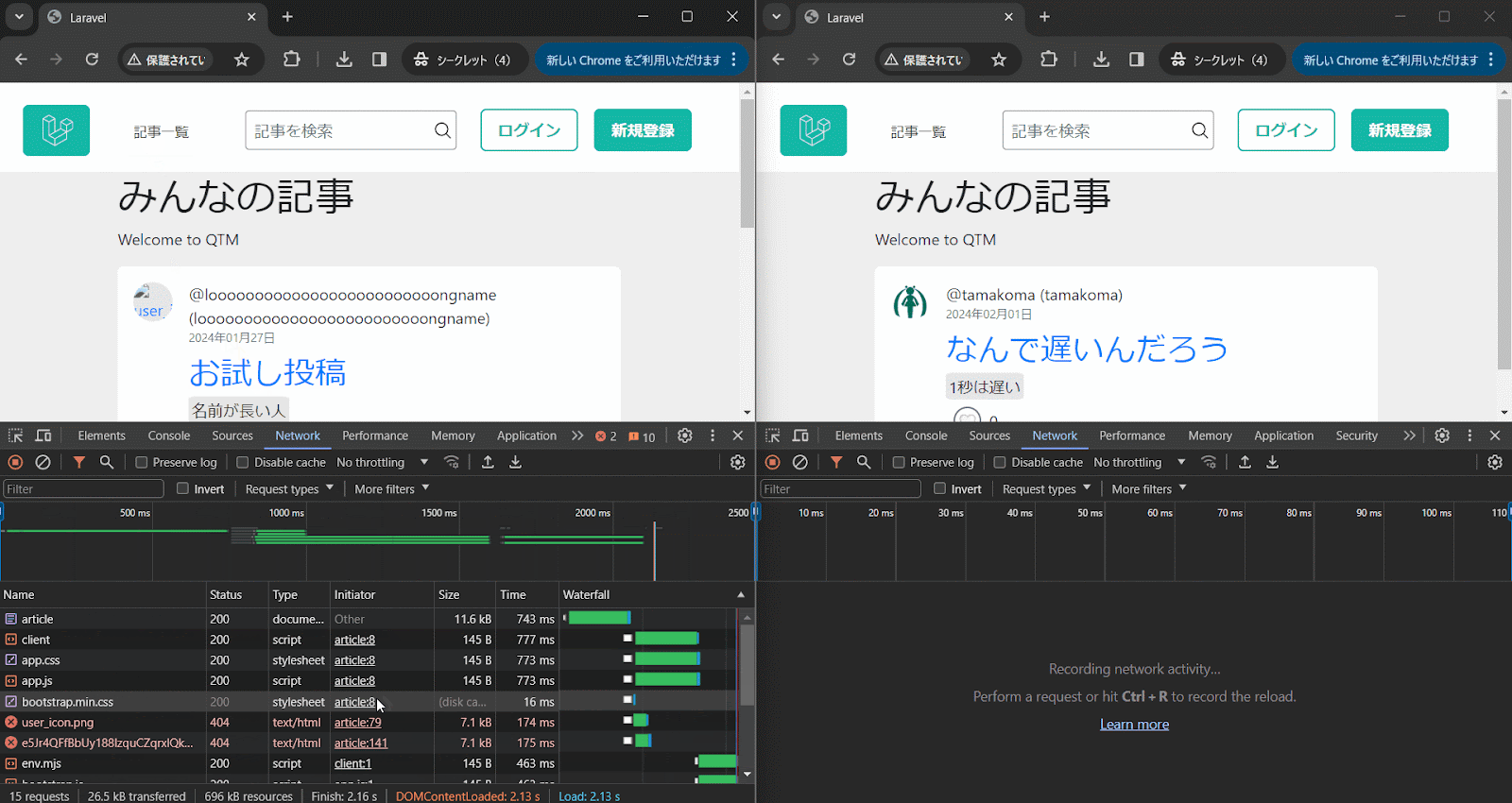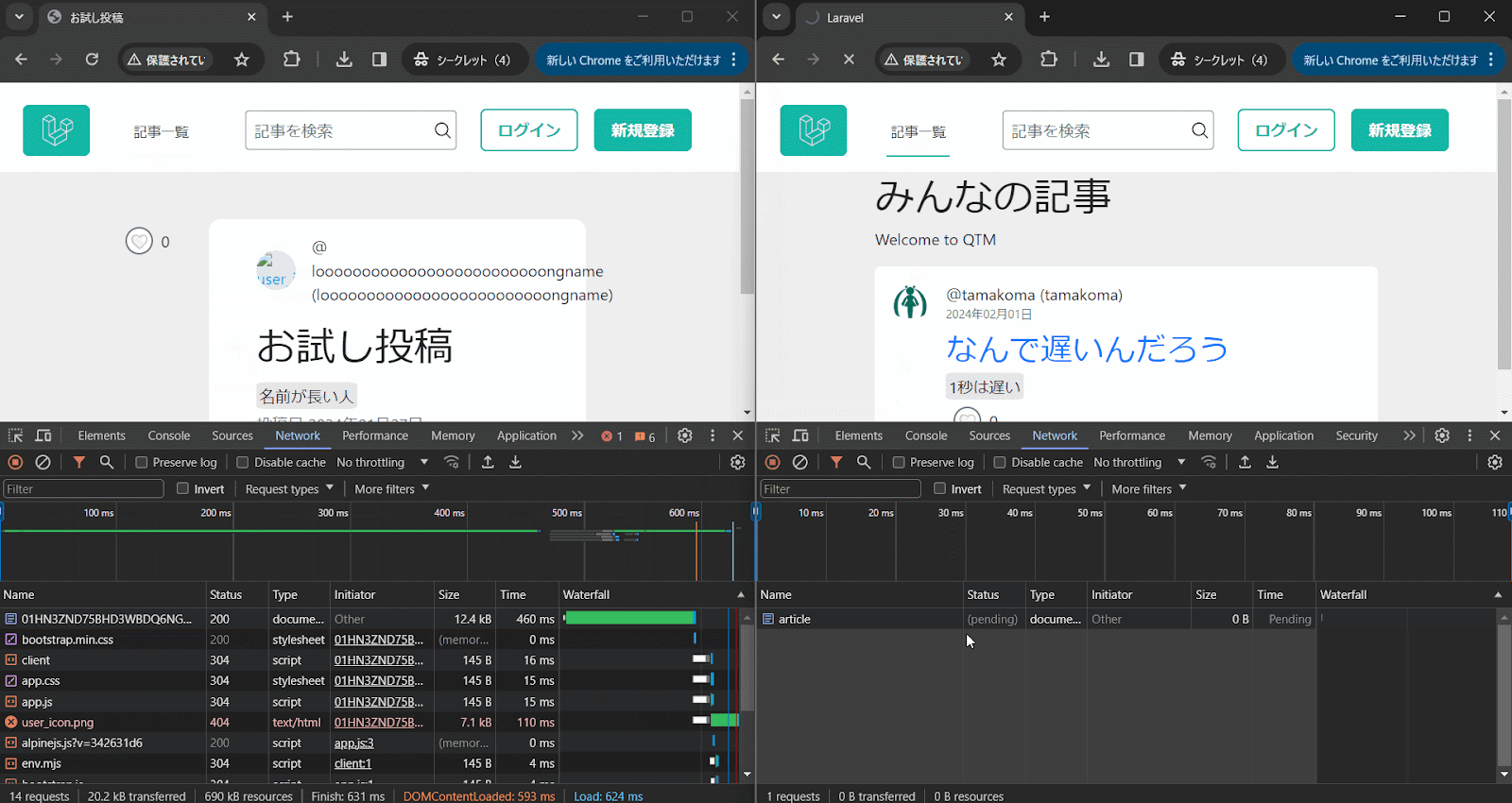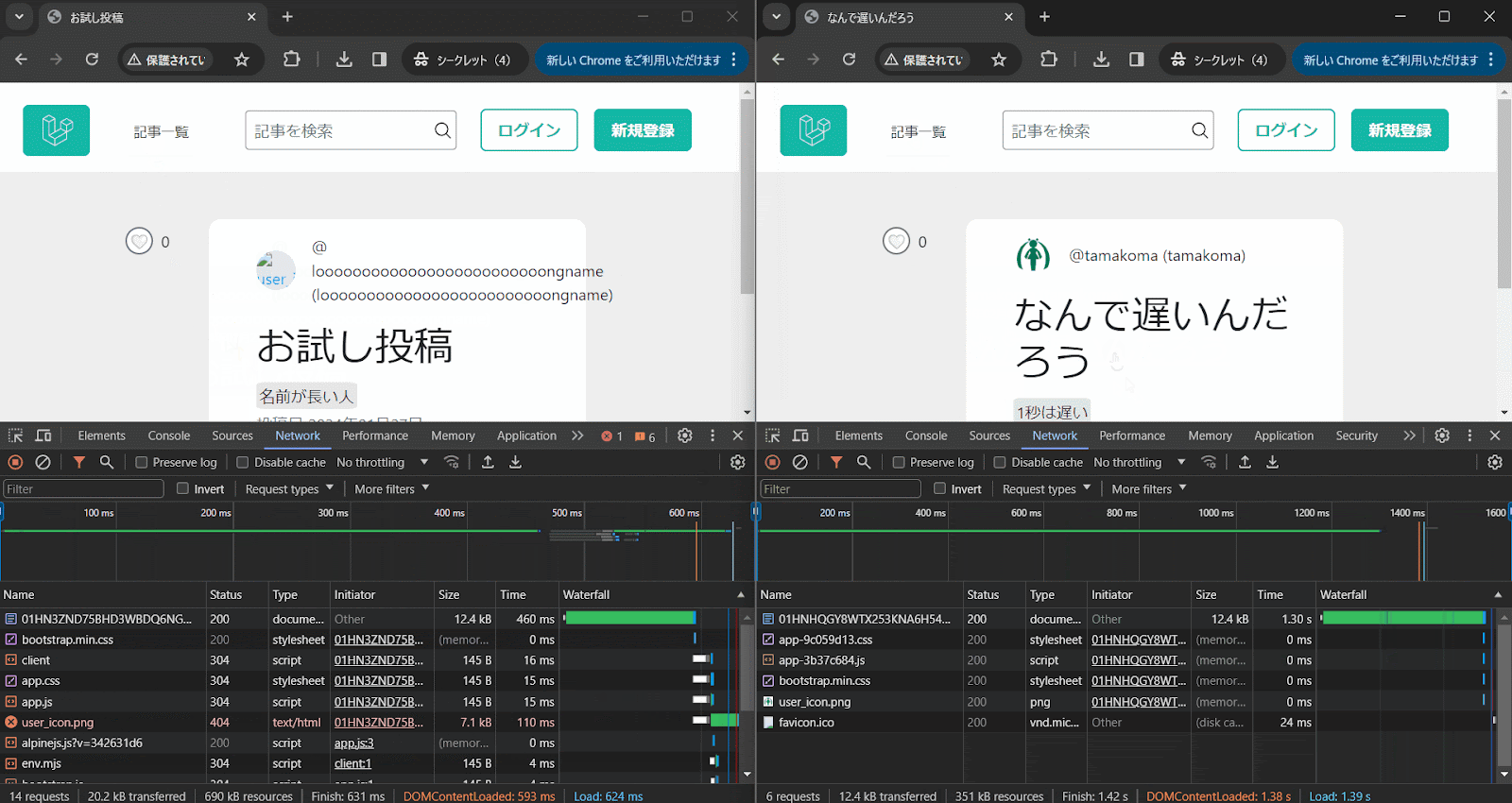
うん、なんか旧VMもちょっと遅いけど新VM環境のほうが2倍以上遅いね。
だとすればVMの中で何か問題があって遅くなってる?
せっかく旧VMのLaravelプロジェクトをそのまま新VMに移したらどうなるだろうか。
結果、更に遅くなった。わけわからぬ。
Blackfireを使ってみる
BlackfireというPHP系のパフォーマンスを測ってくれるサービスがあるらしい。
個人利用は無料っぽいので使ってみる。
インストール方法は公式サイトを見てもらうのが一番良いと思う。めっちゃわかりやすく教えてくれる。
インストール後にapacheとfpmを再起動する必要があるので注意。
sudo systemctl restart httpd
systemctl restart php-fpm.service
旧VMと新VMどっちにもインストールし、計ってみる。
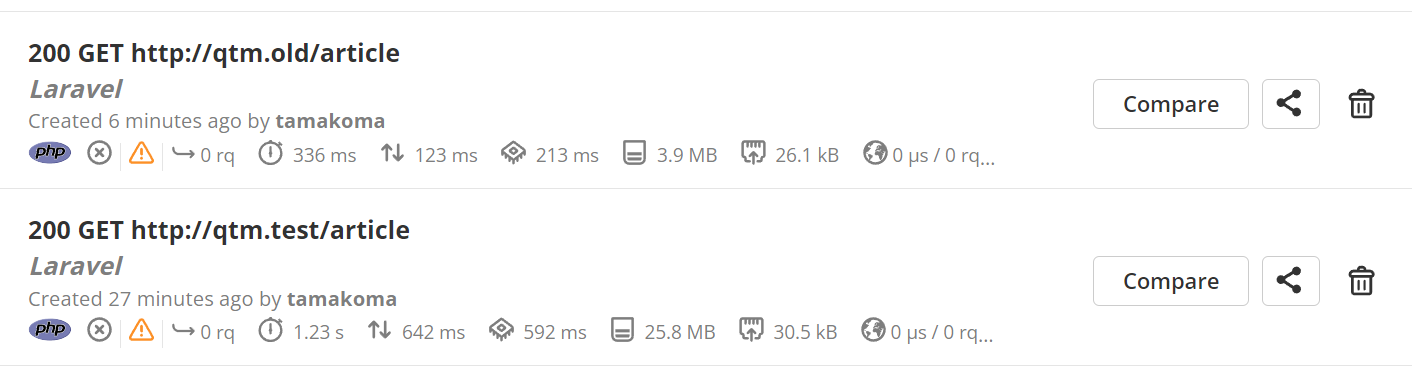
上のqtm.oldが旧VMのLaravelで、下のqtm.testが新VMのLaravel。
なんとCompareできるみたいなので、比較する。これ冷静に考えて比較できるのすごくない?

驚異の赤さ。左から「Time、I/O Wait、CPU、Peak Memory、Network」を意味してるんだけど、全てが悪い。
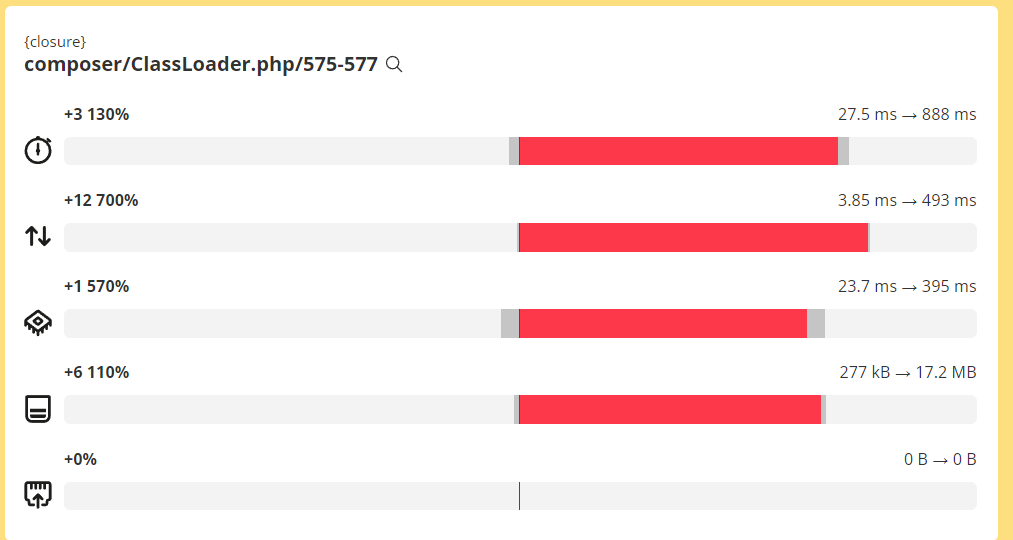
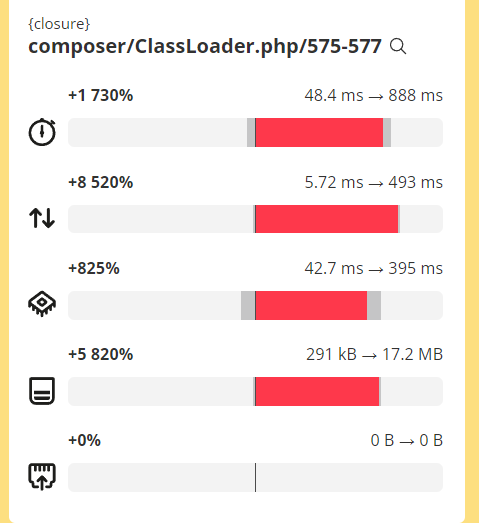
また、グラフを見てみるとcomposer/ClassLoaderの部分がハイパーインフレしてた。
ここが問題っぽい?
正直composerのオートローダーの仕組みとか全然理解できてないんだけど、それ関連で遅くなってる?
オートローダーの最適化をしてくれるコマンドを打ち込んでみる。
composer dump-autoload –optimize
うん、あんま変わんない。
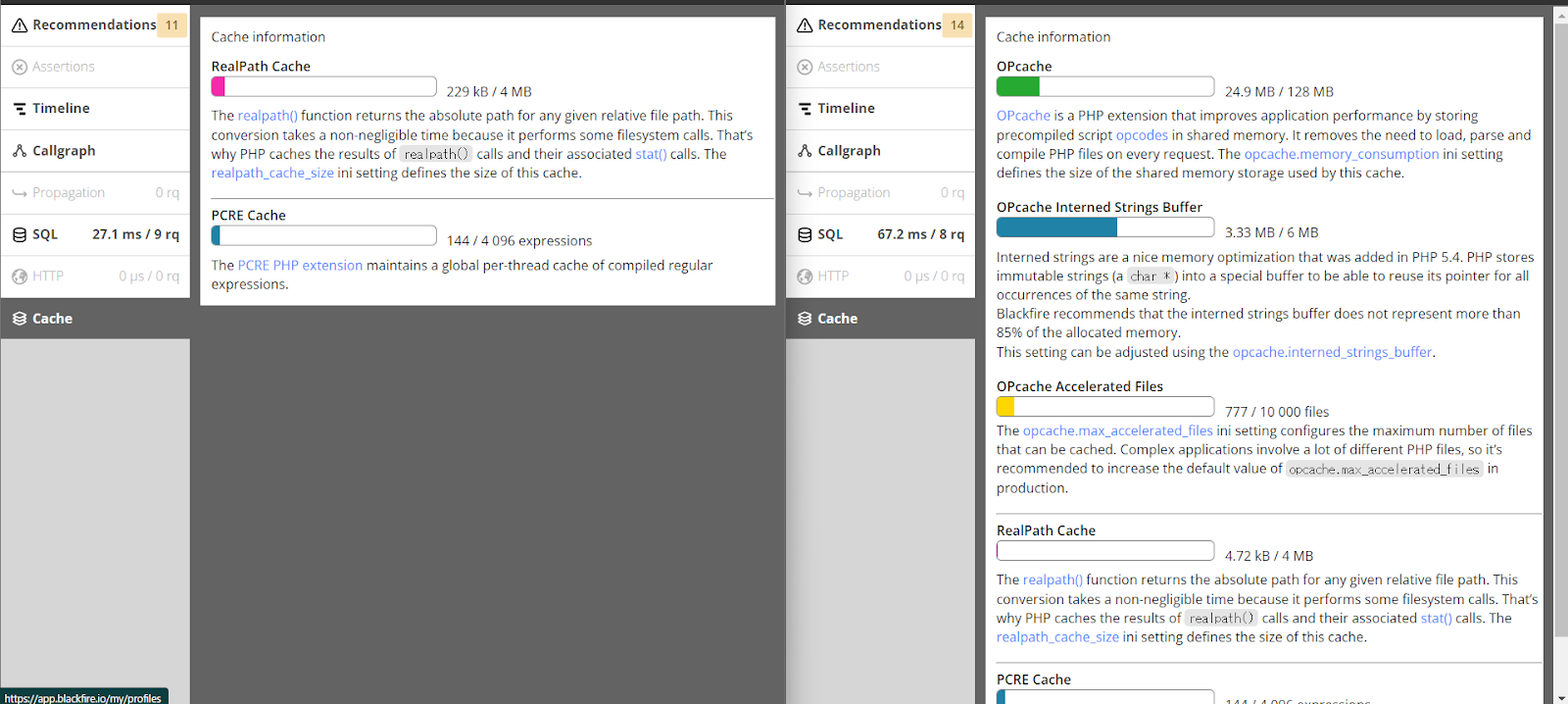
いろいろ見ていたら気になるところが、
これ、左が新VMのCacheで右が旧VMのCache。
なんか旧VMにはOPcacheなるものが入っているのがわかる。
なんだこれ、全然入れた覚えないんだけど。
解決
試しに新VMにもOPcacheを入れてみよう。
sudo dnf install php-opcache
OPcacheの設定ファイルは「/etc/php.d/10-opcache.ini」にあるけど、初期で有効化されてるっぽい。

入れ終わったらapachetとfpmの再起動。
sudo systemctl restart httpd
systemctl restart php-fpm.service
Blackfireをみてみると……

マジで天才!
TelescopeのDurationも超綺麗。
素晴らしいレスポンス速度。
ありがとうOPcache、ありがとうBlackfire。
OPcacheを理解する
同じ轍を踏まないようOPcacheを理解しよう。
公式ドキュメントはこちら。
公式ドキュメントには
OPcache はコンパイル済みのバイトコードを共有メモリに保存し、PHP がリクエストのたびにスクリプトを読み込み、パースする手間を省くことでパフォーマンスを向上させます。
https://www.php.net/manual/ja/book.opcache.php
とある。
つまり、コンパイルしたPHPを予め共有メモリに保存し使いまわすということ。
共有メモリはいろんなプロセスが使えるメモリのことらしい。今回は重要じゃないのでこの程度で。
だから、初めてのアクセスは全てのPHPファイルをコンパイルしているので遅いけど、2回目以降は速いってことらしい。
OPcacheを使わないときにcomposer/ClassLoaderが極端に遅かったのは、”ClassLoader”という名前の通り、Laravelで使うクラスを全て読み込む部分でコンパイルする量が凄まじかったからなんだと思う。
その為、全てコンパイルしなおすとそこだけで888msくらいかかっちゃうけど、OPcacheがあれば2回目以降は27msくらいで読み込めると。
また、全体的に遅かったことにも頷ける。
そんな素晴らしい技術を使ってなかったので極端に遅かったのね。
まあまあ時間かかったけど、いろんなデバッグ方法を知れたのでヨシ。
もう1か月経ったので一旦ここで区切り。
おわりに
ちょっと時間がかかりすぎなので、2月中の簡易リリースを目標に進める。
これくらい長くなると、WordPressのwysiwygエディタが重すぎるのでもう少し短くも目指す。
終わり

